 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFlow: Learning a Better Training Set for Optical Flow
Apr 29, 2021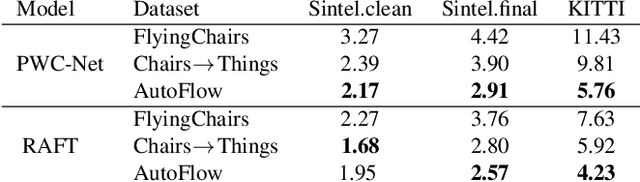
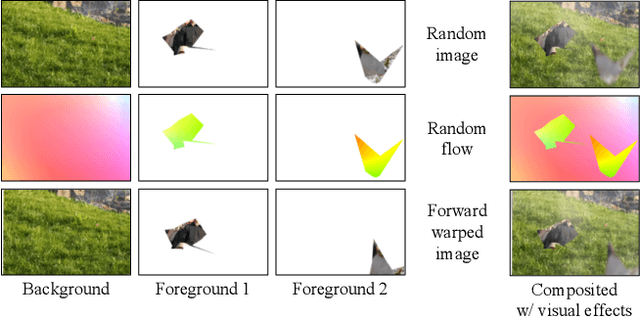
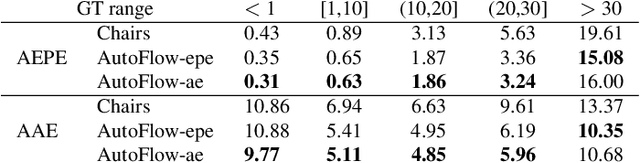
Synthetic datasets play a critical role in pre-training CNN models for optical flow, but they are painstaking to generate and hard to adapt to new applications. To automate the process, we present AutoFlow, a simple and effective method to render training data for optical flow that optimizes the performance of a model on a target dataset. AutoFlow takes a layered approach to render synthetic data, where the motion, shape, and appearance of each layer are controlled by learnable hyperparameters. Experimental results show that AutoFlow achieves state-of-the-art accuracy in pre-training both PWC-Net and RAFT. Our code and data are available at https://autoflow-google.github.io .
Object-centered image stitching
Nov 23, 2020

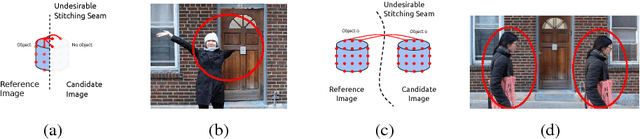

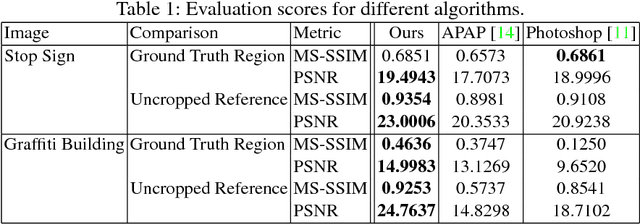
Image stitching is typically decomposed into three phases: registration, which aligns the source images with a common target image; seam finding, which determines for each target pixel the source image it should come from; and blending, which smooths transitions over the seams. As described in [1], the seam finding phase attempts to place seams between pixels where the transition between source images is not noticeable. Here, we observe that the most problematic failures of this approach occur when objects are cropped, omitted, or duplicated. We therefore take an object-centered approach to the problem, leveraging recent advances in object detection [2,3,4]. We penalize candidate solutions with this class of error by modifying the energy function used in the seam finding stage. This produces substantially more realistic stitching results on challenging imagery. In addition, these methods can be used to determine when there is non-recoverable occlusion in the input data, and also suggest a simple evaluation metric that can be used to evaluate the output of stitching algorithms.
Robust image stitching with multiple registrations
Nov 23, 2020


Panorama creation is one of the most widely deployed techniques in computer vision. In addition to industry applications such as Google Street View, it is also used by millions of consumers in smartphones and other cameras. Traditionally, the problem is decomposed into three phases: registration, which picks a single transformation of each source image to align it to the other inputs, seam finding, which selects a source image for each pixel in the final result, and blending, which fixes minor visual artifacts. Here, we observe that the use of a single registration often leads to errors, especially in scenes with significant depth variation or object motion. We propose instead the use of multiple registrations, permitting regions of the image at different depths to be captured with greater accuracy. MRF inference techniques naturally extend to seam finding over multiple registrations, and we show here that their energy functions can be readily modified with new terms that discourage duplication and tearing, common problems that are exacerbated by the use of multiple registrations. Our techniques are closely related to layer-based stereo, and move image stitching closer to explicit scene modeling. Experimental evidence demonstrates that our techniques often generate significantly better panoramas when there is substantial motion or parallax.
