 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Neuroscience for AI: How integrating Actions, Compositional Structure and Episodic Memory could enable Safe, Interpretable and Human-Like AI
Dec 27, 2025The phenomenal advances in large language models (LLMs) and other foundation models over the past few years have been based on optimizing large-scale transformer models on the surprisingly simple objective of minimizing next-token prediction loss, a form of predictive coding that is also the backbone of an increasingly popular model of brain function in neuroscience and cognitive science. However, current foundation models ignore three other important components of state-of-the-art predictive coding models: tight integration of actions with generative models, hierarchical compositional structure, and episodic memory. We propose that to achieve safe, interpretable, energy-efficient, and human-like AI, foundation models should integrate actions, at multiple scales of abstraction, with a compositional generative architecture and episodic memory. We present recent evidence from neuroscience and cognitive science on the importance of each of these components. We describe how the addition of these missing components to foundation models could help address some of their current deficiencies: hallucinations and superficial understanding of concepts due to lack of grounding, a missing sense of agency/responsibility due to lack of control, threats to safety and trustworthiness due to lack of interpretability, and energy inefficiency. We compare our proposal to current trends, such as adding chain-of-thought (CoT) reasoning and retrieval-augmented generation (RAG) to foundation models, and discuss new ways of augmenting these models with brain-inspired components. We conclude by arguing that a rekindling of the historically fruitful exchange of ideas between brain science and AI will help pave the way towards safe and interpretable human-centered AI.
Mixed Density Diffuser: Efficient Planning with Non-uniform Temporal Resolution
Oct 27, 2025Recent studies demonstrate that diffusion planners benefit from sparse-step planning over single-step planning. Training models to skip steps in their trajectories helps capture long-term dependencies without additional or memory computational cost. However, predicting excessively sparse plans degrades performance. We hypothesize this temporal density threshold is non-uniform across a temporal horizon and that certain parts of a planned trajectory should be more densely planned. We propose Mixed Density Diffuser (MDD), a diffusion planner where the densities throughout the horizon are tunable hyperparameters. MDD achieves a new SOTA across the Maze2D, Franka Kitchen, and Antmaze D4RL task domains.
Culturally-Attuned Moral Machines: Implicit Learning of Human Value Systems by AI through Inverse Reinforcement Learning
Dec 29, 2023Constructing a universal moral code for artificial intelligence (AI) is difficult or even impossible, given that different human cultures have different definitions of morality and different societal norms. We therefore argue that the value system of an AI should be culturally attuned: just as a child raised in a particular culture learns the specific values and norms of that culture, we propose that an AI agent operating in a particular human community should acquire that community's moral, ethical, and cultural codes. How AI systems might acquire such codes from human observation and interaction has remained an open question. Here, we propose using inverse reinforcement learning (IRL) as a method for AI agents to acquire a culturally-attuned value system implicitly. We test our approach using an experimental paradigm in which AI agents use IRL to learn different reward functions, which govern the agents' moral values, by observing the behavior of different cultural groups in an online virtual world requiring real-time decision making. We show that an AI agent learning from the average behavior of a particular cultural group can acquire altruistic characteristics reflective of that group's behavior, and this learned value system can generalize to new scenarios requiring altruistic judgments. Our results provide, to our knowledge, the first demonstration that AI agents could potentially be endowed with the ability to continually learn their values and norms from observing and interacting with humans, thereby becoming attuned to the culture they are operating in.
Expressive probabilistic sampling in recurrent neural networks
Aug 22, 2023In sampling-based Bayesian models of brain function, neural activities are assumed to be samples from probability distributions that the brain uses for probabilistic computation. However, a comprehensive understanding of how mechanistic models of neural dynamics can sample from arbitrary distributions is still lacking. We use tools from functional analysis and stochastic differential equations to explore the minimum architectural requirements for $\textit{recurrent}$ neural circuits to sample from complex distributions. We first consider the traditional sampling model consisting of a network of neurons whose outputs directly represent the samples (sampler-only network). We argue that synaptic current and firing-rate dynamics in the traditional model have limited capacity to sample from a complex probability distribution. We show that the firing rate dynamics of a recurrent neural circuit with a separate set of output units can sample from an arbitrary probability distribution. We call such circuits reservoir-sampler networks (RSNs). We propose an efficient training procedure based on denoising score matching that finds recurrent and output weights such that the RSN implements Langevin sampling. We empirically demonstrate our model's ability to sample from several complex data distributions using the proposed neural dynamics and discuss its applicability to developing the next generation of sampling-based brain models.
