 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Enhances Listening: Recovering Missing Speech Using Images
Feb 13, 2020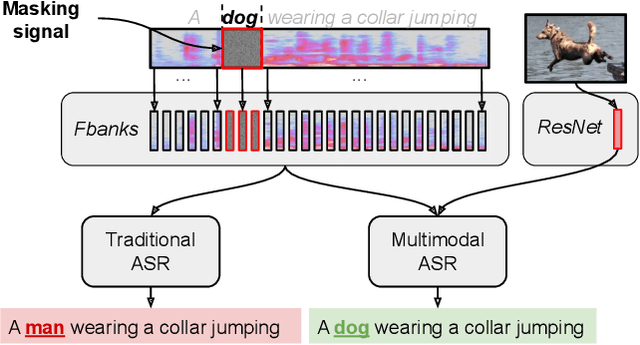
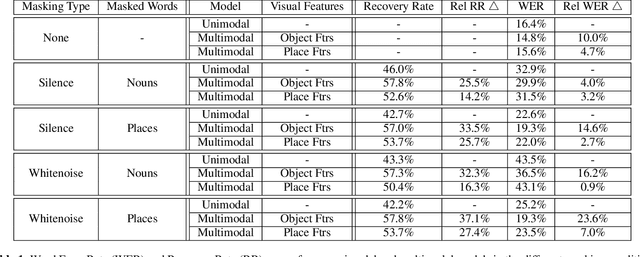
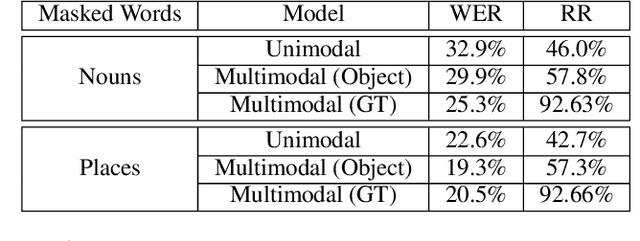

Speech is understood better by using visual context; for this reason, there have been many attempts to use images to adapt automatic speech recognition (ASR) systems. Current work, however, has shown that visually adapted ASR models only use images as a regularization signal, while completely ignoring their semantic content. In this paper, we present a set of experiments where we show the utility of the visual modality under noisy conditions. Our results show that multimodal ASR models can recover words which are masked in the input acoustic signal, by grounding its transcriptions using the visual representations. We observe that integrating visual context can result in up to 35% relative improvement in masked word recovery. These results demonstrate that end-to-end multimodal ASR systems can become more robust to noise by leveraging the visual context.
Multitask Learning For Different Subword Segmentations In Neural Machine Translation
