 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond [CLS] through Ranking by Generation
Oct 06, 2020![Figure 1 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F4-Table3-1.png&w=640&q=75)
Generative models for Information Retrieval, where ranking of documents is viewed as the task of generating a query from a document's language model, were very successful in various IR tasks in the past. However, with the advent of modern deep neural networks, attention has shifted to discriminative ranking functions that model the semantic similarity of documents and queries instead. Recently, deep generative models such as GPT2 and BART have been shown to be excellent text generators, but their effectiveness as rankers have not been demonstrated yet. In this work, we revisit the generative framework for information retrieval and show that our generative approaches are as effective as state-of-the-art semantic similarity-based discriminative models for the answer selection task. Additionally, we demonstrate the effectiveness of unlikelihood losses for IR.
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Apr 24, 2020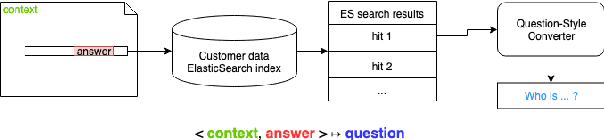


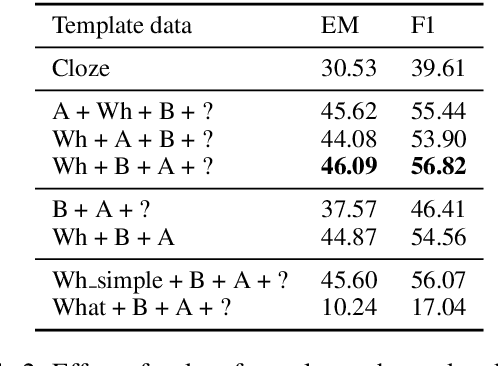
Question Answering (QA) is in increasing demand as the amount of information available online and the desire for quick access to this content grows. A common approach to QA has been to fine-tune a pretrained language model on a task-specific labeled dataset. This paradigm, however, relies on scarce, and costly to obtain, large-scale human-labeled data. We propose an unsupervised approach to training QA models with generated pseudo-training data. We show that generating questions for QA training by applying a simple template on a related, retrieved sentence rather than the original context sentence improves downstream QA performance by allowing the model to learn more complex context-question relationships. Training a QA model on this data gives a relative improvement over a previous unsupervised model in F1 score on the SQuAD dataset by about 14%, and 20% when the answer is a named entity, achieving state-of-the-art performance on SQuAD for unsupervised QA.
Who did They Respond to? Conversation Structure Modeling using Masked Hierarchical Transformer
Nov 25, 2019
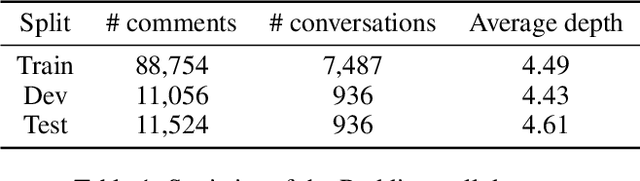
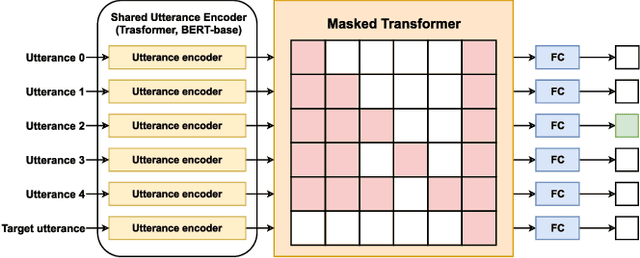
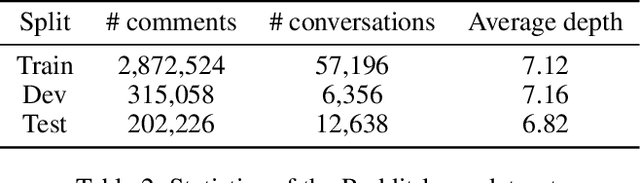