Brain-Inspired Computational Intelligence via Predictive Coding
Aug 15, 2023



Artificial intelligence (AI) is rapidly becoming one of the key technologies of this century. The majority of results in AI thus far have been achieved using deep neural networks trained with the error backpropagation learning algorithm. However, the ubiquitous adoption of this approach has highlighted some important limitations such as substantial computational cost, difficulty in quantifying uncertainty, lack of robustness, unreliability, and biological implausibility. It is possible that addressing these limitations may require schemes that are inspired and guided by neuroscience theories. One such theory, called predictive coding (PC), has shown promising performance in machine intelligence tasks, exhibiting exciting properties that make it potentially valuable for the machine learning community: PC can model information processing in different brain areas, can be used in cognitive control and robotics, and has a solid mathematical grounding in variational inference, offering a powerful inversion scheme for a specific class of continuous-state generative models. With the hope of foregrounding research in this direction, we survey the literature that has contributed to this perspective, highlighting the many ways that PC might play a role in the future of machine learning and computational intelligence at large.
Active Predictive Coding: A Unified Neural Framework for Learning Hierarchical World Models for Perception and Planning
Oct 23, 2022



Predictive coding has emerged as a prominent model of how the brain learns through predictions, anticipating the importance accorded to predictive learning in recent AI architectures such as transformers. Here we propose a new framework for predictive coding called active predictive coding which can learn hierarchical world models and solve two radically different open problems in AI: (1) how do we learn compositional representations, e.g., part-whole hierarchies, for equivariant vision? and (2) how do we solve large-scale planning problems, which are hard for traditional reinforcement learning, by composing complex