Oct 27, 2019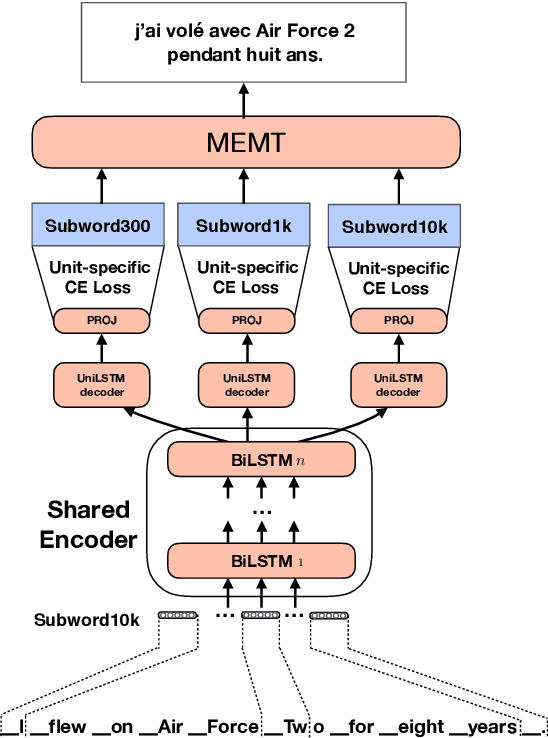
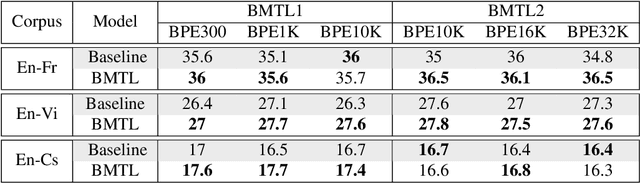
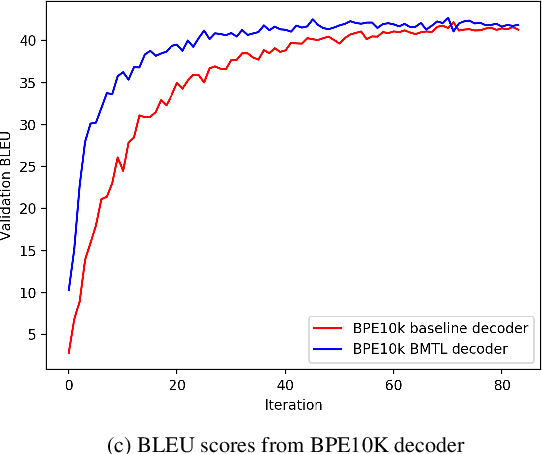
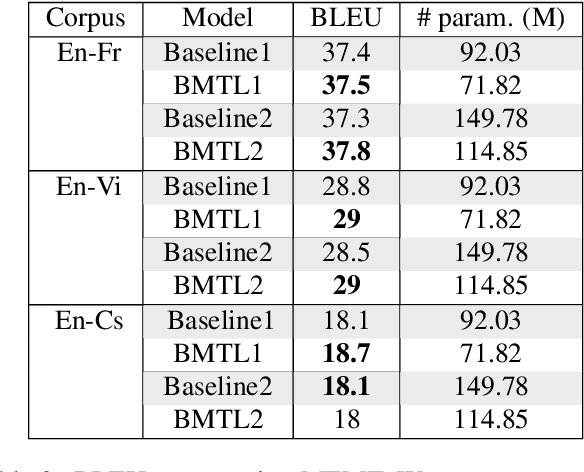
In Neural Machine Translation (NMT) the usage of subwords and characters as source and target units offers a simple and flexible solution for translation of rare and unseen words. However, selecting the optimal subword segmentation involves a trade-off between expressiveness and flexibility, and is language and dataset-dependent. We present Block Multitask Learning (BMTL), a novel NMT architecture that predicts multiple targets of different granularities simultaneously, removing the need to search for the optimal segmentation strategy. Our multi-task model exhibits improvements of up to 1.7 BLEU points on each decoder over single-task baseline models with the same number of parameters on datasets from two language pairs of IWSLT15 and one from IWSLT19. The multiple hypotheses generated at different granularities can be combined as a post-processing step to give better translations, which improves over hypothesis combination from baseline models while using substantially fewer parameters.