Conversation structure is useful for both understanding the nature of conversation dynamics and for providing features for many downstream applications such as summarization of conversations. In this work, we define the problem of conversation structure modeling as identifying the parent utterance(s) to which each utterance in the conversation responds to. Previous work usually took a pair of utterances to decide whether one utterance is the parent of the other. We believe the entire ancestral history is a very important information source to make accurate prediction. Therefore, we design a novel masking mechanism to guide the ancestor flow, and leverage the transformer model to aggregate all ancestors to predict parent utterances. Our experiments are performed on the Reddit dataset (Zhang, Culbertson, and Paritosh 2017) and the Ubuntu IRC dataset (Kummerfeld et al. 2019). In addition, we also report experiments on a new larger corpus from the Reddit platform and release this dataset. We show that the proposed model, that takes into account the ancestral history of the conversation, significantly outperforms several strong baselines including the BERT model on all datasets
Universal Text Representation from BERT: An Empirical Study
Oct 23, 2019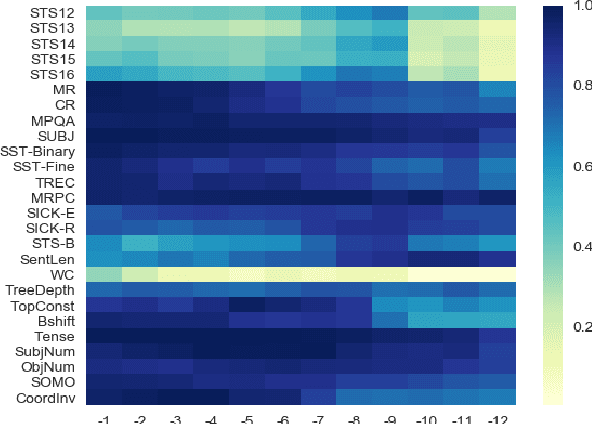
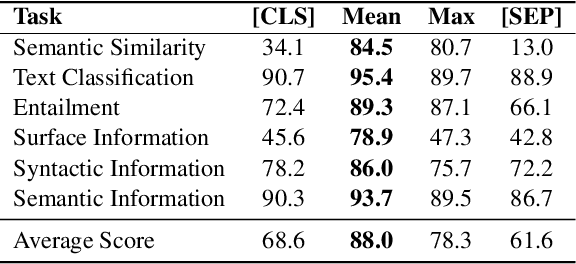
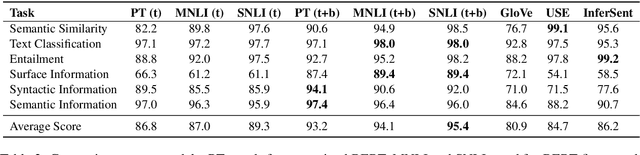
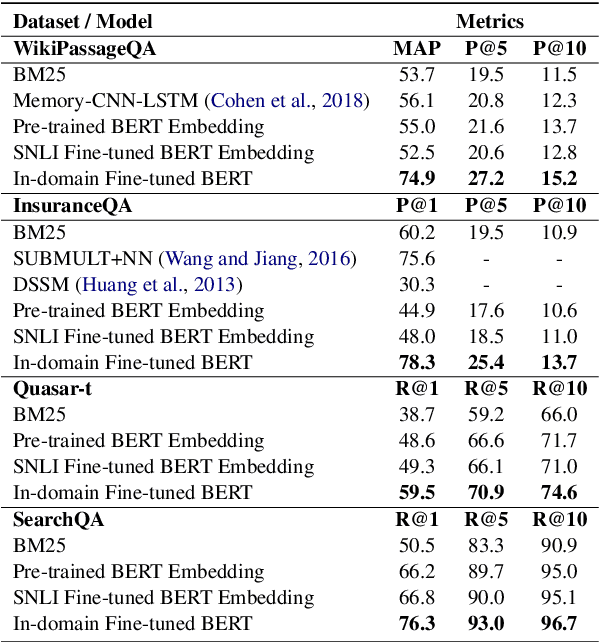
We present a systematic investigation of layer-wise BERT activations for general-purpose text representations to understand what linguistic information they capture and how transferable they are across different tasks. Sentence-level embeddings are evaluated against two state-of-the-art models on downstream and probing tasks from SentEval, while passage-level embeddings are evaluated on four question-answering (QA) datasets under a learning-to-rank problem setting. Embeddings from the pre-trained BERT model perform poorly in semantic similarity and sentence surface information probing tasks. Fine-tuning BERT on natural language inference data greatly improves the quality of the embeddings. Combining embeddings from different BERT layers can further boost performance. BERT embeddings outperform BM25 baseline significantly on factoid QA datasets at the passage level, but fail to perform better than BM25 on non-factoid datasets. For all QA datasets, there is a gap between embedding-based method and in-domain fine-tuned BERT (we report new state-of-the-art results on two datasets), which suggests deep interactions between question and answer pairs are critical for those hard tasks.
Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering
Oct 02, 2019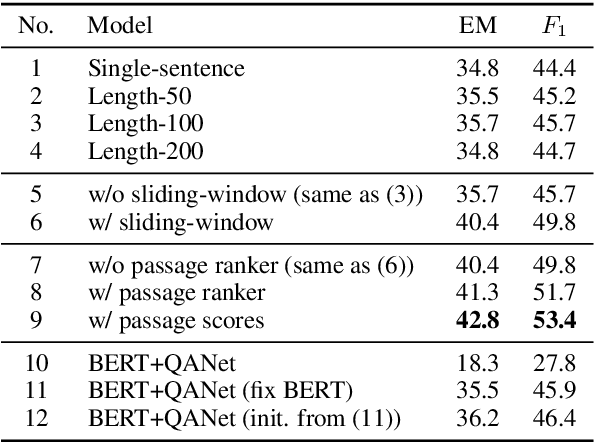
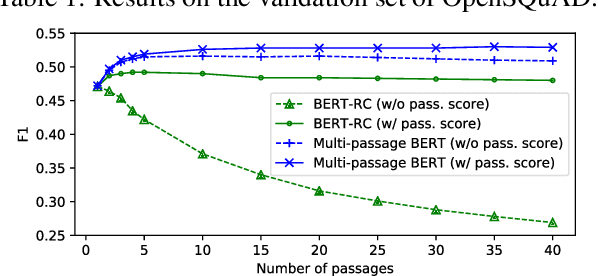
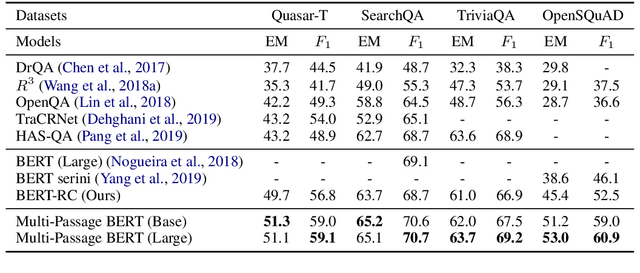
BERT model has been successfully applied to open-domain QA tasks. However, previous work trains BERT by viewing passages corresponding to the same question as independent training instances, which may cause incomparable scores for answers from different passages. To tackle this issue, we propose a multi-passage BERT model to globally normalize answer scores across all passages of the same question, and this change enables our QA model find better answers by utilizing more passages. In addition, we find that splitting articles into passages with the length of 100 words by sliding window improves performance by 4%. By leveraging a passage ranker to select high-quality passages, multi-passage BERT gains additional 2%. Experiments on four standard benchmarks showed that our multi-passage BERT outperforms all state-of-the-art models on all benchmarks. In particular, on the OpenSQuAD dataset, our model gains 21.4% EM and 21.5% $F_1$ over all non-BERT models, and 5.8% EM and 6.5% $F_1$ over BERT-based models.
