 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoteContrast: Contrastive Language-Diagnostic Pretraining for Medical Text
Dec 16, 2024Accurate diagnostic coding of medical notes is crucial for enhancing patient care, medical research, and error-free billing in healthcare organizations. Manual coding is a time-consuming task for providers, and diagnostic codes often exhibit low sensitivity and specificity, whereas the free text in medical notes can be a more precise description of a patients status. Thus, accurate automated diagnostic coding of medical notes has become critical for a learning healthcare system. Recent developments in long-document transformer architectures have enabled attention-based deep-learning models to adjudicate medical notes. In addition, contrastive loss functions have been used to jointly pre-train large language and image models with noisy labels. To further improve the automated adjudication of medical notes, we developed an approach based on i) models for ICD-10 diagnostic code sequences using a large real-world data set, ii) large language models for medical notes, and iii) contrastive pre-training to build an integrated model of both ICD-10 diagnostic codes and corresponding medical text. We demonstrate that a contrastive approach for pre-training improves performance over prior state-of-the-art models for the MIMIC-III-50, MIMIC-III-rare50, and MIMIC-III-full diagnostic coding tasks.
Automated and Interpretable Patient ECG Profiles for Disease Detection, Tracking, and Discovery
Jul 06, 2018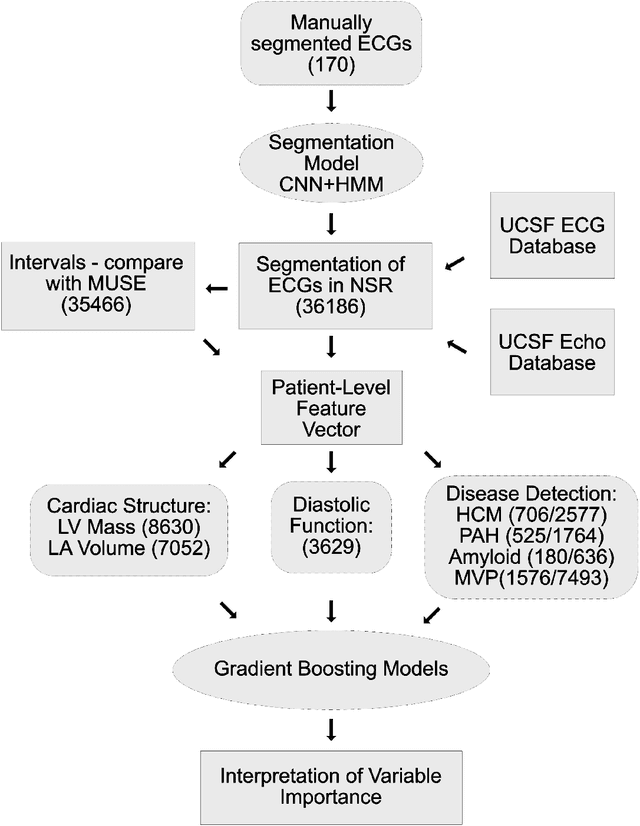
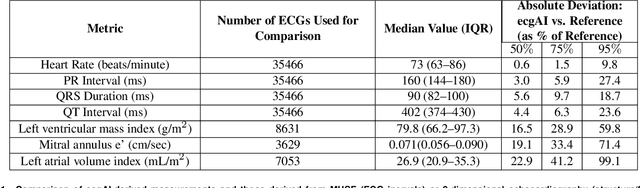
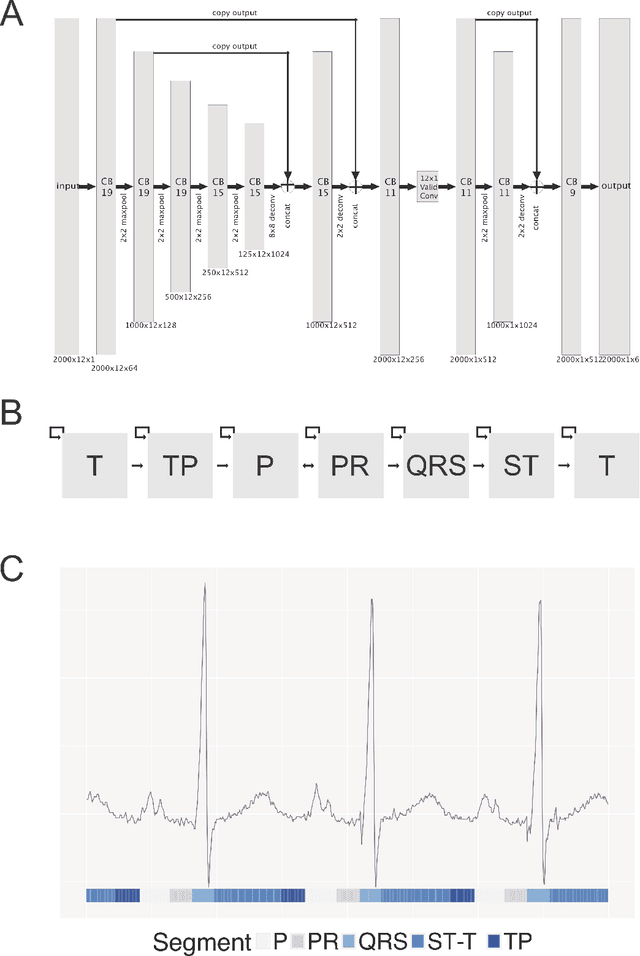
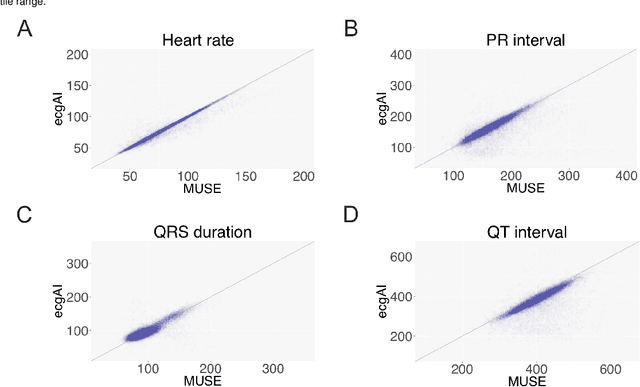
