 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Interactive Summarization: an Expansion-Based Framework
Sep 17, 2020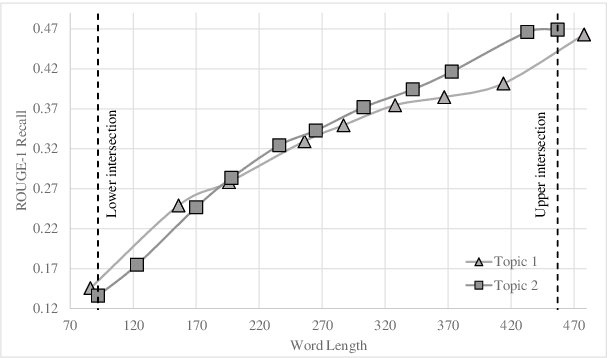
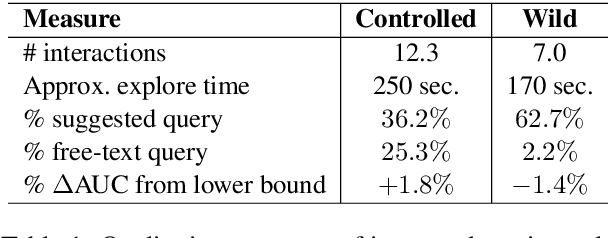

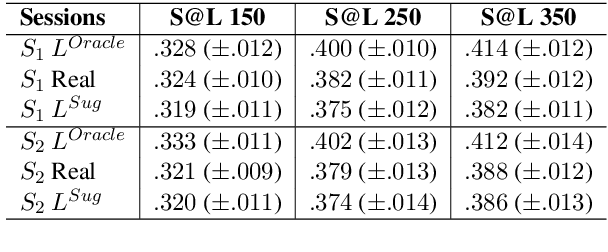
Allowing users to interact with multi-document summarizers is a promising direction towards improving and customizing summary results. Different ideas for interactive summarization have been proposed in previous work but these solutions are highly divergent and incomparable. In this paper, we develop an end-to-end evaluation framework for expansion-based interactive summarization, which considers the accumulating information along an interactive session. Our framework includes a procedure of collecting real user sessions and evaluation measures relying on standards, but adapted to reflect interaction. All of our solutions are intended to be released publicly as a benchmark, allowing comparison of future developments in interactive summarization. We demonstrate the use of our framework by evaluating and comparing baseline implementations that we developed for this purpose, which will serve as part of our benchmark. Our extensive experimentation and analysis of these systems motivate our design choices and support the viability of our framework.
SuperPAL: Supervised Proposition ALignment for Multi-Document Summarization and Derivative Sub-Tasks
Sep 01, 2020

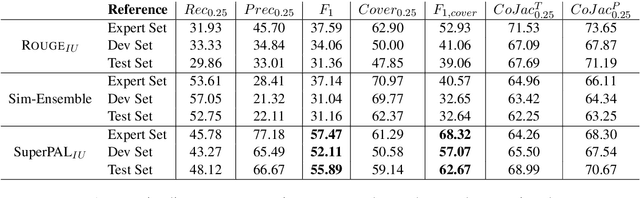
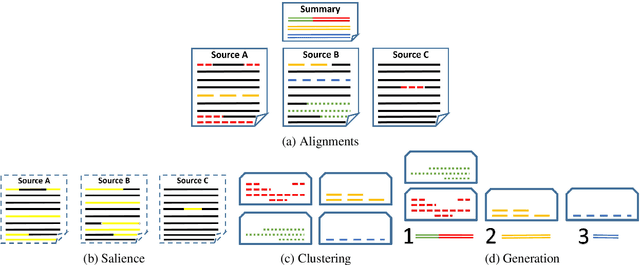
Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by generation. While alignment of spans between reference summaries and source documents has been leveraged for training component tasks, the underlying alignment step was never independently addressed or evaluated. We advocate developing high quality source-reference alignment algorithms, that can be applied to recent large-scale datasets to obtain useful "silver", i.e. approximate, training data. As a first step, we present an annotation methodology by which we create gold standard development and test sets for summary-source alignment, and suggest its utility for tuning and evaluating effective alignment algorithms, as well as for properly evaluating MDS subtasks. Second, we introduce a new large-scale alignment dataset for training, with which an automatic alignment model was trained. This aligner achieves higher coherency with the reference summary than previous aligners used for summarization, and gets significantly higher ROUGE results when replacing a simpler aligner in a competitive summarization model. Finally, we release three additional datasets (for salience, clustering and generation), naturally derived from our alignment datasets. Furthermore, these datasets can be derived from any summarization dataset automatically after extracting alignments with our trained aligner. Hence, they can be utilized for training summarization sub-tasks.