Multi Sense Embeddings from Topic Models
Sep 17, 2019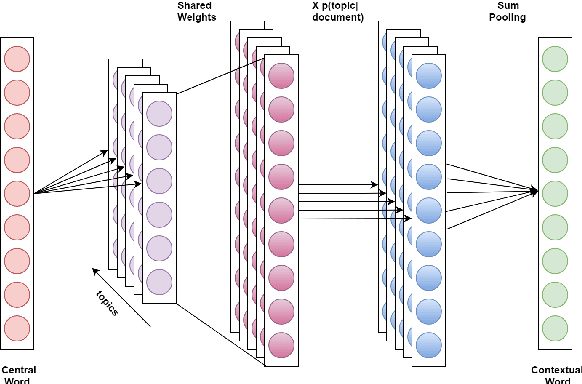
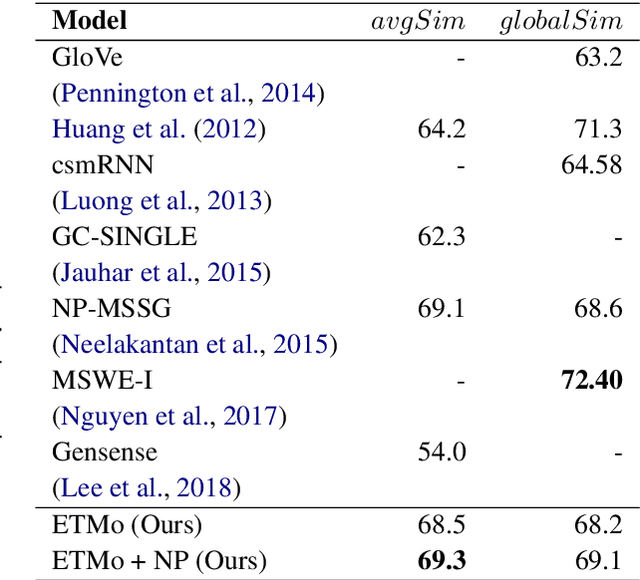
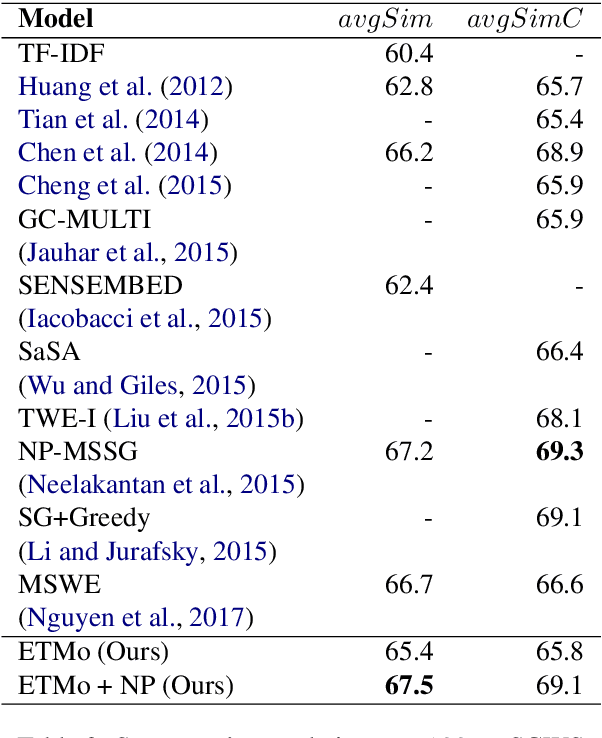

Distributed word embeddings have yielded state-of-the-art performance in many NLP tasks, mainly due to their success in capturing useful semantic information. These representations assign only a single vector to each word whereas a large number of words are polysemous (i.e., have multiple meanings). In this work, we approach this critical problem in lexical semantics, namely that of representing various senses of polysemous words in vector spaces. We propose a topic modeling based skip-gram approach for learning multi-prototype word embeddings. We also introduce a method to prune the embeddings determined by the probabilistic representation of the word in each topic. We use our embeddings to show that they can capture the context and word similarity strongly and outperform various state-of-the-art implementations.
