 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Sentence: A Survey on Context-Aware Machine Translation with Large Language Models
Jun 09, 2025



Despite the popularity of the large language models (LLMs), their application to machine translation is relatively underexplored, especially in context-aware settings. This work presents a literature review of context-aware translation with LLMs. The existing works utilise prompting and fine-tuning approaches, with few focusing on automatic post-editing and creating translation agents for context-aware machine translation. We observed that the commercial LLMs (such as ChatGPT and Tower LLM) achieved better results than the open-source LLMs (such as Llama and Bloom LLMs), and prompt-based approaches serve as good baselines to assess the quality of translations. Finally, we present some interesting future directions to explore.
A Case Study on Context-Aware Neural Machine Translation with Multi-Task Learning
Jul 03, 2024



In document-level neural machine translation (DocNMT), multi-encoder approaches are common in encoding context and source sentences. Recent studies \cite{li-etal-2020-multi-encoder} have shown that the context encoder generates noise and makes the model robust to the choice of context. This paper further investigates this observation by explicitly modelling context encoding through multi-task learning (MTL) to make the model sensitive to the choice of context. We conduct experiments on cascade MTL architecture, which consists of one encoder and two decoders. Generation of the source from the context is considered an auxiliary task, and generation of the target from the source is the main task. We experimented with German--English language pairs on News, TED, and Europarl corpora. Evaluation results show that the proposed MTL approach performs better than concatenation-based and multi-encoder DocNMT models in low-resource settings and is sensitive to the choice of context. However, we observe that the MTL models are failing to generate the source from the context. These observations align with the previous studies, and this might suggest that the available document-level parallel corpora are not context-aware, and a robust sentence-level model can outperform the context-aware models.
Reference Free Domain Adaptation for Translation of Noisy Questions with Question Specific Rewards
Oct 23, 2023



Community Question-Answering (CQA) portals serve as a valuable tool for helping users within an organization. However, making them accessible to non-English-speaking users continues to be a challenge. Translating questions can broaden the community's reach, benefiting individuals with similar inquiries in various languages. Translating questions using Neural Machine Translation (NMT) poses more challenges, especially in noisy environments, where the grammatical correctness of the questions is not monitored. These questions may be phrased as statements by non-native speakers, with incorrect subject-verb order and sometimes even missing question marks. Creating a synthetic parallel corpus from such data is also difficult due to its noisy nature. To address this issue, we propose a training methodology that fine-tunes the NMT system only using source-side data. Our approach balances adequacy and fluency by utilizing a loss function that combines BERTScore and Masked Language Model (MLM) Score. Our method surpasses the conventional Maximum Likelihood Estimation (MLE) based fine-tuning approach, which relies on synthetic target data, by achieving a 1.9 BLEU score improvement. Our model exhibits robustness while we add noise to our baseline, and still achieve 1.1 BLEU improvement and large improvements on TER and BLEURT metrics. Our proposed methodology is model-agnostic and is only necessary during the training phase. We make the codes and datasets publicly available at \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html#DomainAdapt} for facilitating further research.
A Case Study on Context Encoding in Multi-Encoder based Document-Level Neural Machine Translation
Aug 11, 2023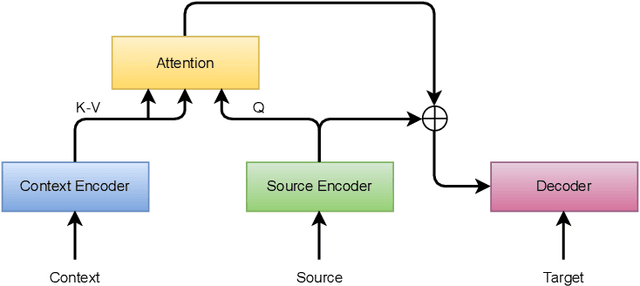
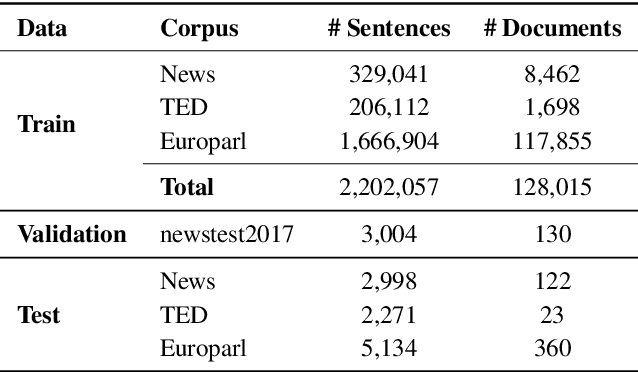
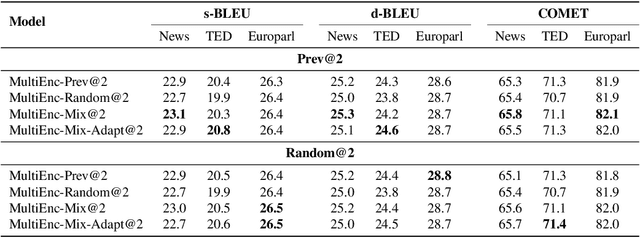
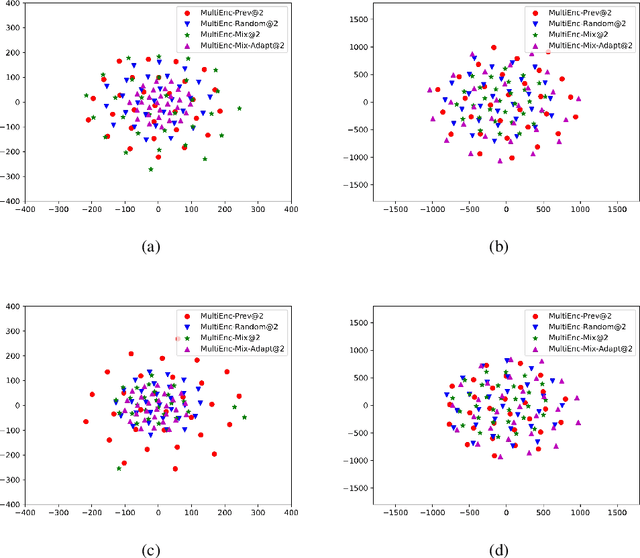
Recent studies have shown that the multi-encoder models are agnostic to the choice of context, and the context encoder generates noise which helps improve the models in terms of BLEU score. In this paper, we further explore this idea by evaluating with context-aware pronoun translation test set by training multi-encoder models trained on three different context settings viz, previous two sentences, random two sentences, and a mix of both as context. Specifically, we evaluate the models on the ContraPro test set to study how different contexts affect pronoun translation accuracy. The results show that the model can perform well on the ContraPro test set even when the context is random. We also analyze the source representations to study whether the context encoder generates noise. Our analysis shows that the context encoder provides sufficient information to learn discourse-level information. Additionally, we observe that mixing the selected context (the previous two sentences in this case) and the random context is generally better than the other settings.