Multi-Source Domain Adaptation for Text Classification via DistanceNet-Bandits
Jan 17, 2020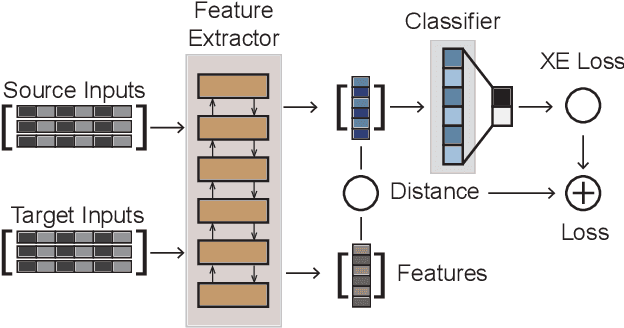
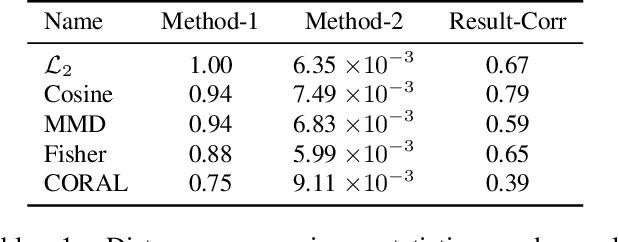
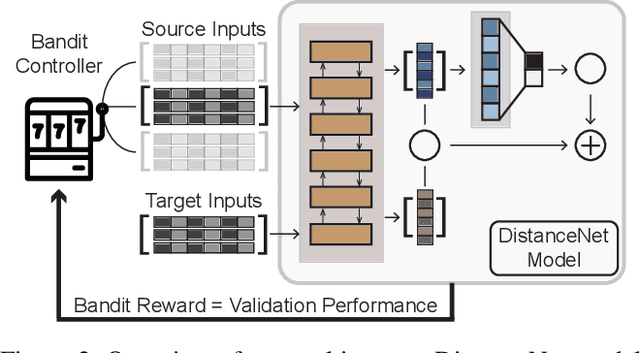

Domain adaptation performance of a learning algorithm on a target domain is a function of its source domain error and a divergence measure between the data distribution of these two domains. We present a study of various distance-based measures in the context of NLP tasks, that characterize the dissimilarity between domains based on sample estimates. We first conduct analysis experiments to show which of these distance measures can best differentiate samples from same versus different domains, and are correlated with empirical results. Next, we develop a DistanceNet model which uses these distance measures, or a mixture of these distance measures, as an additional loss function to be minimized jointly with the task's loss function, so as to achieve better unsupervised domain adaptation. Finally, we extend this model to a novel DistanceNet-Bandit model, which employs a multi-armed bandit controller to dynamically switch between multiple source domains and allow the model to learn an optimal trajectory and mixture of domains for transfer to the low-resource target domain. We conduct experiments on popular sentiment analysis datasets with several diverse domains and show that our DistanceNet model, as well as its dynamic bandit variant, can outperform competitive baselines in the context of unsupervised domain adaptation.
