 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenGen: Sentence Generating Neural Variational Topic Model
Aug 01, 2017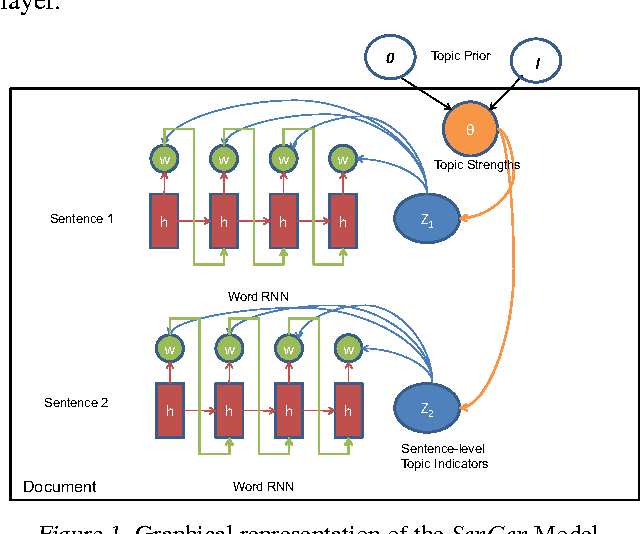

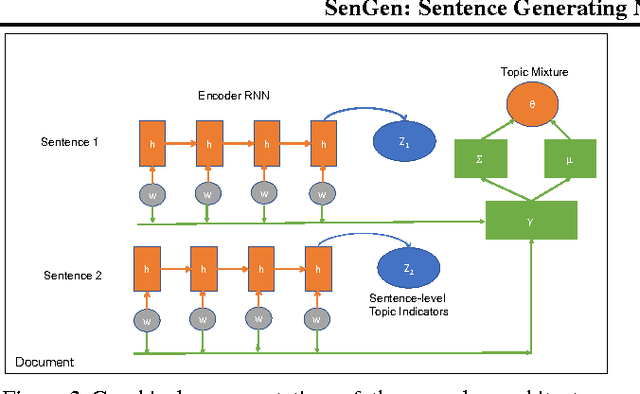
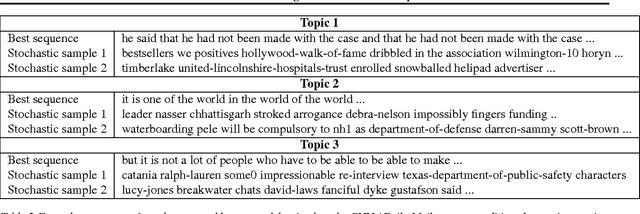
We present a new topic model that generates documents by sampling a topic for one whole sentence at a time, and generating the words in the sentence using an RNN decoder that is conditioned on the topic of the sentence. We argue that this novel formalism will help us not only visualize and model the topical discourse structure in a document better, but also potentially lead to more interpretable topics since we can now illustrate topics by sampling representative sentences instead of bag of words or phrases. We present a variational auto-encoder approach for learning in which we use a factorized variational encoder that independently models the posterior over topical mixture vectors of documents using a feed-forward network, and the posterior over topic assignments to sentences using an RNN. Our preliminary experiments on two different datasets indicate early promise, but also expose many challenges that remain to be addressed.
