 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-autoregressive End-to-end Approaches for Joint Automatic Speech Recognition and Spoken Language Understanding
Apr 21, 2023


This paper presents the use of non-autoregressive (NAR) approaches for joint automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. The proposed NAR systems employ a Conformer encoder that applies connectionist temporal classification (CTC) to transcribe the speech utterance into raw ASR hypotheses, which are further refined with a bidirectional encoder representations from Transformers (BERT)-like decoder. In the meantime, the intent and slot labels of the utterance are predicted simultaneously using the same decoder. Both Mask-CTC and self-conditioned CTC (SC-CTC) approaches are explored for this study. Experiments conducted on the SLURP dataset show that the proposed SC-Mask-CTC NAR system achieves 3.7% and 3.2% absolute gains in SLU metrics and a competitive level of ASR accuracy, when compared to a Conformer-Transformer based autoregressive (AR) model. Additionally, the NAR systems achieve 6x faster decoding speed than the AR baseline.
Multiple-hypothesis RNN-T Loss for Unsupervised Fine-tuning and Self-training of Neural Transducer
Jul 29, 2022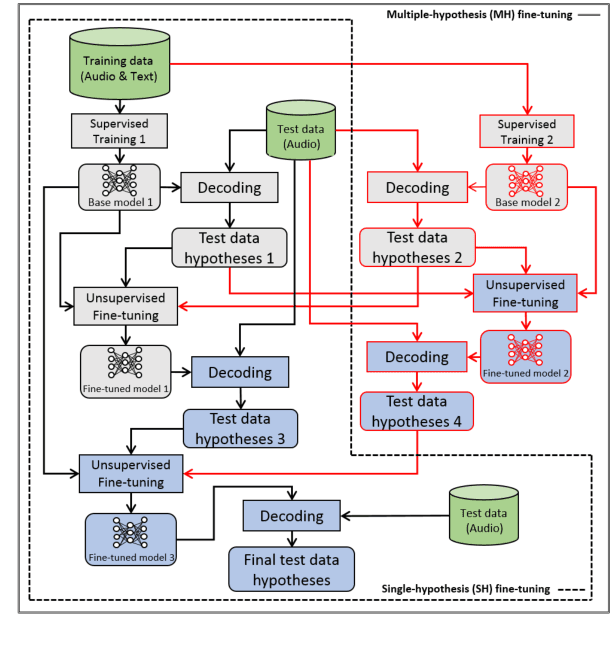
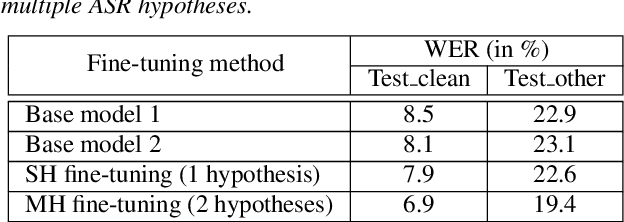
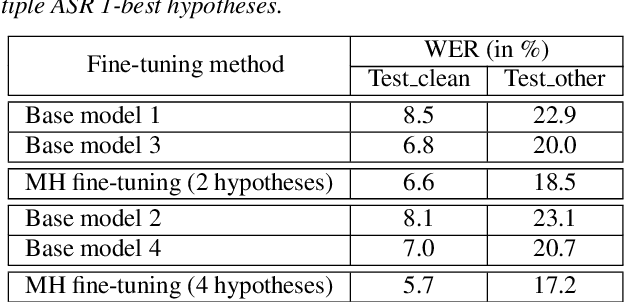
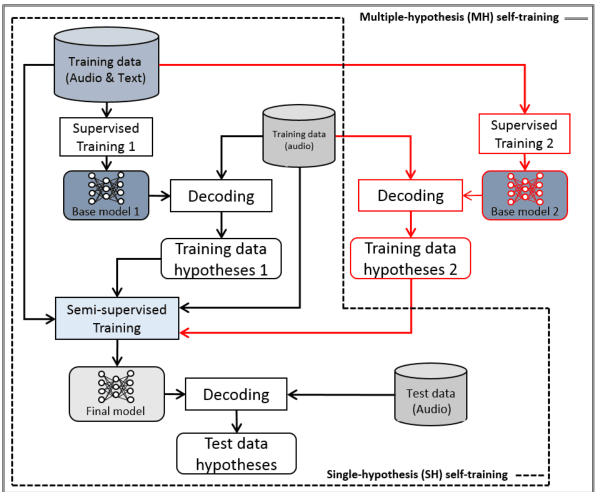
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.