Continual and Multi-Task Architecture Search
Jun 12, 2019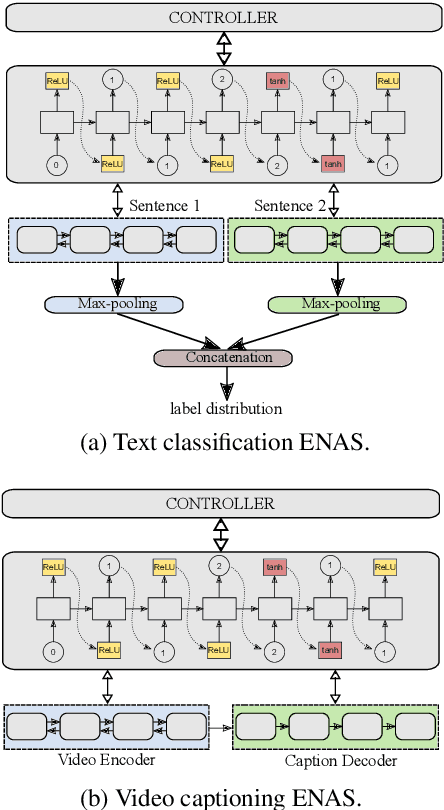
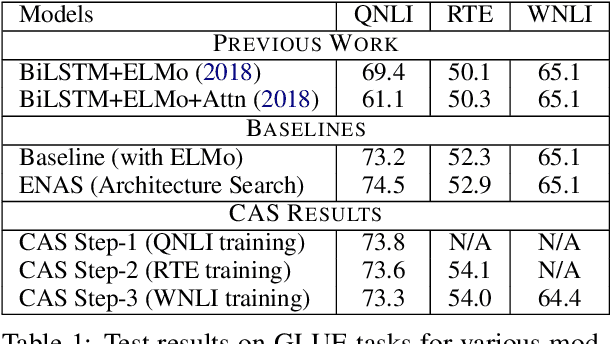
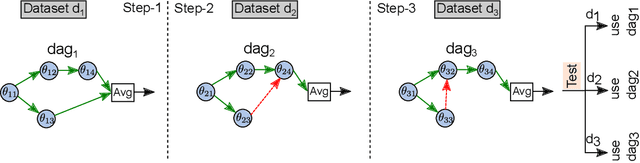
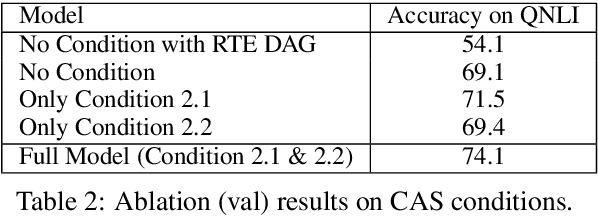
Architecture search is the process of automatically learning the neural model or cell structure that best suits the given task. Recently, this approach has shown promising performance improvements (on language modeling and image classification) with reasonable training speed, using a weight sharing strategy called Efficient Neural Architecture Search (ENAS). In our work, we first introduce a novel continual architecture search (CAS) approach, so as to continually evolve the model parameters during the sequential training of several tasks, without losing performance on previously learned tasks (via block-sparsity and orthogonality constraints), thus enabling life-long learning. Next, we explore a multi-task architecture search (MAS) approach over ENAS for finding a unified, single cell structure that performs well across multiple tasks (via joint controller rewards), and hence allows more generalizable transfer of the cell structure knowledge to an unseen new task. We empirically show the effectiveness of our sequential continual learning and parallel multi-task learning based architecture search approaches on diverse sentence-pair classification tasks (GLUE) and multimodal-generation based video captioning tasks. Further, we present several ablations and analyses on the learned cell structures.