* 8 pages, 1 figure, 7 tables
Topic Modeling with Wasserstein Autoencoders
Jul 24, 2019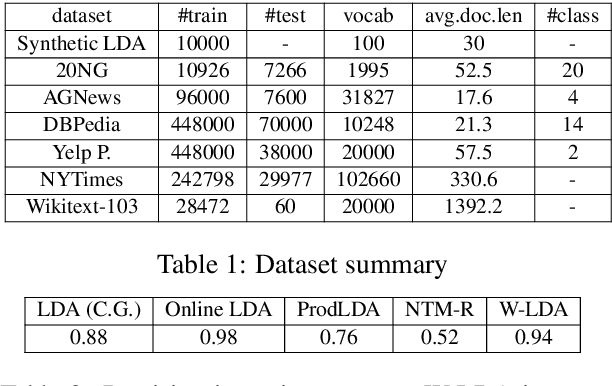
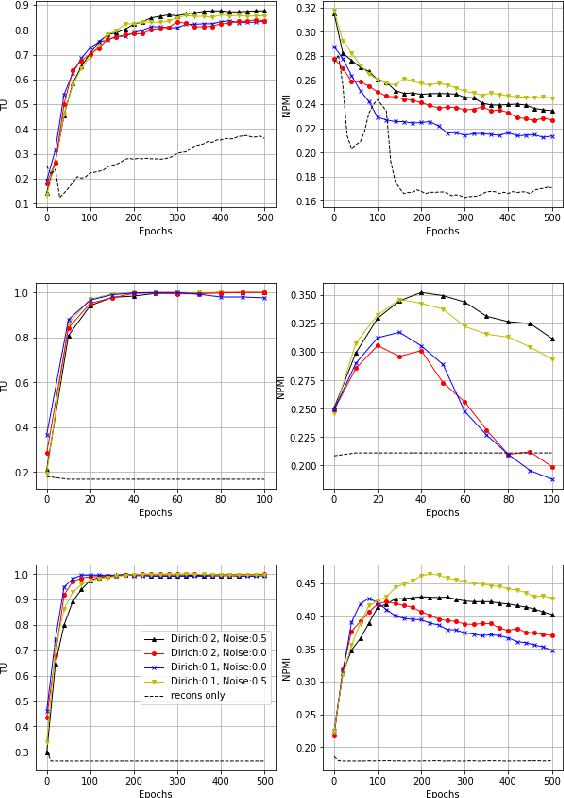

We propose a novel neural topic model in the Wasserstein autoencoders (WAE) framework. Unlike existing variational autoencoder based models, we directly enforce Dirichlet prior on the latent document-topic vectors. We exploit the structure of the latent space and apply a suitable kernel in minimizing the Maximum Mean Discrepancy (MMD) to perform distribution matching. We discover that MMD performs much better than the Generative Adversarial Network (GAN) in matching high dimensional Dirichlet distribution. We further discover that incorporating randomness in the encoder output during training leads to significantly more coherent topics. To measure the diversity of the produced topics, we propose a simple topic uniqueness metric. Together with the widely used coherence measure NPMI, we offer a more wholistic evaluation of topic quality. Experiments on several real datasets show that our model produces significantly better topics than existing topic models.