Speaker Reinforcement Using Target Source Extraction for Robust Automatic Speech Recognition
May 09, 2022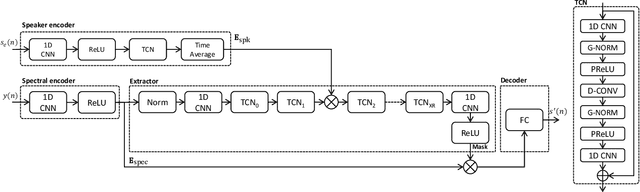

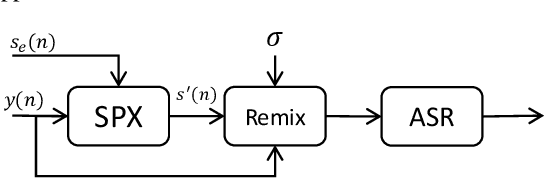
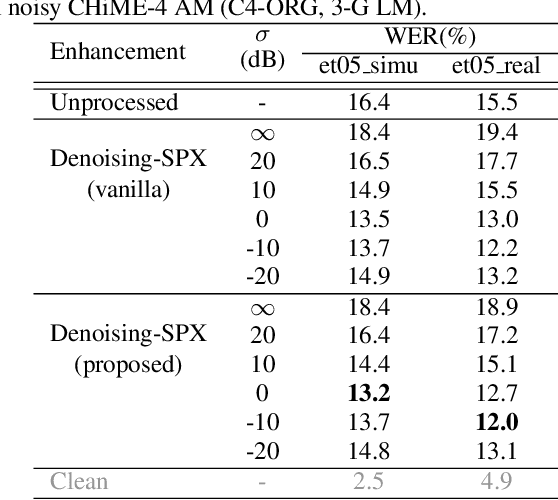
Improving the accuracy of single-channel automatic speech recognition (ASR) in noisy conditions is challenging. Strong speech enhancement front-ends are available, however, they typically require that the ASR model is retrained to cope with the processing artifacts. In this paper we explore a speaker reinforcement strategy for improving recognition performance without retraining the acoustic model (AM). This is achieved by remixing the enhanced signal with the unprocessed input to alleviate the processing artifacts. We evaluate the proposed approach using a DNN speaker extraction based speech denoiser trained with a perceptually motivated loss function. Results show that (without AM retraining) our method yields about 23% and 25% relative accuracy gains compared with the unprocessed for the monoaural simulated and real CHiME-4 evaluation sets, respectively, and outperforms a state-of-the-art reference method.
On monoaural speech enhancement for automatic recognition of real noisy speech using mixture invariant training
May 03, 2022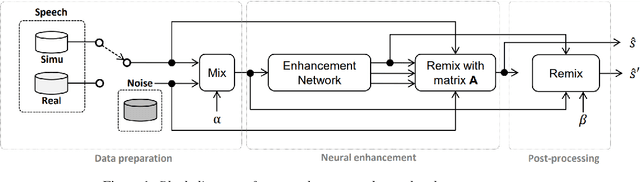
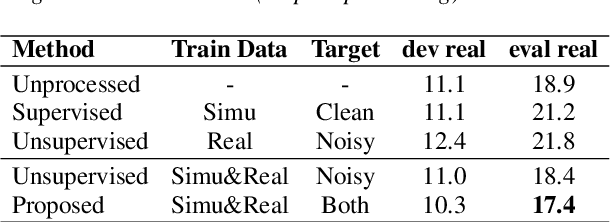
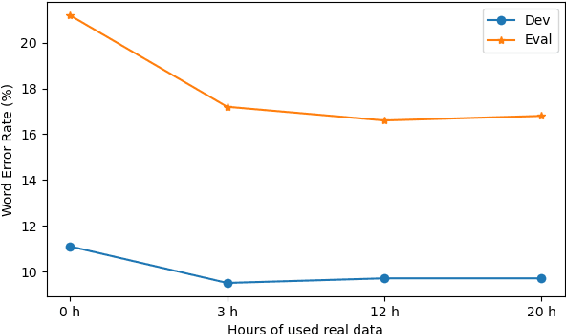
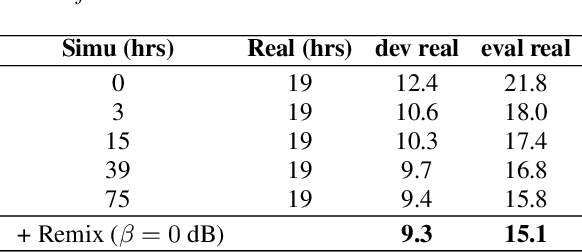
In this paper, we explore an improved framework to train a monoaural neural enhancement model for robust speech recognition. The designed training framework extends the existing mixture invariant training criterion to exploit both unpaired clean speech and real noisy data. It is found that the unpaired clean speech is crucial to improve quality of separated speech from real noisy speech. The proposed method also