Crowdsourcing Lightweight Pyramids for Manual Summary Evaluation
Apr 11, 2019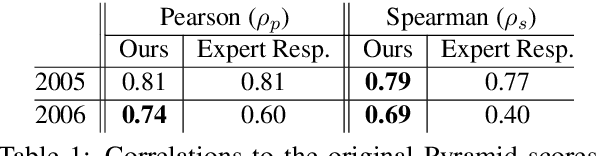
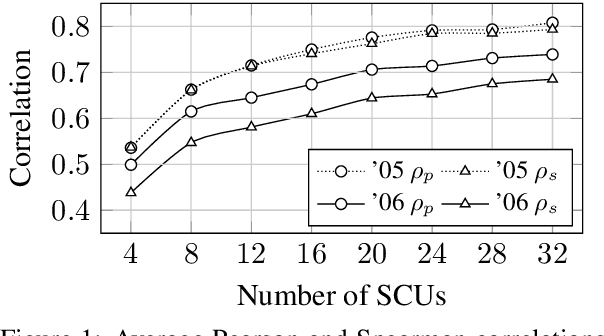
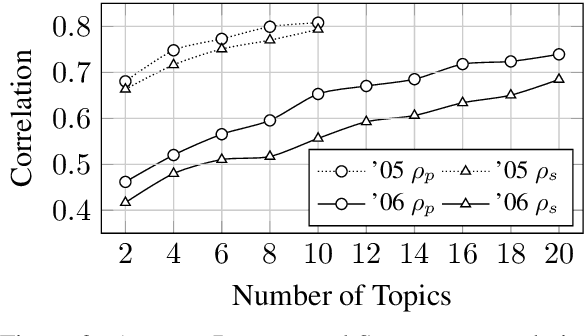
Conducting a manual evaluation is considered an essential part of summary evaluation methodology. Traditionally, the Pyramid protocol, which exhaustively compares system summaries to references, has been perceived as very reliable, providing objective scores. Yet, due to the high cost of the Pyramid method and the required expertise, researchers resorted to cheaper and less thorough manual evaluation methods, such as Responsiveness and pairwise comparison, attainable via crowdsourcing. We revisit the Pyramid approach, proposing a lightweight sampling-based version that is crowdsourcable. We analyze the performance of our method in comparison to original expert-based Pyramid evaluations, showing higher correlation relative to the common Responsiveness method. We release our crowdsourced Summary-Content-Units, along with all crowdsourcing scripts, for future evaluations.
AutoSeM: Automatic Task Selection and Mixing in Multi-Task Learning
Apr 08, 2019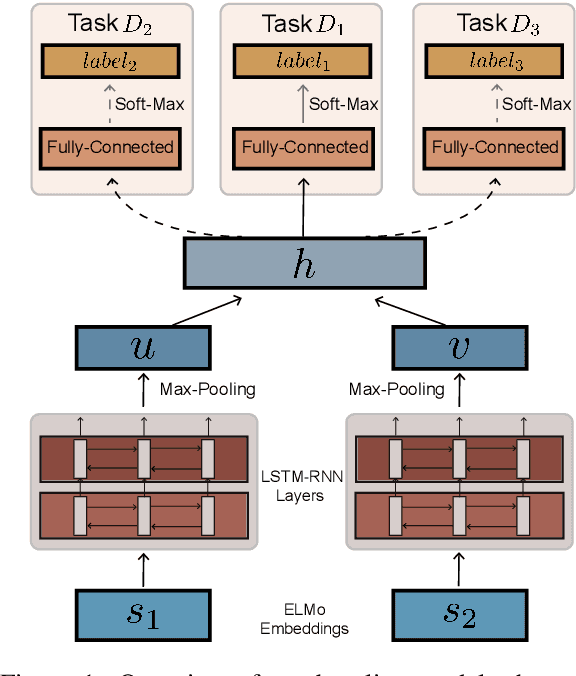

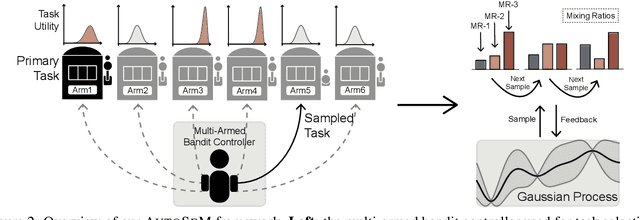
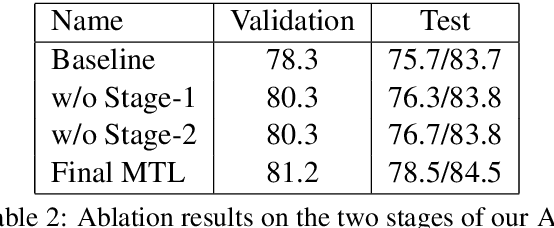
Multi-task learning (MTL) has achieved success over a wide range of problems, where the goal is to improve the performance of a primary task using a set of relevant auxiliary tasks. However, when the usefulness of the auxiliary tasks w.r.t. the primary task is not known a priori, the success of MTL models depends on the correct choice of these auxiliary tasks and also a balanced mixing ratio of these tasks during alternate training. These two problems could be resolved via manual intuition or hyper-parameter tuning over all combinatorial task choices, but this introduces inductive bias or is not scalable when the number of candidate auxiliary tasks is very large. To address these issues, we present AutoSeM, a two-stage MTL pipeline, where the first stage automatically selects the most useful auxiliary tasks via a Beta-Bernoulli multi-armed bandit with Thompson Sampling, and the second stage learns the training mixing ratio of these selected auxiliary tasks via a Gaussian Process based Bayesian optimization framework. We conduct several MTL experiments on the GLUE language understanding tasks, and show that our AutoSeM framework can successfully find relevant auxiliary tasks and automatically learn their mixing ratio, achieving significant performance boosts on several primary tasks. Finally, we present ablations for each stage of AutoSeM and analyze the learned auxiliary task choices.