Analyzing Utility of Visual Context in Multimodal Speech Recognition Under Noisy Conditions
Jun 30, 2019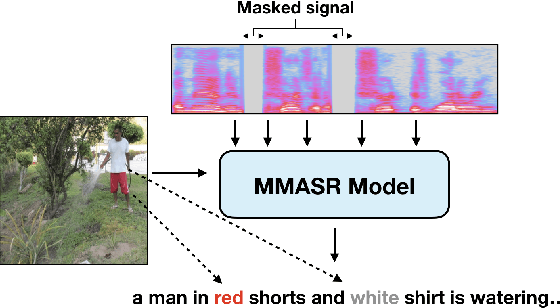

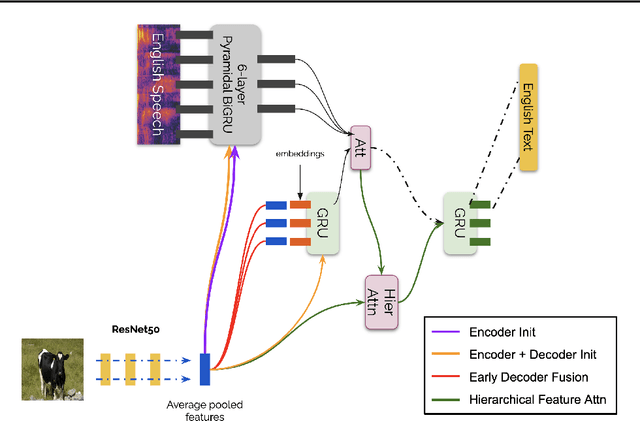
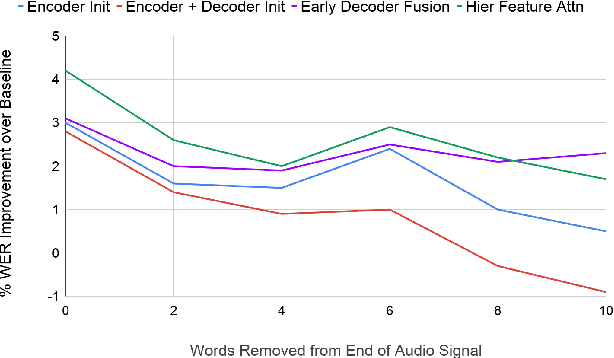
Multimodal learning allows us to leverage information from multiple sources (visual, acoustic and text), similar to our experience of the real world. However, it is currently unclear to what extent auxiliary modalities improve performance over unimodal models, and under what circumstances the auxiliary modalities are useful. We examine the utility of the auxiliary visual context in Multimodal Automatic Speech Recognition in adversarial settings, where we deprive the models from partial audio signal during inference time. Our experiments show that while MMASR models show significant gains over traditional speech-to-text architectures (upto 4.2% WER improvements), they do not incorporate visual information when the audio signal has been corrupted. This shows that current methods of integrating the visual modality do not improve model robustness to noise, and we need better visually grounded adaptation techniques.
Multimodal Grounding for Sequence-to-Sequence Speech Recognition
Nov 09, 2018
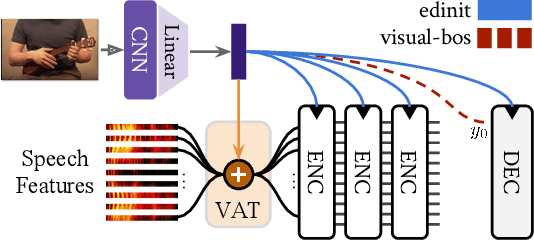
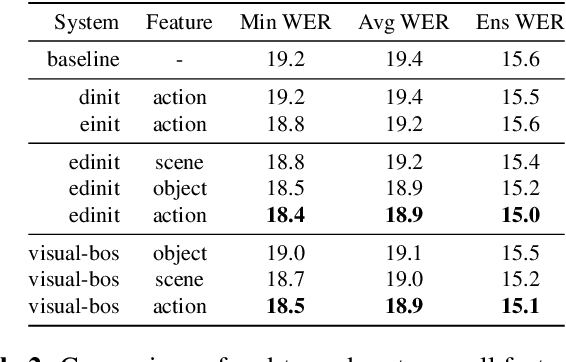
Humans are capable of processing speech by making use of multiple sensory modalities. For example, the environment where a conversation takes place generally provides semantic and/or acoustic context that helps us to resolve ambiguities or to recall named entities. Motivated by this, there have been many works studying the integration of visual information into the speech recognition pipeline. Specifically, in our previous work, we propose a multistep visual adaptive training approach which improves the accuracy of an audio-based Automatic Speech Recognition (ASR) system. This approach, however, is not end-to-end as it requires fine-tuning the whole model with an adaptation layer. In this paper, we propose novel end-to-end multimodal ASR systems and compare them to the adaptive approach by using a range of visual representations obtained from state-of-the-art convolutional neural networks. We show that adaptive training is effective for S2S models leading to an absolute improvement of 1.4% in word error rate. As for the end-to-end systems, although they perform better than baseline, the improvements are slightly less than adaptive training, 0.8 absolute WER reduction in single-best models. Using ensemble decoding, end-to-end models reach a WER of 15% which is the lowest score among all systems.