performs remixing of processed and unprocessed signals to alleviate the processing artifacts. Experiments on the single-channel CHiME-3 real test sets show that the proposed method improves significantly in terms of speech recognition performance over the enhancement system trained either on the mismatched simulated data in a supervised fashion or on the matched real data in an unsupervised fashion. Between 16% and 39% relative WER reduction has been achieved by the proposed system compared to the unprocessed signal using end-to-end and hybrid acoustic models without retraining on distorted data.
Dialogue Strategy Adaptation to New Action Sets Using Multi-dimensional Modelling
Apr 14, 2022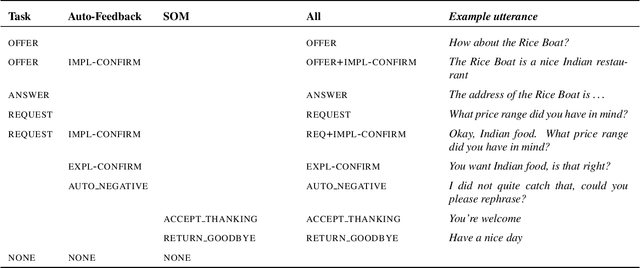
A major bottleneck for building statistical spoken dialogue systems for new domains and applications is the need for large amounts of training data. To address this problem, we adopt the multi-dimensional approach to dialogue management and evaluate its potential for transfer learning. Specifically, we exploit pre-trained task-independent policies to speed up training for an extended task-specific action set, in which the single summary action for requesting a slot is replaced by multiple slot-specific request actions. Policy optimisation and evaluation experiments using an agenda-based user simulator show that with limited training data, much better performance levels can be achieved when using the proposed multi-dimensional adaptation method. We confirm this improvement in a crowd-sourced human user evaluation of our spoken dialogue system, comparing partially trained policies. The multi-dimensional system (with adaptation on limited training data in the target scenario) outperforms the one-dimensional baseline (without adaptation on the same amount of training data) by 7% perceived success rate.