Game-Based Video-Context Dialogue
Oct 17, 2018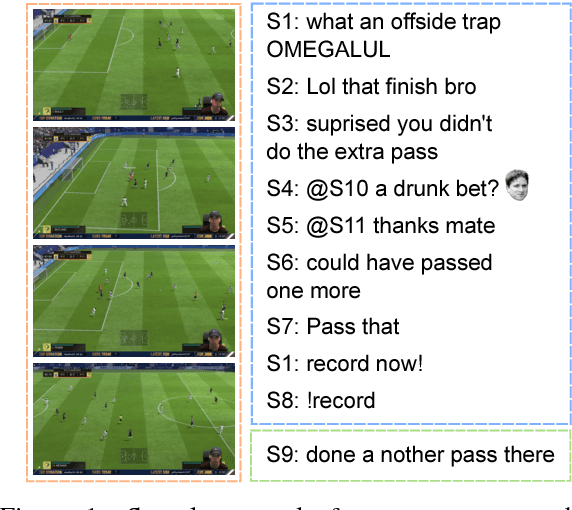

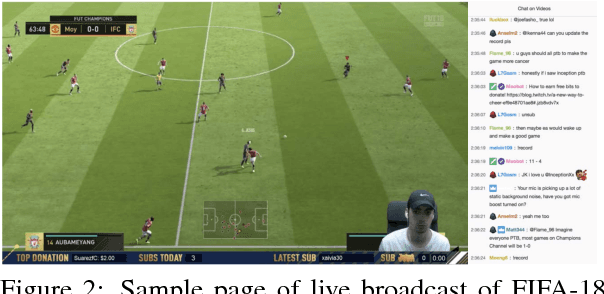
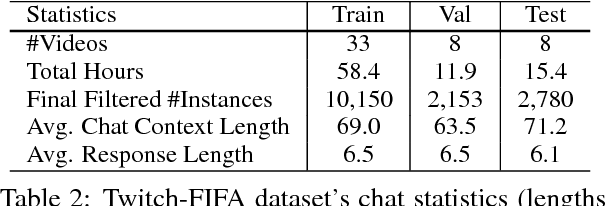
Current dialogue systems focus more on textual and speech context knowledge and are usually based on two speakers. Some recent work has investigated static image-based dialogue. However, several real-world human interactions also involve dynamic visual context (similar to videos) as well as dialogue exchanges among multiple speakers. To move closer towards such multimodal conversational skills and visually-situated applications, we introduce a new video-context, many-speaker dialogue dataset based on live-broadcast soccer game videos and chats from Twitch.tv. This challenging testbed allows us to develop visually-grounded dialogue models that should generate relevant temporal and spatial event language from the live video, while also being relevant to the chat history. For strong baselines, we also present several discriminative and generative models, e.g., based on tridirectional attention flow (TriDAF). We evaluate these models via retrieval ranking-recall, automatic phrase-matching metrics, as well as human evaluation studies. We also present dataset analyses, model ablations, and visualizations to understand the contribution of different modalities and model components.