Classify or Select: Neural Architectures for Extractive Document Summarization
Nov 14, 2016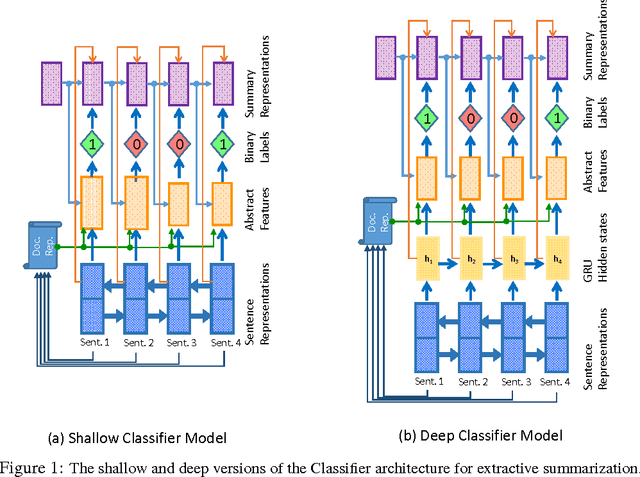

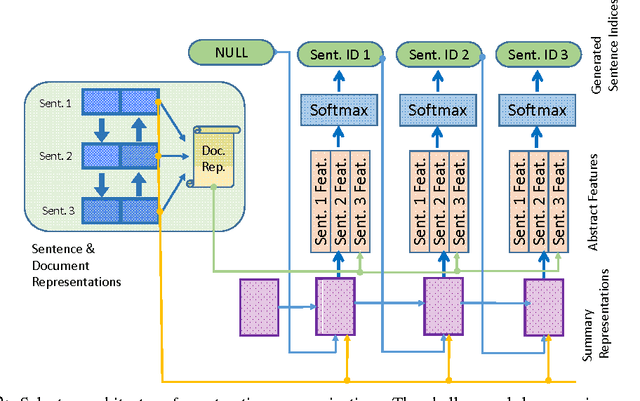
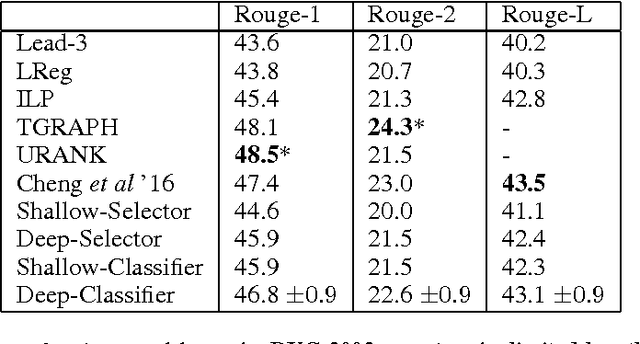
We present two novel and contrasting Recurrent Neural Network (RNN) based architectures for extractive summarization of documents. The Classifier based architecture sequentially accepts or rejects each sentence in the original document order for its membership in the final summary. The Selector architecture, on the other hand, is free to pick one sentence at a time in any arbitrary order to piece together the summary. Our models under both architectures jointly capture the notions of salience and redundancy of sentences. In addition, these models have the advantage of being very interpretable, since they allow visualization of their predictions broken up by abstract features such as information content, salience and redundancy. We show that our models reach or outperform state-of-the-art supervised models on two different corpora. We also recommend the conditions under which one architecture is superior to the other based on experimental evidence.
SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents
Nov 14, 2016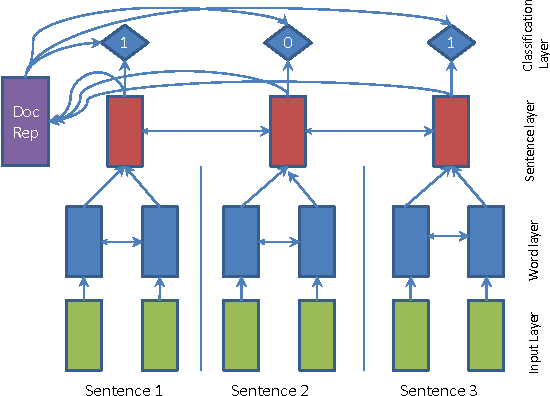
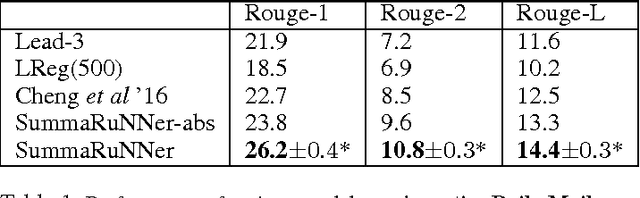

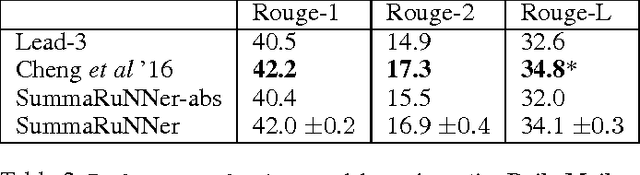
We present SummaRuNNer, a Recurrent Neural Network (RNN) based sequence model for extractive summarization of documents and show that it achieves performance better than or comparable to state-of-the-art. Our model has the additional advantage of being very interpretable, since it allows visualization of its predictions broken up by abstract features such as information content, salience and novelty. Another novel contribution of our work is abstractive training of our extractive model that can train on human generated reference summaries alone, eliminating the need for sentence-level extractive labels.
