 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Aligned Faithfulness in Toxicity Explanations of LLMs
Jun 23, 2025The discourse around toxicity and LLMs in NLP largely revolves around detection tasks. This work shifts the focus to evaluating LLMs' reasoning about toxicity -- from their explanations that justify a stance -- to enhance their trustworthiness in downstream tasks. Despite extensive research on explainability, it is not straightforward to adopt existing methods to evaluate free-form toxicity explanation due to their over-reliance on input text perturbations, among other challenges. To account for these, we propose a novel, theoretically-grounded multi-dimensional criterion, Human-Aligned Faithfulness (HAF), that measures the extent to which LLMs' free-form toxicity explanations align with those of a rational human under ideal conditions. We develop six metrics, based on uncertainty quantification, to comprehensively evaluate \haf of LLMs' toxicity explanations with no human involvement, and highlight how "non-ideal" the explanations are. We conduct several experiments on three Llama models (of size up to 70B) and an 8B Ministral model on five diverse toxicity datasets. Our results show that while LLMs generate plausible explanations to simple prompts, their reasoning about toxicity breaks down when prompted about the nuanced relations between the complete set of reasons, the individual reasons, and their toxicity stances, resulting in inconsistent and nonsensical responses. We open-source our code and LLM-generated explanations at https://github.com/uofthcdslab/HAF.
Towards Unifying Feature Attribution and Counterfactual Explanations: Different Means to the Same End
Nov 10, 2020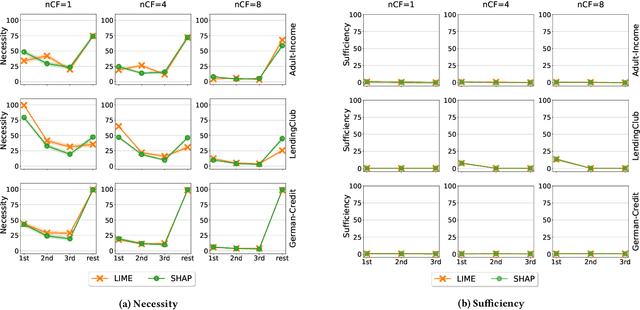

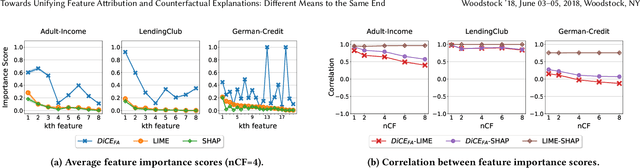
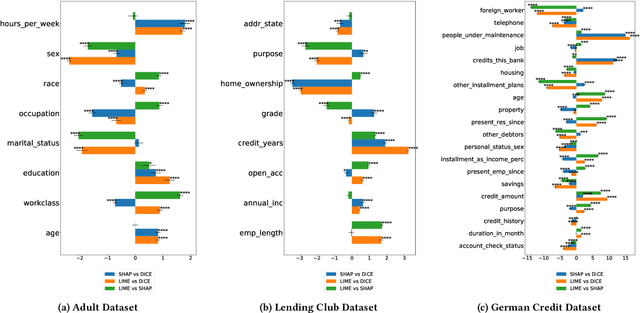
To explain a machine learning model, there are two main approaches: feature attributions that assign an importance score to each input feature, and counterfactual explanations that provide input examples with minimal changes to alter the model's prediction. We provide two key results towards unifying these approaches in terms of their interpretation and use. First, we present a method to generate feature attribution explanations from a set of counterfactual examples. These feature attributions convey how important a feature is to changing the classification outcome of a model, especially on whether a subset of features is necessary and/or sufficient for that change, which feature attribution methods are unable to provide. Second, we show how counterfactual examples can be used to evaluate the goodness of an attribution-based explanation in terms of its necessity and sufficiency. As a result, we highlight the complementarity of these two approaches and provide an interpretation based on a causal inference framework. Our evaluation on three benchmark datasets -- Adult Income, LendingClub, and GermanCredit -- confirm the complementarity. Feature attribution methods like LIME and SHAP and counterfactual explanation methods like DiCE often do not agree on feature importance rankings. In addition, by restricting the features that can be modified for generating counterfactual examples, we find that the top-k features from LIME or SHAP are neither necessary nor sufficient explanations of a model's prediction. Finally, we present a case study of different explanation methods on a real-world hospital triage problem.