Transformer-based Streaming ASR with Cumulative Attention
Mar 11, 2022
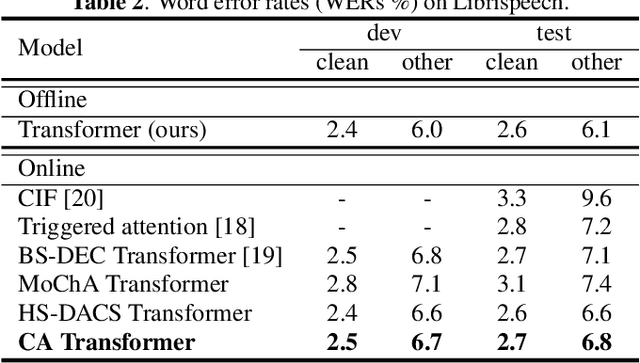
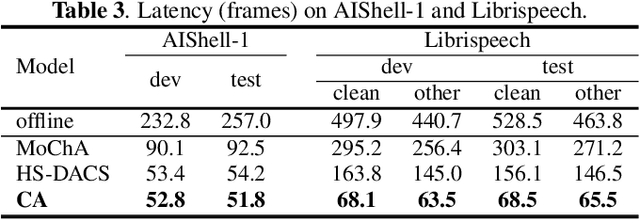
In this paper, we propose an online attention mechanism, known as cumulative attention (CA), for streaming Transformer-based automatic speech recognition (ASR). Inspired by monotonic chunkwise attention (MoChA) and head-synchronous decoder-end adaptive computation steps (HS-DACS) algorithms, CA triggers the ASR outputs based on the acoustic information accumulated at each encoding timestep, where the decisions are made using a trainable device, referred to as halting selector. In CA, all the attention heads of the same decoder layer are synchronised to have a unified halting position. This feature effectively alleviates the problem caused by the distinct behaviour of individual heads, which may otherwise give rise to severe latency issues as encountered by MoChA. The ASR experiments conducted on AIShell-1 and Librispeech datasets demonstrate that the proposed CA-based Transformer system can achieve on par or better performance with significant reduction in latency during inference, when compared to other streaming Transformer systems in literature.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022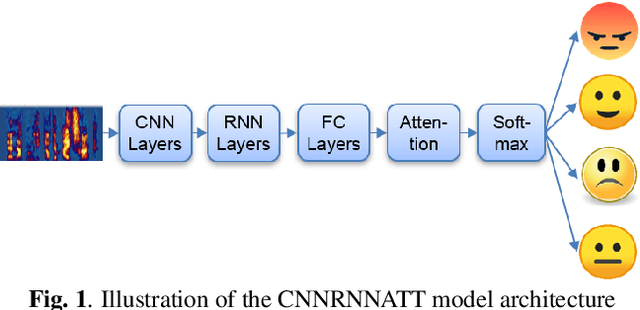
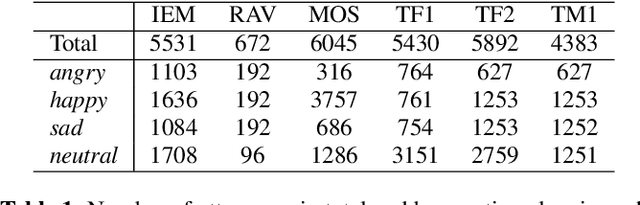

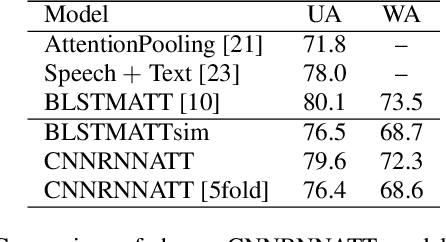
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.
Monaural source separation: From anechoic to reverberant environments
Nov 15, 2021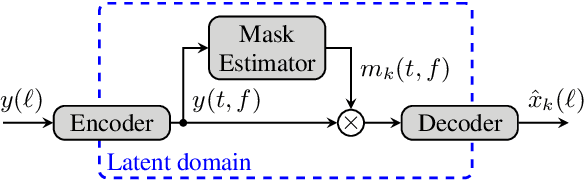
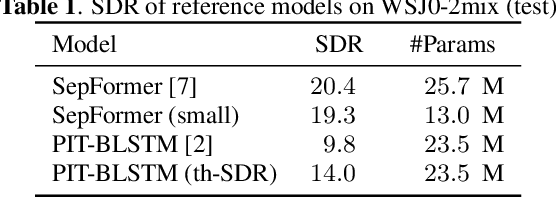
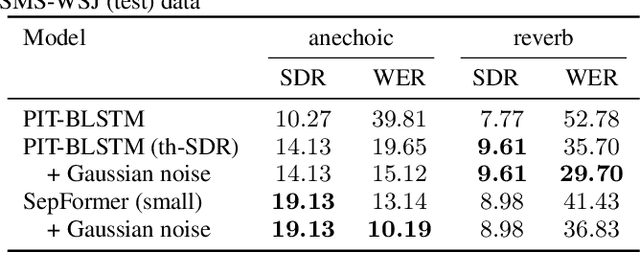
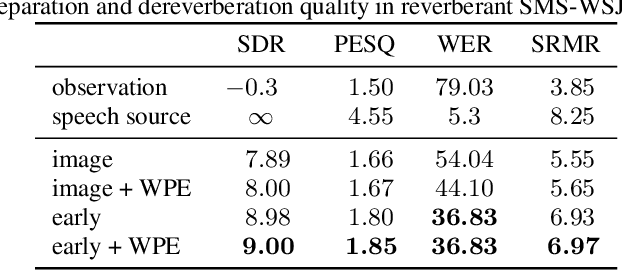
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.