How2: A Large-scale Dataset for Multimodal Language Understanding
Nov 01, 2018
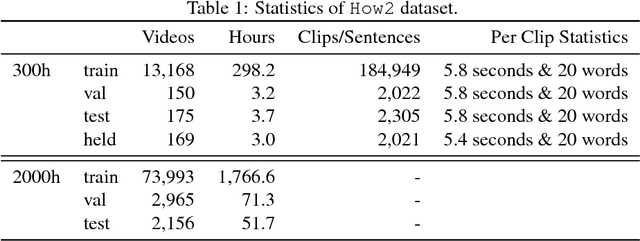
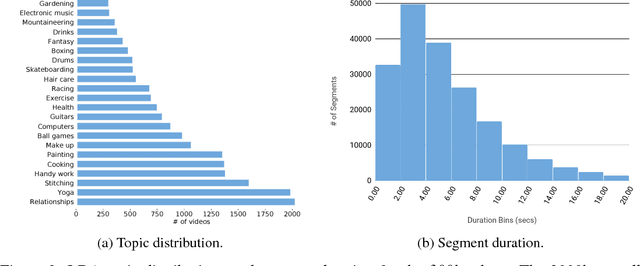

In this paper, we introduce How2, a multimodal collection of instructional videos with English subtitles and crowdsourced Portuguese translations. We also present integrated sequence-to-sequence baselines for machine translation, automatic speech recognition, spoken language translation, and multimodal summarization. By making available data and code for several multimodal natural language tasks, we hope to stimulate more research on these and similar challenges, to obtain a deeper understanding of multimodality in language processing.
Hierarchical Multi Task Learning With CTC
Jul 25, 2018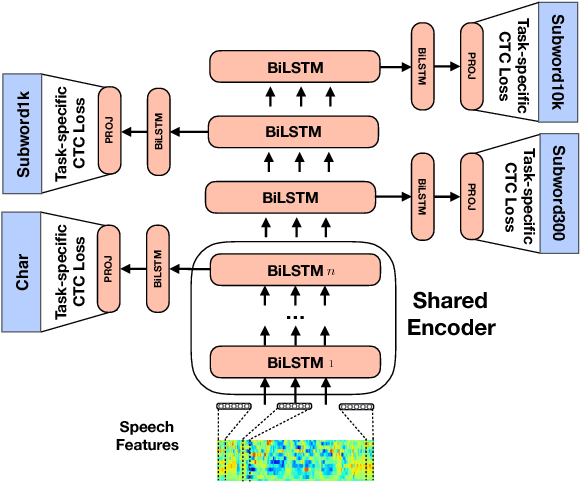


In Automatic Speech Recognition it is still challenging to learn useful intermediate representations when using high-level (or abstract) target units such as words. For that reason, character or phoneme based systems tend to outperform word-based systems when just few hundreds of hours of training data are being used. In this paper, we first show how hierarchical multi-task training can encourage the formation of useful intermediate representations. We achieve this by performing Connectionist Temporal Classification at different levels of the network with targets of different granularity. Our model thus performs predictions in multiple scales for the same input. On the standard 300h Switchboard training setup, our hierarchical multi-task architecture exhibits improvements over single-task architectures with the same number of parameters. Our model obtains 14.0% Word Error Rate on the Eval2000 Switchboard subset without any decoder or language model, outperforming the current state-of-the-art on acoustic-to-word models.