action sequences from primitive policies? Our approach exploits hypernetworks, self-supervised learning and reinforcement learning to learn hierarchical world models that combine task-invariant state transition networks and task-dependent policy networks at multiple abstraction levels. We demonstrate the viability of our approach on a variety of vision datasets (MNIST, FashionMNIST, Omniglot) as well as on a scalable hierarchical planning problem. Our results represent, to our knowledge, the first demonstration of a unified solution to the part-whole learning problem posed by Hinton, the nested reference frames problem posed by Hawkins, and the integrated state-action hierarchy learning problem in reinforcement learning.
Hyper-Universal Policy Approximation: Learning to Generate Actions from a Single Image using Hypernets
Jul 07, 2022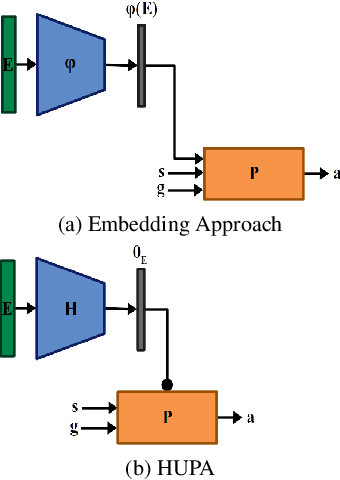
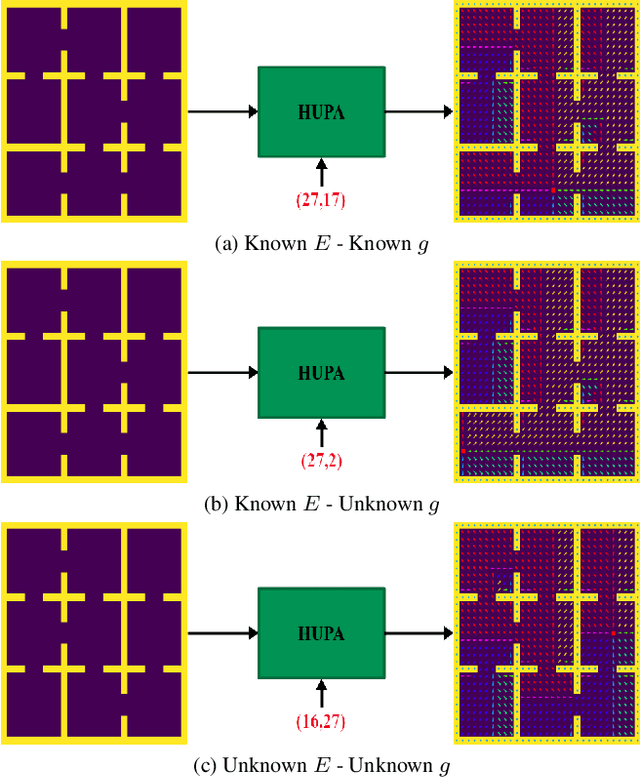
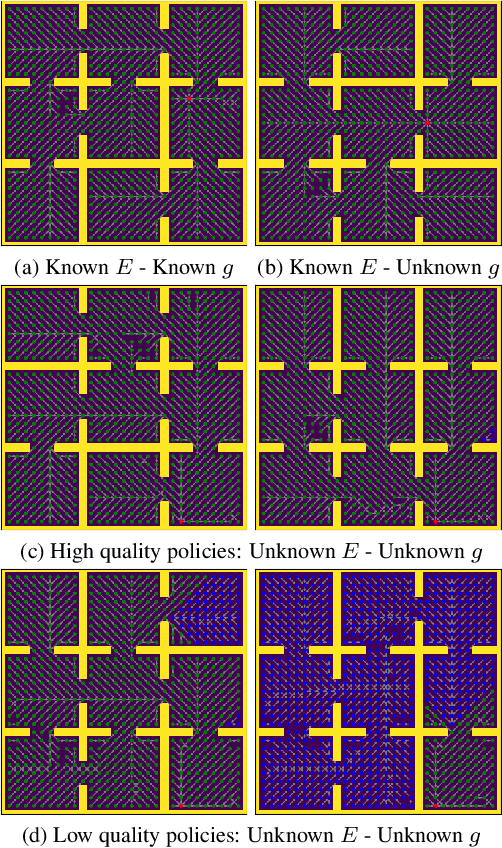
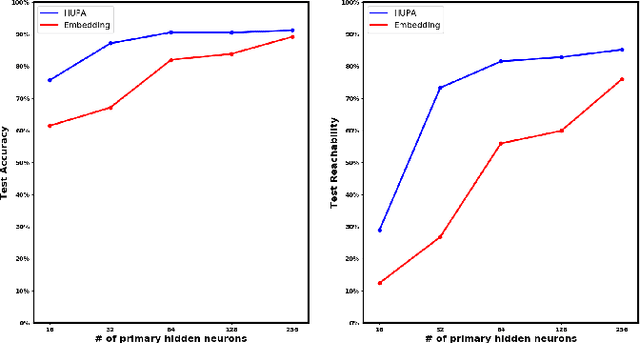
Inspired by Gibson's notion of object affordances in human vision, we ask the question: how can an agent learn to predict an entire action policy for a novel object or environment given only a single glimpse? To tackle this problem, we introduce the concept of Universal Policy Functions (UPFs) which are state-to-action mappings that generalize not only to new goals but most importantly to novel, unseen environments. Specifically, we consider the problem of efficiently learning such policies for agents with limited computational and communication capacity, constraints that are frequently encountered in edge devices. We propose the Hyper-Universal Policy Approximator (HUPA), a hypernetwork-based model to generate small task- and environment-conditional policy networks from a single image, with good generalization properties. Our results show that HUPAs significantly outperform an embedding-based alternative for generated policies that are size-constrained. Although this work is restricted to a simple map-based navigation task, future work includes applying the principles behind HUPAs to learning more general affordances for objects and environments.