Passage Ranking with Weak Supervision
Jun 04, 2019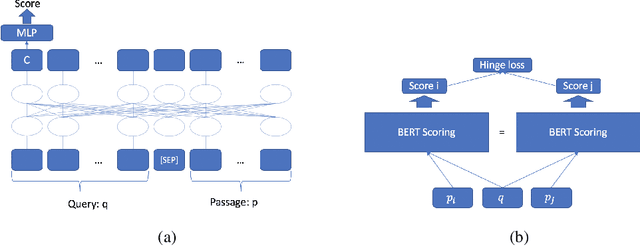

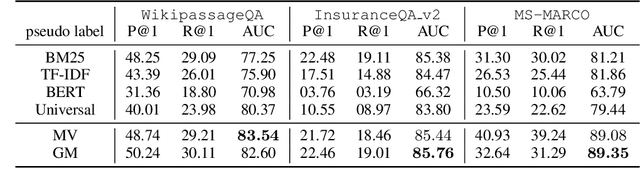
In this paper, we propose a \textit{weak supervision} framework for neural ranking tasks based on the data programming paradigm \citep{Ratner2016}, which enables us to leverage multiple weak supervision signals from different sources. Empirically, we consider two sources of weak supervision signals, unsupervised ranking functions and semantic feature similarities. We train a BERT-based passage-ranking model (which achieves new state-of-the-art performances on two benchmark datasets with full supervision) in our weak supervision framework. Without using ground-truth training labels, BERT-PR models outperform BM25 baseline by a large margin on all three datasets and even beat the previous state-of-the-art results with full supervision on two of the datasets.
* 6 pages, 1 figure
OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations
Mar 20, 2019
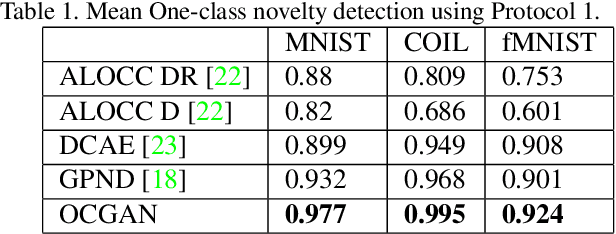
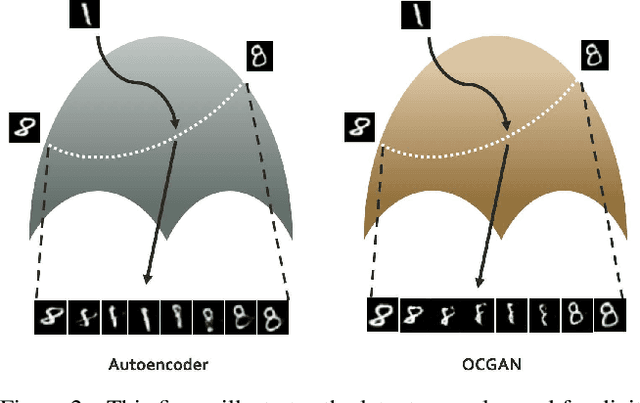
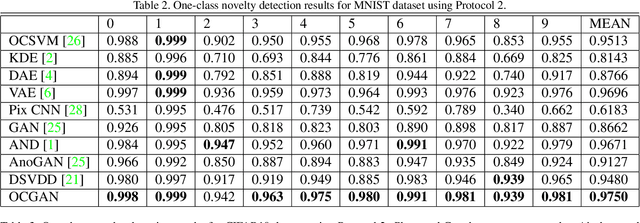
We present a novel model called OCGAN for the classical problem of one-class novelty detection, where, given a set of examples from a particular class, the goal is to determine if a query example is from the same class. Our solution is based on learning latent representations of in-class examples using a denoising auto-encoder network. The key contribution of our work is our proposal to explicitly constrain the latent space to exclusively represent the given class. In order to accomplish this goal, firstly, we force the latent space to have bounded support by introducing a tanh activation in the encoder's output layer. Secondly, using a discriminator in the latent space that is trained adversarially, we ensure that encoded representations of in-class examples resemble uniform random samples drawn from the same bounded space. Thirdly, using a second adversarial discriminator in the input space, we ensure all randomly drawn latent samples generate examples that look real. Finally, we introduce a gradient-descent based sampling technique that explores points in the latent space that generate potential out-of-class examples, which are fed back to the network to further train it to generate in-class examples from those points. The effectiveness of the proposed method is measured across four publicly available datasets using two one-class novelty detection protocols where we achieve state-of-the-art results.