Dynamic Multi-Level Multi-Task Learning for Sentence Simplification
Jun 19, 2018



Sentence simplification aims to improve readability and understandability, based on several operations such as splitting, deletion, and paraphrasing. However, a valid simplified sentence should also be logically entailed by its input sentence. In this work, we first present a strong pointer-copy mechanism based sequence-to-sequence sentence simplification model, and then improve its entailment and paraphrasing capabilities via multi-task learning with related auxiliary tasks of entailment and paraphrase generation. Moreover, we propose a novel 'multi-level' layered soft sharing approach where each auxiliary task shares different (higher versus lower) level layers of the sentence simplification model, depending on the task's semantic versus lexico-syntactic nature. We also introduce a novel multi-armed bandit based training approach that dynamically learns how to effectively switch across tasks during multi-task learning. Experiments on multiple popular datasets demonstrate that our model outperforms competitive simplification systems in SARI and FKGL automatic metrics, and human evaluation. Further, we present several ablation analyses on alternative layer sharing methods, soft versus hard sharing, dynamic multi-armed bandit sampling approaches, and our model's learned entailment and paraphrasing skills.
Multi-Reward Reinforced Summarization with Saliency and Entailment
May 29, 2018
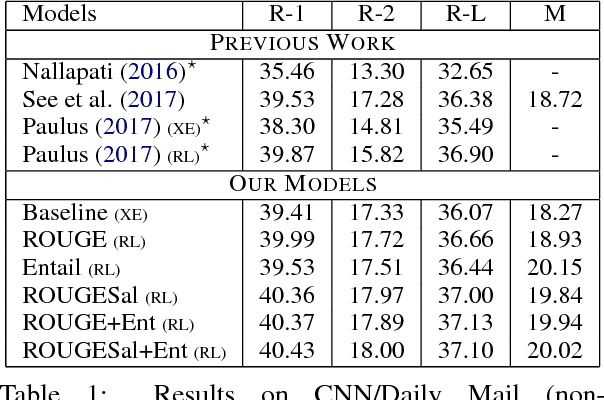
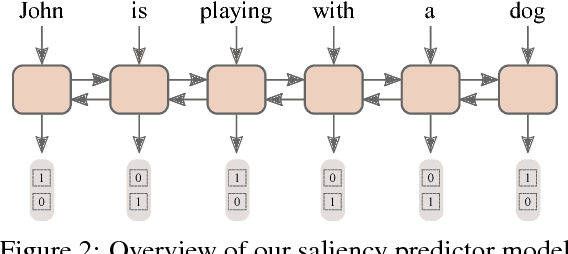
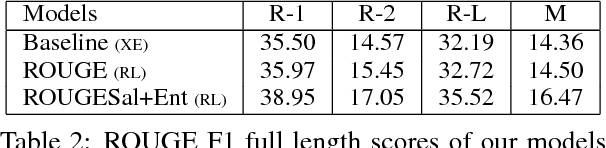
Abstractive text summarization is the task of compressing and rewriting a long document into a short summary while maintaining saliency, directed logical entailment, and non-redundancy. In this work, we address these three important aspects of a good summary via a reinforcement learning approach with two novel reward functions: ROUGESal and Entail, on top of a coverage-based baseline. The ROUGESal reward modifies the ROUGE metric by up-weighting the salient phrases/words detected via a keyphrase classifier. The Entail reward gives high (length-normalized) scores to logically-entailed summaries using an entailment classifier. Further, we show superior performance improvement when these rewards are combined with traditional metric (ROUGE) based rewards, via our novel and effective multi-reward approach of optimizing multiple rewards simultaneously in alternate mini-batches. Our method achieves the new state-of-the-art results (including human evaluation) on the CNN/Daily Mail dataset as well as strong improvements in a test-only transfer setup on DUC-2002.
Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation
May 28, 2018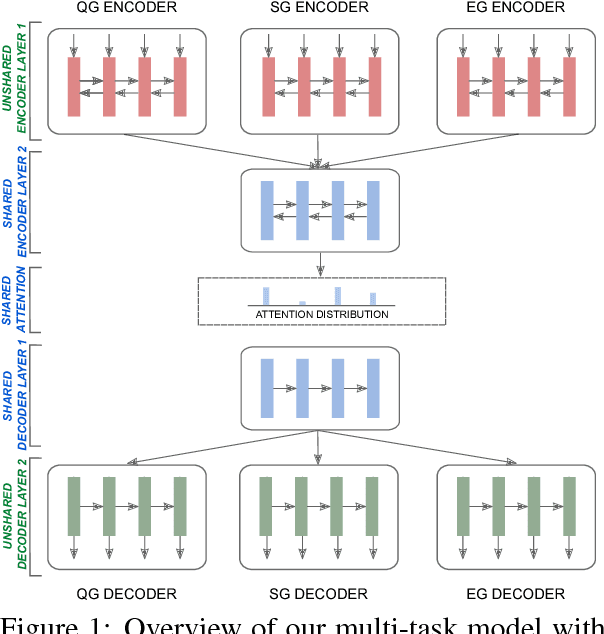
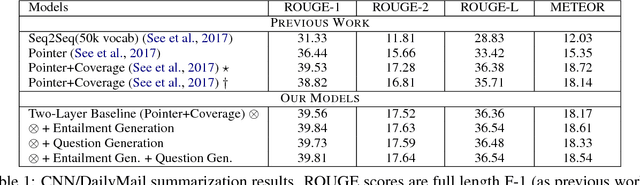
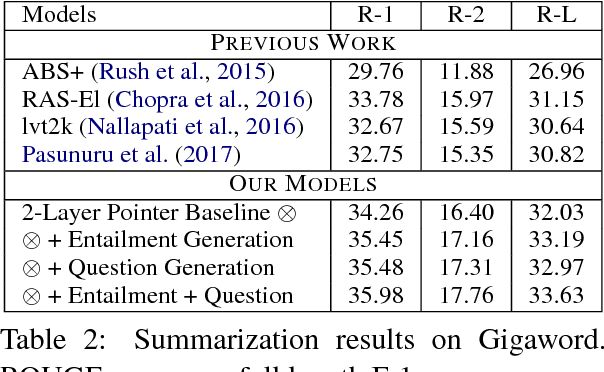
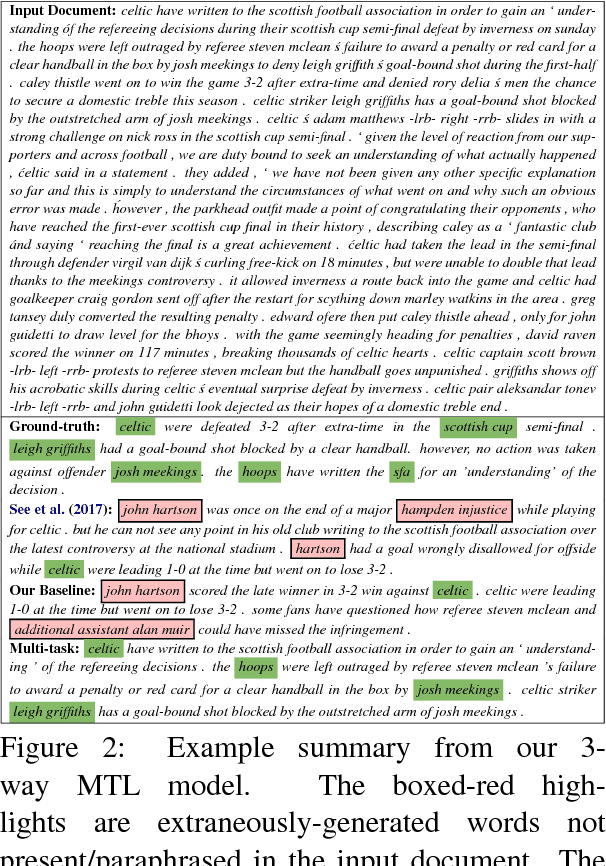
An accurate abstractive summary of a document should contain all its salient information and should be logically entailed by the input document. We improve these important aspects of abstractive summarization via multi-task learning with the auxiliary tasks of question generation and entailment generation, where the former teaches the summarization model how to look for salient questioning-worthy details, and the latter teaches the model how to rewrite a summary which is a directed-logical subset of the input document. We also propose novel multi-task architectures with high-level (semantic) layer-specific sharing across multiple encoder and decoder layers of the three tasks, as well as soft-sharing mechanisms (and show performance ablations and analysis examples of each contribution). Overall, we achieve statistically significant improvements over the state-of-the-art on both the CNN/DailyMail and Gigaword datasets, as well as on the DUC-2002 transfer setup. We also present several quantitative and qualitative analysis studies of our model's learned saliency and entailment skills.