Learning to Autofocus
May 02, 2020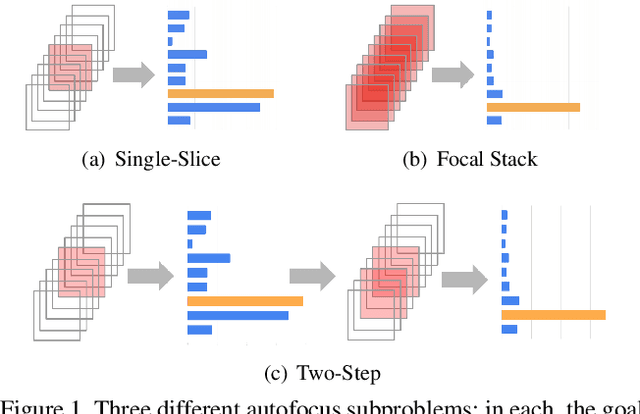
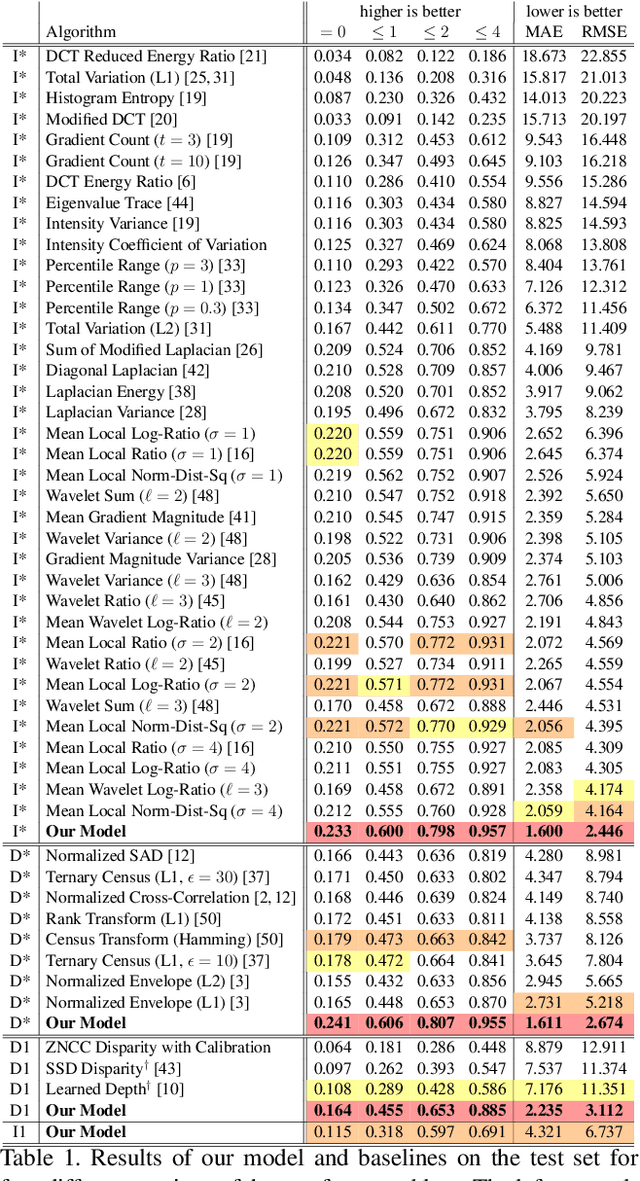
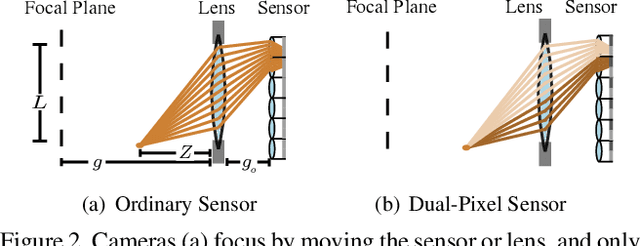
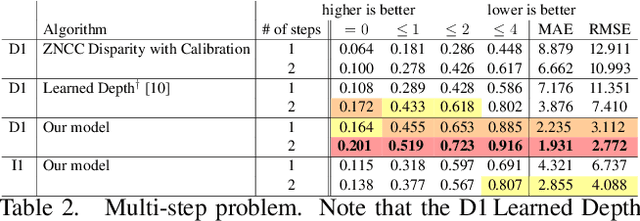
Autofocus is an important task for digital cameras, yet current approaches often exhibit poor performance. We propose a learning-based approach to this problem, and provide a realistic dataset of sufficient size for effective learning. Our dataset is labeled with per-pixel depths obtained from multi-view stereo, following "Learning single camera depth estimation using dual-pixels". Using this dataset, we apply modern deep classification models and an ordinal regression loss to obtain an efficient learning-based autofocus technique. We demonstrate that our approach provides a significant improvement compared with previous learned and non-learned methods: our model reduces the mean absolute error by a factor of 3.6 over the best comparable baseline algorithm. Our dataset and code are publicly available.