Subword and Crossword Units for CTC Acoustic Models
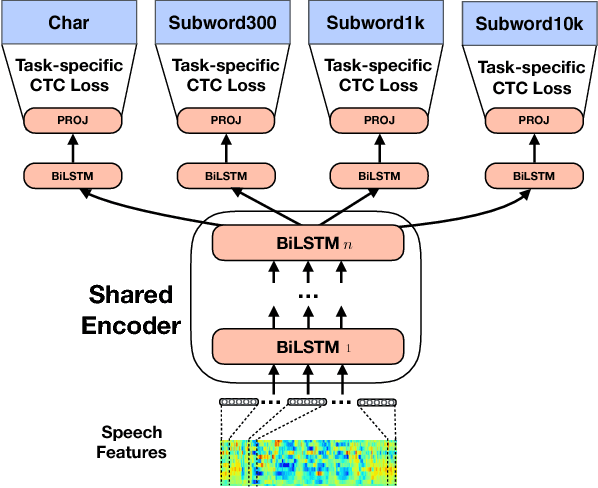
Jun 18, 2018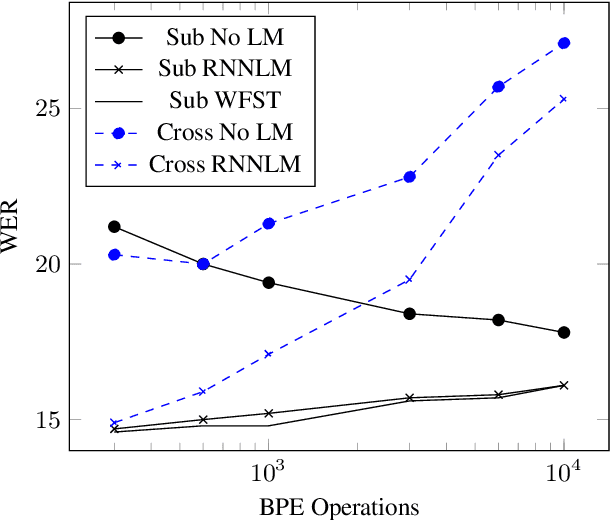
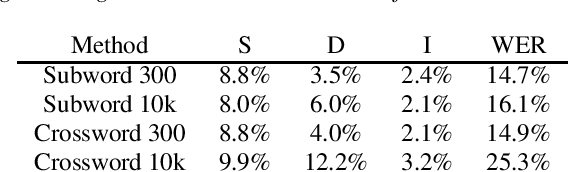
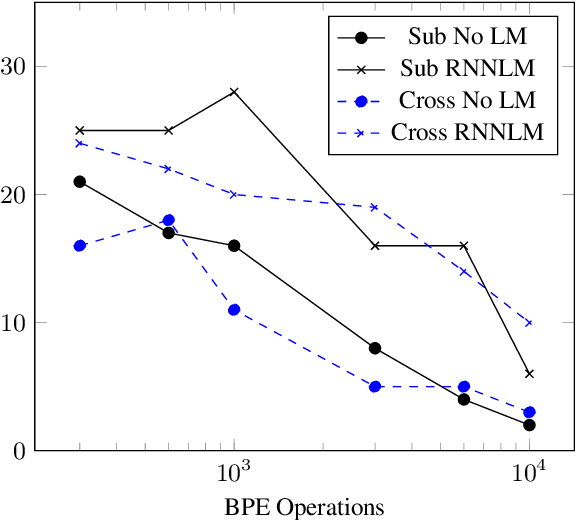

This paper proposes a novel approach to create an unit set for CTC based speech recognition systems. By using Byte Pair Encoding we learn an unit set of an arbitrary size on a given training text. In contrast to using characters or words as units this allows us to find a good trade-off between the size of our unit set and the available training data. We evaluate both Crossword units, that may span multiple word, and Subword units. By combining this approach with decoding methods using a separate language model we are able to achieve state of the art results for grapheme based CTC systems.