Recursive Neural Programs: Variational Learning of Image Grammars and Part-Whole Hierarchies
Jun 26, 2022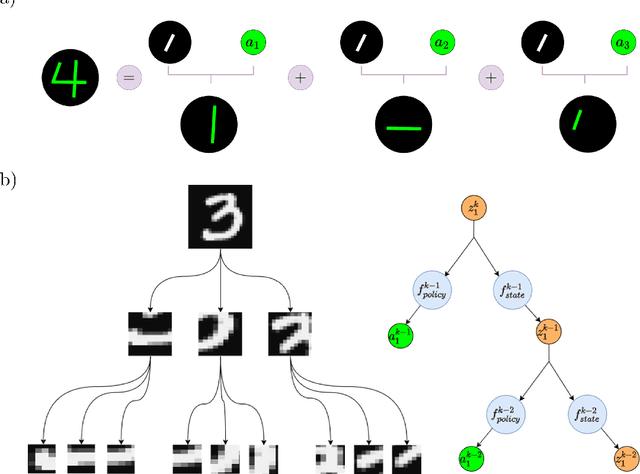
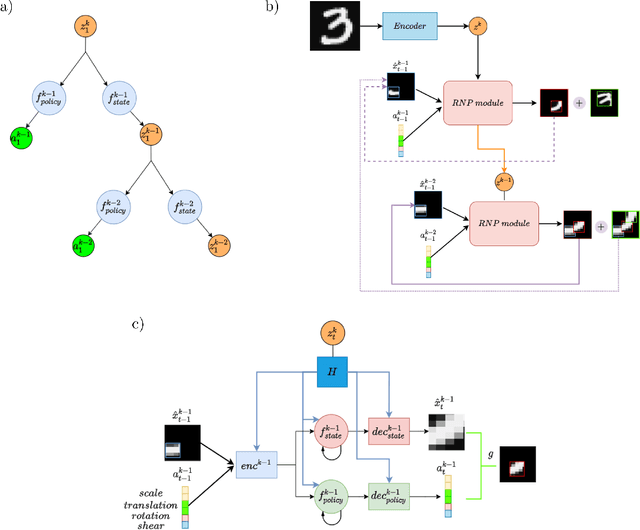


Human vision involves parsing and representing objects and scenes using structured representations based on part-whole hierarchies. Computer vision and machine learning researchers have recently sought to emulate this capability using capsule networks, reference frames and active predictive coding, but a generative model formulation has been lacking. We introduce Recursive Neural Programs (RNPs), which, to our knowledge, is the first neural generative model to address the part-whole hierarchy learning problem. RNPs model images as hierarchical trees of probabilistic sensory-motor programs that recursively reuse learned sensory-motor primitives to model an image within different reference frames, forming recursive image grammars. We express RNPs as structured variational autoencoders (sVAEs) for inference and sampling, and demonstrate parts-based parsing, sampling and one-shot transfer learning for MNIST, Omniglot and Fashion-MNIST datasets, demonstrating the model's expressive power. Our results show that RNPs provide an intuitive and explainable way of composing objects and scenes, allowing rich compositionality and intuitive interpretations of objects in terms of part-whole hierarchies.
Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies
Jan 14, 2022We introduce Active Predictive Coding Networks (APCNs), a new class of neural networks that solve a major problem posed by Hinton and others in the fields of artificial intelligence and brain modeling: how can neural networks learn intrinsic reference frames for objects and parse visual scenes into part-whole hierarchies by dynamically allocating nodes in a parse tree? APCNs address this problem by using a novel combination of ideas: (1) hypernetworks are used for dynamically generating recurrent neural networks that predict parts and their locations within intrinsic reference frames conditioned on higher object-level embedding vectors, and (2) reinforcement learning is used in conjunction with backpropagation for end-to-end learning of model parameters. The APCN architecture lends itself naturally to multi-level hierarchical learning and is closely related to predictive coding models of cortical function. Using the MNIST, Fashion-MNIST and Omniglot datasets, we demonstrate that APCNs can (a) learn to parse images into part-whole hierarchies, (b) learn compositional representations, and (c) transfer their knowledge to unseen classes of objects. With their ability to dynamically generate parse trees with part locations for objects, APCNs offer a new framework for explainable AI that leverages advances in deep learning while retaining interpretability and compositionality.