Deep networks with probabilistic gates
Dec 11, 2018
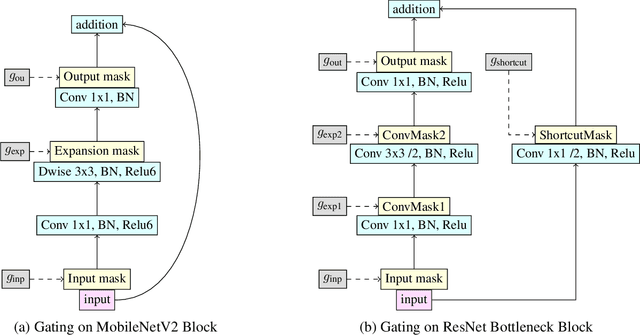
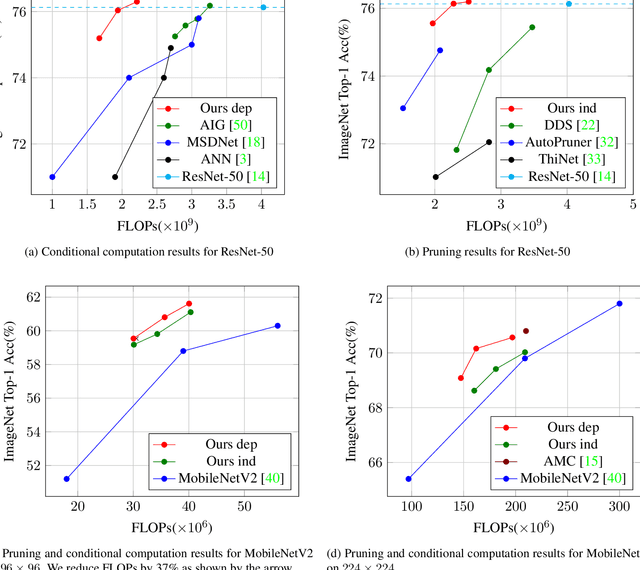
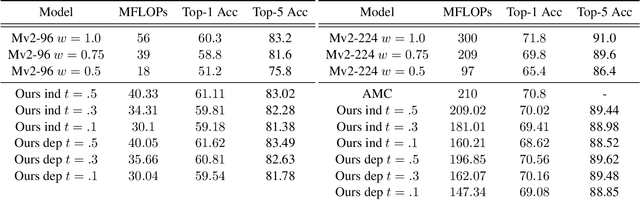
We investigate learning to probabilistically bypass computations in a network architecture. Our approach is motivated by AIG, where layers are conditionally executed depending on their inputs, and the network is trained against a target bypass rate using a per-layer loss. We propose a per-batch loss function, and describe strategies for handling probabilistic bypass during inference as well as training. Per-batch loss allows the network additional flexibility. In particular, a form of mode collapse becomes plausible, where some layers are nearly always bypassed and some almost never; such a configuration is strongly discouraged by AIG's per-layer loss. We explore several inference-time strategies, including the natural MAP approach. With data-dependent bypass, we demonstrate improved performance over AIG. With data-independent bypass, as in stochastic depth, we observe mode collapse and effectively prune layers. We demonstrate our techniques on ResNet-50 and ResNet-101 for ImageNet , where our techniques produce improved accuracy (.15--.41% in precision@1) with substantially less computation (bypassing 25--40% of the layers).