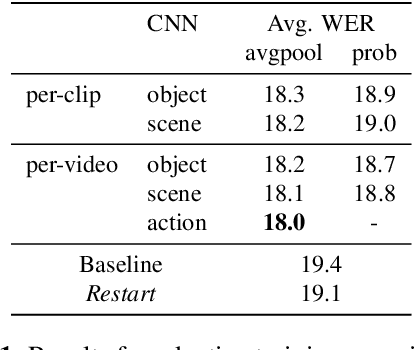
End-to-End Multimodal Speech Recognition
Apr 25, 2018
Transcription or sub-titling of open-domain videos is still a challenging domain for Automatic Speech Recognition (ASR) due to the data's challenging acoustics, variable signal processing and the essentially unrestricted domain of the data. In previous work, we have shown that the visual channel -- specifically object and scene features -- can help to adapt the acoustic model (AM) and language model (LM) of a recognizer, and we are now expanding this work to end-to-end approaches. In the case of a Connectionist Temporal Classification (CTC)-based approach, we retain the separation of AM and LM, while for a sequence-to-sequence (S2S) approach, both information sources are adapted together, in a single model. This paper also analyzes the behavior of CTC and S2S models on noisy video data (How-To corpus), and compares it to results on the clean Wall Street Journal (WSJ) corpus, providing insight into the robustness of both approaches.
Sequence-based Multi-lingual Low Resource Speech Recognition
Mar 06, 2018
Techniques for multi-lingual and cross-lingual speech recognition can help in low resource scenarios, to bootstrap systems and enable analysis of new languages and domains. End-to-end approaches, in particular sequence-based techniques, are attractive because of their simplicity and elegance. While it is possible to integrate traditional multi-lingual bottleneck feature extractors as front-ends, we show that end-to-end multi-lingual training of sequence models is effective on context independent models trained using Connectionist Temporal Classification (CTC) loss. We show that our model improves performance on Babel languages by over 6% absolute in terms of word/phoneme error rate when compared to mono-lingual systems built in the same setting for these languages. We also show that the trained model can be adapted cross-lingually to an unseen language using just 25% of the target data. We show that training on multiple languages is important for very low resource cross-lingual target scenarios, but not for multi-lingual testing scenarios. Here, it appears beneficial to include large well prepared datasets.
Comparison of Decoding Strategies for CTC Acoustic Models
Aug 15, 2017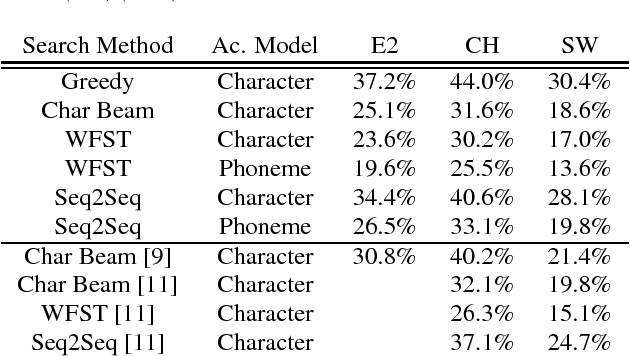


Connectionist Temporal Classification has recently attracted a lot of interest as it offers an elegant approach to building acoustic models (AMs) for speech recognition. The CTC loss function maps an input sequence of observable feature vectors to an output sequence of symbols. Output symbols are conditionally independent of each other under CTC loss, so a language model (LM) can be incorporated conveniently during decoding, retaining the traditional separation of acoustic and linguistic components in ASR. For fixed vocabularies, Weighted Finite State Transducers provide a strong baseline for efficient integration of CTC AMs with n-gram LMs. Character-based neural LMs provide a straight forward solution for open vocabulary speech recognition and all-neural models, and can be decoded with beam search. Finally, sequence-to-sequence models can be used to translate a sequence of individual sounds into a word string. We compare the performance of these three approaches, and analyze their error patterns, which provides insightful guidance for future research and development in this important area.