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond
Aug 26, 2016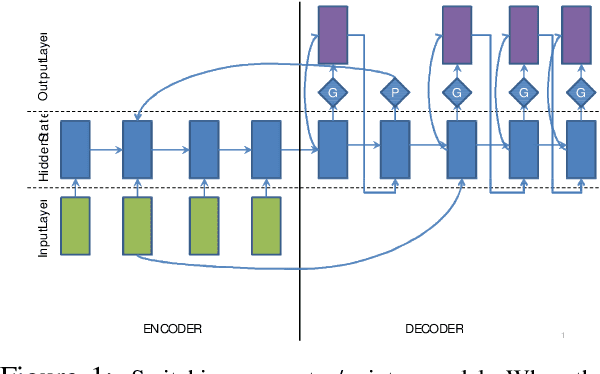
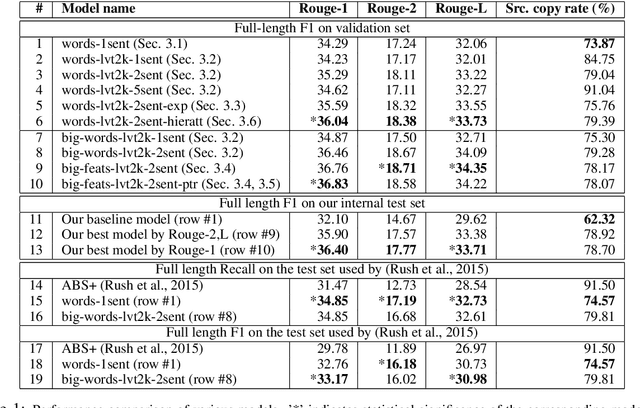
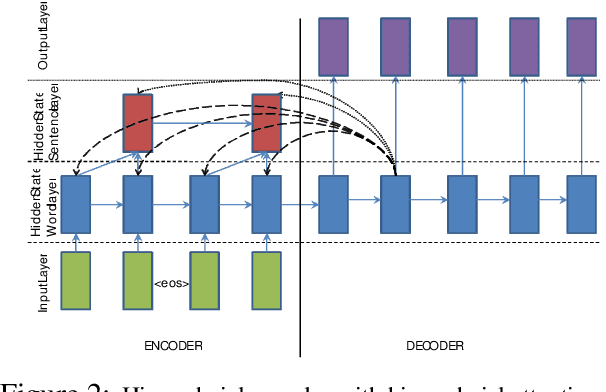
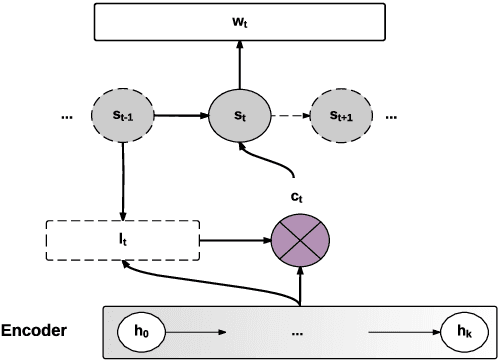
In this work, we model abstractive text summarization using Attentional Encoder-Decoder Recurrent Neural Networks, and show that they achieve state-of-the-art performance on two different corpora. We propose several novel models that address critical problems in summarization that are not adequately modeled by the basic architecture, such as modeling key-words, capturing the hierarchy of sentence-to-word structure, and emitting words that are rare or unseen at training time. Our work shows that many of our proposed models contribute to further improvement in performance. We also propose a new dataset consisting of multi-sentence summaries, and establish performance benchmarks for further research.
Pointing the Unknown Words
Aug 21, 2016


The problem of rare and unknown words is an important issue that can potentially influence the performance of many NLP systems, including both the traditional count-based and the deep learning models. We propose a novel way to deal with the rare and unseen words for the neural network models using attention. Our model uses two softmax layers in order to predict the next word in conditional language models: one predicts the location of a word in the source sentence, and the other predicts a word in the shortlist vocabulary. At each time-step, the decision of which softmax layer to use choose adaptively made by an MLP which is conditioned on the context.~We motivate our work from a psychological evidence that humans naturally have a tendency to point towards objects in the context or the environment when the name of an object is not known.~We observe improvements on two tasks, neural machine translation on the Europarl English to French parallel corpora and text summarization on the Gigaword dataset using our proposed model.