A discriminative view of MRF pre-processing algorithms
Aug 08, 2017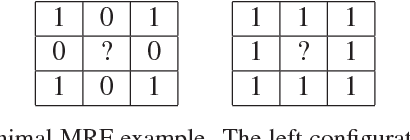
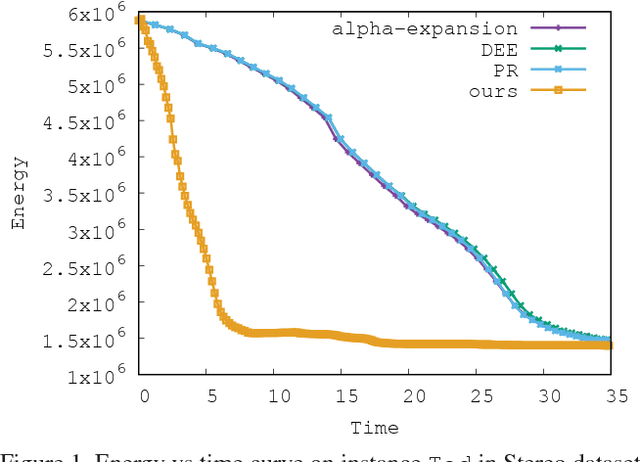
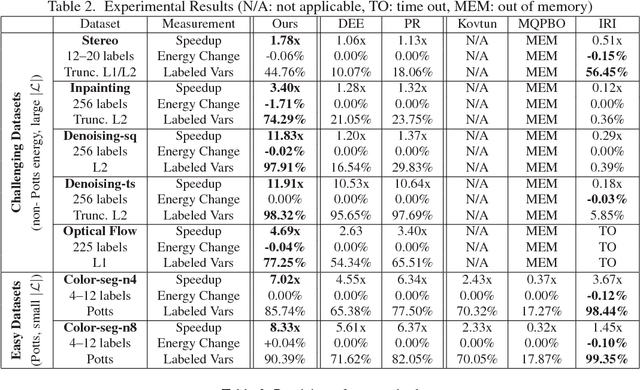
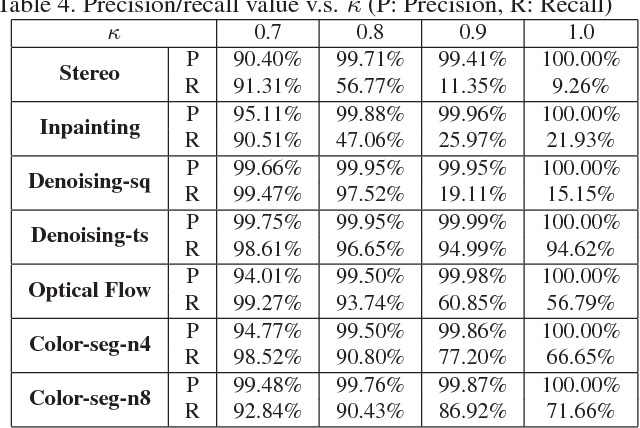
While Markov Random Fields (MRFs) are widely used in computer vision, they present a quite challenging inference problem. MRF inference can be accelerated by pre-processing techniques like Dead End Elimination (DEE) or QPBO-based approaches which compute the optimal labeling of a subset of variables. These techniques are guaranteed to never wrongly label a variable but they often leave a large number of variables unlabeled. We address this shortcoming by interpreting pre-processing as a classification problem, which allows us to trade off false positives (i.e., giving a variable an incorrect label) versus false negatives (i.e., failing to label a variable). We describe an efficient discriminative rule that finds optimal solutions for a subset of variables. Our technique provides both per-instance and worst-case guarantees concerning the quality of the solution. Empirical studies were conducted over several benchmark datasets. We obtain a speedup factor of 2 to 12 over expansion moves without preprocessing, and on difficult non-submodular energy functions produce slightly lower energy.
Some medical applications of example-based super-resolution
Apr 17, 2016Example-based super-resolution (EBSR) reconstructs a high-resolution image from a low-resolution image, given a training set of high-resolution images. In this note I propose some applications of EBSR to medical imaging. A particular interesting application, which I call "x-ray voxelization", approximates the result of a CT scan from an x-ray image.
Structured learning of sum-of-submodular higher order energy functions
Oct 01, 2013


Submodular functions can be exactly minimized in polynomial time, and the special case that graph cuts solve with max flow \cite{KZ:PAMI04} has had significant impact in computer vision \cite{BVZ:PAMI01,Kwatra:SIGGRAPH03,Rother:GrabCut04}. In this paper we address the important class of sum-of-submodular (SoS) functions \cite{Arora:ECCV12,Kolmogorov:DAM12}, which can be efficiently minimized via a variant of max flow called submodular flow \cite{Edmonds:ADM77}. SoS functions can naturally express higher order priors involving, e.g., local image patches; however, it is difficult to fully exploit their expressive power because they have so many parameters. Rather than trying to formulate existing higher order priors as an SoS function, we take a discriminative learning approach, effectively searching the space of SoS functions for a higher order prior that performs well on our training set. We adopt a structural SVM approach \cite{Joachims/etal/09a,Tsochantaridis/etal/04} and formulate the training problem in terms of quadratic programming; as a result we can efficiently search the space of SoS priors via an extended cutting-plane algorithm. We also show how the state-of-the-art max flow method for vision problems \cite{Goldberg:ESA11} can be modified to efficiently solve the submodular flow problem. Experimental comparisons are made against the OpenCV implementation of the GrabCut interactive segmentation technique \cite{Rother:GrabCut04}, which uses hand-tuned parameters instead of machine learning. On a standard dataset \cite{Gulshan:CVPR10} our method learns higher order priors with hundreds of parameter values, and produces significantly better segmentations. While our focus is on binary labeling problems, we show that our techniques can be naturally generalized to handle more than two labels.