 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Blind Spots: Analytic Hints for Mitigating LLM-Based Evaluation Pitfalls
Dec 18, 2025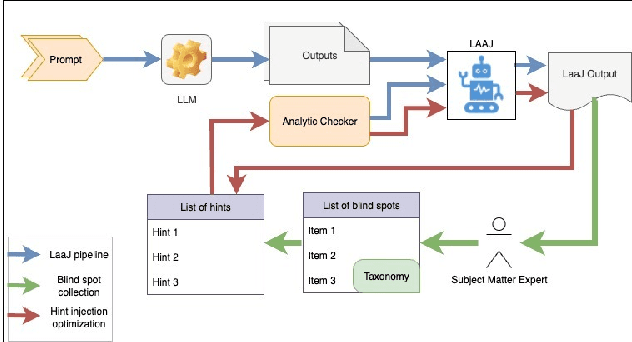

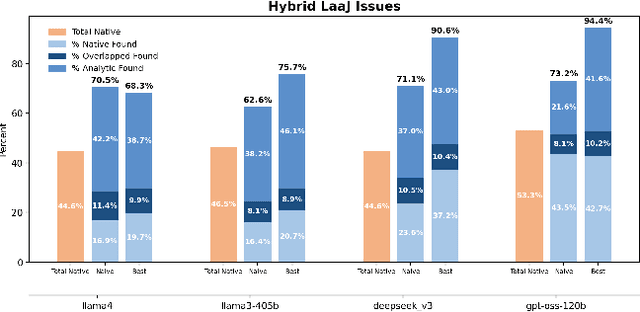
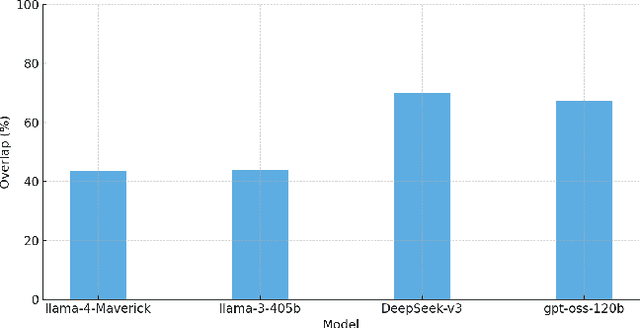
Large Language Models are increasingly deployed as judges (LaaJ) in code generation pipelines. While attractive for scalability, LaaJs tend to overlook domain specific issues raising concerns about their reliability in critical evaluation tasks. To better understand these limitations in practice, we examine LaaJ behavior in a concrete industrial use case: legacy code modernization via COBOL code generation. In this setting, we find that even production deployed LaaJs can miss domain critical errors, revealing consistent blind spots in their evaluation capabilities. To better understand these blind spots, we analyze generated COBOL programs and associated LaaJs judgments, drawing on expert knowledge to construct a preliminary taxonomy. Based on this taxonomy, we develop a lightweight analytic checker tool that flags over 30 domain specific issues observed in practice. We use its outputs as analytic hints, dynamically injecting them into the judges prompt to encourage LaaJ to revisit aspects it may have overlooked. Experiments on a test set of 100 programs using four production level LaaJs show that LaaJ alone detects only about 45% of the errors present in the code (in all judges we tested), while the analytic checker alone lacks explanatory depth. When combined, the LaaJ+Hints configuration achieves up to 94% coverage (for the best performing judge and injection prompt) and produces qualitatively richer, more accurate explanations, demonstrating that analytic-LLM hybrids can substantially enhance evaluation reliability in deployed pipelines. We release the dataset and all used prompts.
Vintage Code, Modern Judges: Meta-Validation in Low Data Regimes
Oct 31, 2025Application modernization in legacy languages such as COBOL, PL/I, and REXX faces an acute shortage of resources, both in expert availability and in high-quality human evaluation data. While Large Language Models as a Judge (LaaJ) offer a scalable alternative to expert review, their reliability must be validated before being trusted in high-stakes workflows. Without principled validation, organizations risk a circular evaluation loop, where unverified LaaJs are used to assess model outputs, potentially reinforcing unreliable judgments and compromising downstream deployment decisions. Although various automated approaches to validating LaaJs have been proposed, alignment with human judgment remains a widely used and conceptually grounded validation strategy. In many real-world domains, the availability of human-labeled evaluation data is severely limited, making it difficult to assess how well a LaaJ aligns with human judgment. We introduce SparseAlign, a formal framework for assessing LaaJ alignment with sparse human-labeled data. SparseAlign combines a novel pairwise-confidence concept with a score-sensitive alignment metric that jointly capture ranking consistency and score proximity, enabling reliable evaluator selection even when traditional statistical methods are ineffective due to limited annotated examples. SparseAlign was applied internally to select LaaJs for COBOL code explanation. The top-aligned evaluators were integrated into assessment workflows, guiding model release decisions. We present a case study of four LaaJs to demonstrate SparseAlign's utility in real-world evaluation scenarios.
LaajMeter: A Framework for LaaJ Evaluation
Aug 13, 2025Large Language Models (LLMs) are increasingly used as evaluators in natural language processing tasks, a paradigm known as LLM-as-a-Judge (LaaJ). While effective in general domains, LaaJs pose significant challenges in domain-specific contexts, where annotated data is scarce and expert evaluation is costly. In such cases, meta-evaluation is often performed using metrics that have not been validated for the specific domain in which they are applied. As a result, it becomes difficult to determine which metrics effectively identify LaaJ quality, and further, what threshold indicates sufficient evaluator performance. In this work, we introduce LaaJMeter, a simulation-based framework for controlled meta-evaluation of LaaJs. LaaJMeter enables engineers to generate synthetic data representing virtual models and judges, allowing systematic analysis of evaluation metrics under realistic conditions. This helps practitioners validate and refine LaaJs for specific evaluation tasks: they can test whether their metrics correctly distinguish between better and worse (virtual) LaaJs, and estimate appropriate thresholds for evaluator adequacy. We demonstrate the utility of LaaJMeter in a code translation task involving a legacy programming language, showing how different metrics vary in sensitivity to evaluator quality. Our results highlight the limitations of common metrics and the importance of principled metric selection. LaaJMeter provides a scalable and extensible solution for assessing LaaJs in low-resource settings, contributing to the broader effort to ensure trustworthy and reproducible evaluation in NLP.