 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
Dec 22, 2025



Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.
Beyond Blind Spots: Analytic Hints for Mitigating LLM-Based Evaluation Pitfalls
Dec 18, 2025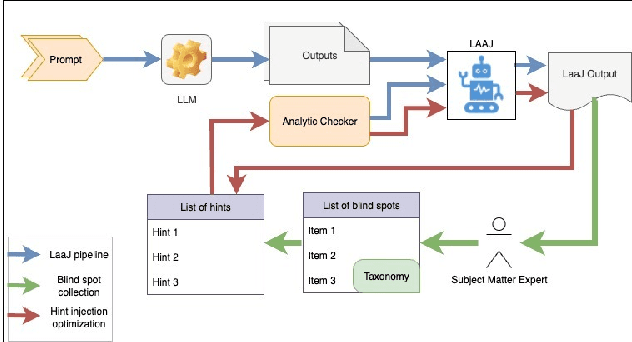

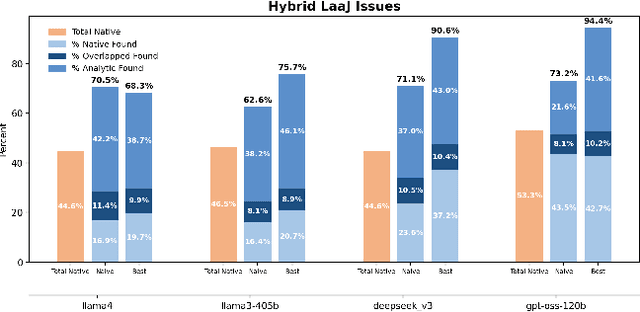
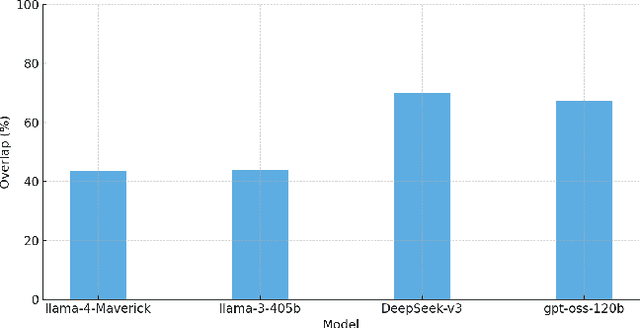
Large Language Models are increasingly deployed as judges (LaaJ) in code generation pipelines. While attractive for scalability, LaaJs tend to overlook domain specific issues raising concerns about their reliability in critical evaluation tasks. To better understand these limitations in practice, we examine LaaJ behavior in a concrete industrial use case: legacy code modernization via COBOL code generation. In this setting, we find that even production deployed LaaJs can miss domain critical errors, revealing consistent blind spots in their evaluation capabilities. To better understand these blind spots, we analyze generated COBOL programs and associated LaaJs judgments, drawing on expert knowledge to construct a preliminary taxonomy. Based on this taxonomy, we develop a lightweight analytic checker tool that flags over 30 domain specific issues observed in practice. We use its outputs as analytic hints, dynamically injecting them into the judges prompt to encourage LaaJ to revisit aspects it may have overlooked. Experiments on a test set of 100 programs using four production level LaaJs show that LaaJ alone detects only about 45% of the errors present in the code (in all judges we tested), while the analytic checker alone lacks explanatory depth. When combined, the LaaJ+Hints configuration achieves up to 94% coverage (for the best performing judge and injection prompt) and produces qualitatively richer, more accurate explanations, demonstrating that analytic-LLM hybrids can substantially enhance evaluation reliability in deployed pipelines. We release the dataset and all used prompts.
Vintage Code, Modern Judges: Meta-Validation in Low Data Regimes
Oct 31, 2025Application modernization in legacy languages such as COBOL, PL/I, and REXX faces an acute shortage of resources, both in expert availability and in high-quality human evaluation data. While Large Language Models as a Judge (LaaJ) offer a scalable alternative to expert review, their reliability must be validated before being trusted in high-stakes workflows. Without principled validation, organizations risk a circular evaluation loop, where unverified LaaJs are used to assess model outputs, potentially reinforcing unreliable judgments and compromising downstream deployment decisions. Although various automated approaches to validating LaaJs have been proposed, alignment with human judgment remains a widely used and conceptually grounded validation strategy. In many real-world domains, the availability of human-labeled evaluation data is severely limited, making it difficult to assess how well a LaaJ aligns with human judgment. We introduce SparseAlign, a formal framework for assessing LaaJ alignment with sparse human-labeled data. SparseAlign combines a novel pairwise-confidence concept with a score-sensitive alignment metric that jointly capture ranking consistency and score proximity, enabling reliable evaluator selection even when traditional statistical methods are ineffective due to limited annotated examples. SparseAlign was applied internally to select LaaJs for COBOL code explanation. The top-aligned evaluators were integrated into assessment workflows, guiding model release decisions. We present a case study of four LaaJs to demonstrate SparseAlign's utility in real-world evaluation scenarios.
Using Combinatorial Optimization to Design a High quality LLM Solution
May 15, 2024We introduce a novel LLM based solution design approach that utilizes combinatorial optimization and sampling. Specifically, a set of factors that influence the quality of the solution are identified. They typically include factors that represent prompt types, LLM inputs alternatives, and parameters governing the generation and design alternatives. Identifying the factors that govern the LLM solution quality enables the infusion of subject matter expert knowledge. Next, a set of interactions between the factors are defined and combinatorial optimization is used to create a small subset $P$ that ensures all desired interactions occur in $P$. Each element $p \in P$ is then developed into an appropriate benchmark. Applying the alternative solutions on each combination, $p \in P$ and evaluating the results facilitate the design of a high quality LLM solution pipeline. The approach is especially applicable when the design and evaluation of each benchmark in $P$ is time-consuming and involves manual steps and human evaluation. Given its efficiency the approach can also be used as a baseline to compare and validate an autoML approach that searches over the factors governing the solution.