Coherence-Aware Neural Topic Modeling
Sep 07, 2018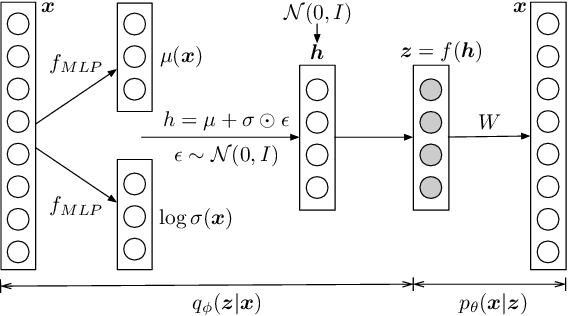
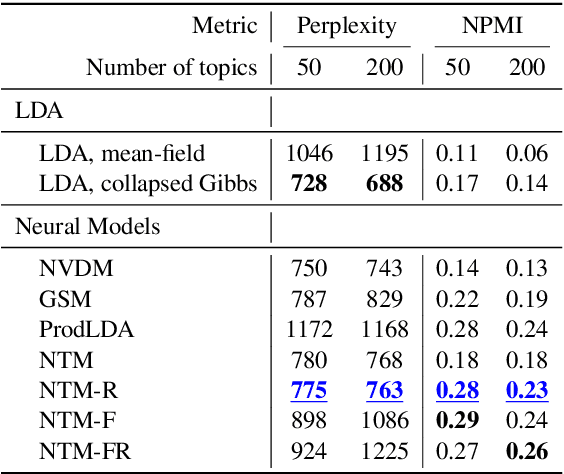
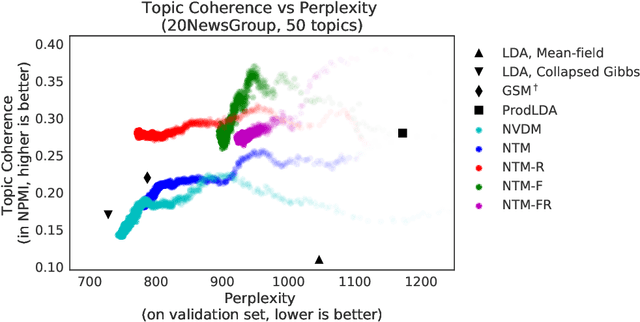
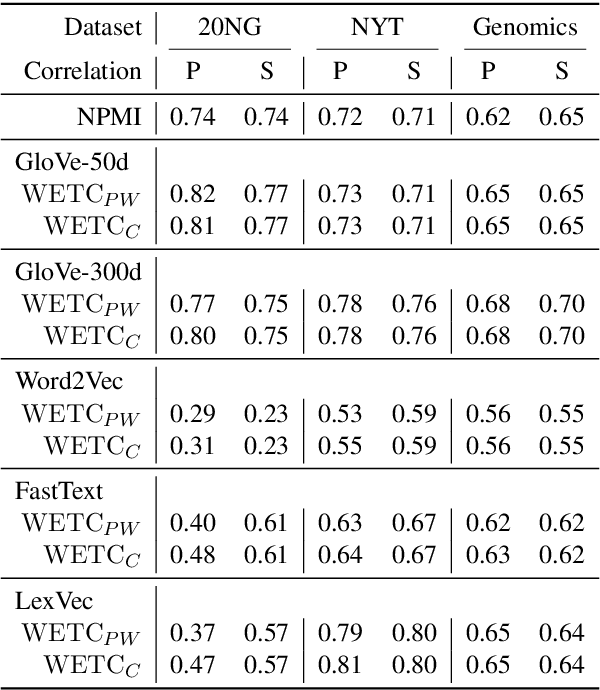
Topic models are evaluated based on their ability to describe documents well (i.e. low perplexity) and to produce topics that carry coherent semantic meaning. In topic modeling so far, perplexity is a direct optimization target. However, topic coherence, owing to its challenging computation, is not optimized for and is only evaluated after training. In this work, under a neural variational inference framework, we propose methods to incorporate a topic coherence objective into the training process. We demonstrate that such a coherence-aware topic model exhibits a similar level of perplexity as baseline models but achieves substantially higher topic coherence.