Towards Handling Unconstrained User Preferences in Dialogue
Sep 17, 2021

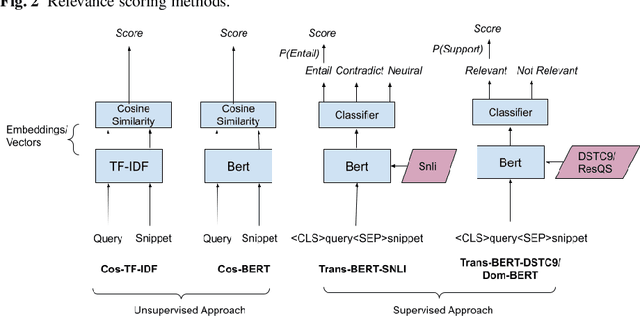
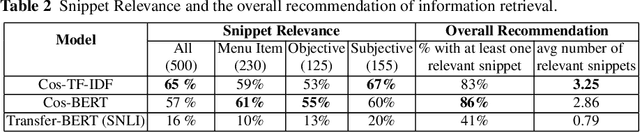
A user input to a schema-driven dialogue information navigation system, such as venue search, is typically constrained by the underlying database which restricts the user to specify a predefined set of preferences, or slots, corresponding to the database fields. We envision a more natural information navigation dialogue interface where a user has flexibility to specify unconstrained preferences that may not match a predefined schema. We propose to use information retrieval from unstructured knowledge to identify entities relevant to a user request. We update the Cambridge restaurants database with unstructured knowledge snippets (reviews and information from the web) for each of the restaurants and annotate a set of query-snippet pairs with a relevance label. We use the annotated dataset to train and evaluate snippet relevance classifiers, as a proxy to evaluating recommendation accuracy. We show that with a pretrained transformer model as an encoder, an unsupervised/supervised classifier achieves a weighted F1 of .661/.856.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021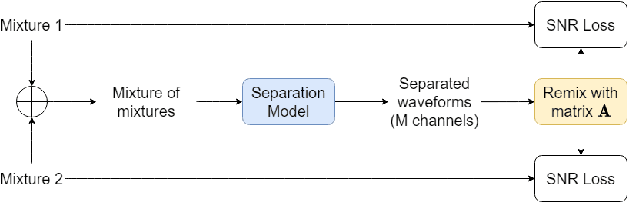
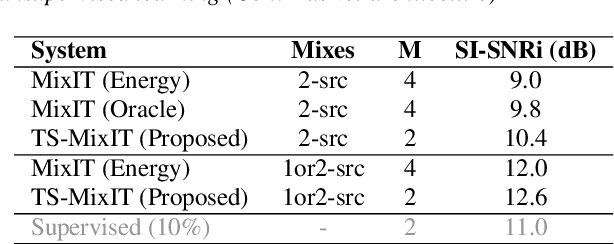
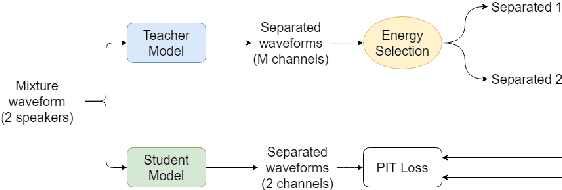
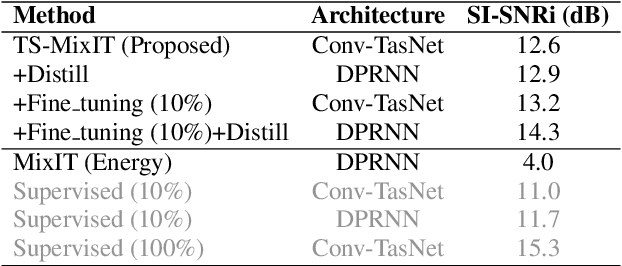
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.