Emergent behavior and neural dynamics in artificial agents tracking turbulent plumes
Sep 25, 2021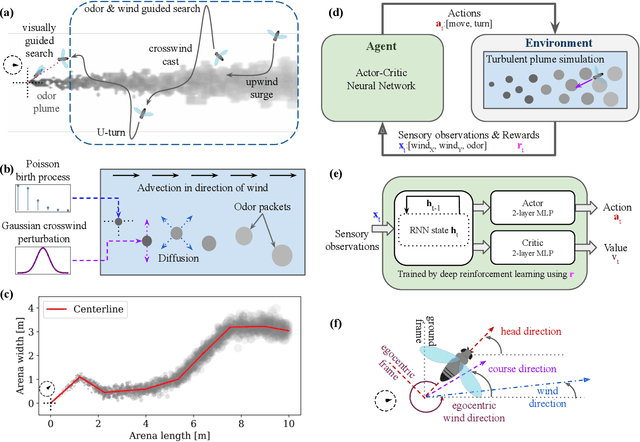
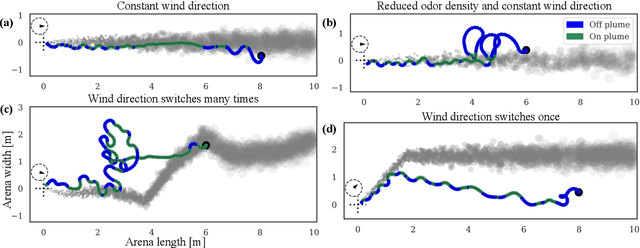
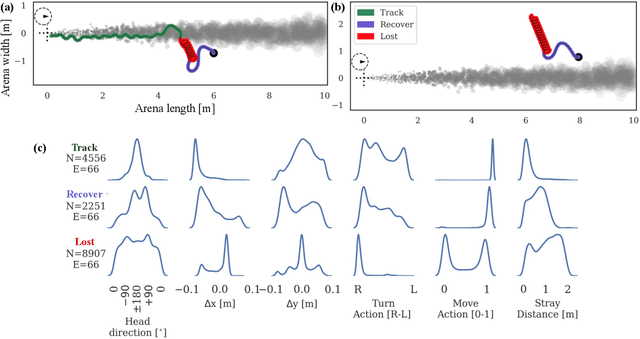
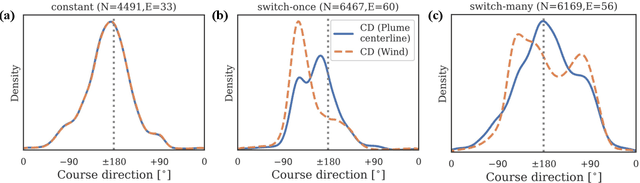
Tracking a turbulent plume to locate its source is a complex control problem because it requires multi-sensory integration and must be robust to intermittent odors, changing wind direction, and variable plume statistics. This task is routinely performed by flying insects, often over long distances, in pursuit of food or mates. Several aspects of this remarkable behavior have been studied in detail in many experimental studies. Here, we take a complementary in silico approach, using artificial agents trained with reinforcement learning to develop an integrated understanding of the behaviors and neural computations that support plume tracking. Specifically, we use deep reinforcement learning (DRL) to train recurrent neural network (RNN) agents to locate the source of simulated turbulent plumes. Interestingly, the agents' emergent behaviors resemble those of flying insects, and the RNNs learn to represent task-relevant variables, such as head direction and time since last odor encounter. Our analyses suggest an intriguing experimentally testable hypothesis for tracking plumes in changing wind direction -- that agents follow local plume shape rather than the current wind direction. While reflexive short-memory behaviors are sufficient for tracking plumes in constant wind, longer timescales of memory are essential for tracking plumes that switch direction. At the level of neural dynamics, the RNNs' population activity is low-dimensional and organized into distinct dynamical structures, with some correspondence to behavioral modules. Our in silico approach provides key intuitions for turbulent plume tracking strategies and motivates future targeted experimental and theoretical developments.