The electrocardiogram or ECG has been in use for over 100 years and remains the most widely performed diagnostic test to characterize cardiac structure and electrical activity. We hypothesized that parallel advances in computing power, innovations in machine learning algorithms, and availability of large-scale digitized ECG data would enable extending the utility of the ECG beyond its current limitations, while at the same time preserving interpretability, which is fundamental to medical decision-making. We identified 36,186 ECGs from the UCSF database that were 1) in normal sinus rhythm and 2) would enable training of specific models for estimation of cardiac structure or function or detection of disease. We derived a novel model for ECG segmentation using convolutional neural networks (CNN) and Hidden Markov Models (HMM) and evaluated its output by comparing electrical interval estimates to 141,864 measurements from the clinical workflow. We built a 725-element patient-level ECG profile using downsampled segmentation data and trained machine learning models to estimate left ventricular mass, left atrial volume, mitral annulus e' and to detect and track four diseases: pulmonary arterial hypertension (PAH), hypertrophic cardiomyopathy (HCM), cardiac amyloid (CA), and mitral valve prolapse (MVP). CNN-HMM derived ECG segmentation agreed with clinical estimates, with median absolute deviations (MAD) as a fraction of observed value of 0.6% for heart rate and 4% for QT interval. Patient-level ECG profiles enabled quantitative estimates of left ventricular and mitral annulus e' velocity with good discrimination in binary classification models of left ventricular hypertrophy and diastolic function. Models for disease detection ranged from AUROC of 0.94 to 0.77 for MVP. Top-ranked variables for all models included known ECG characteristics along with novel predictors of these traits/diseases.
A Computer Vision Pipeline for Automated Determination of Cardiac Structure and Function and Detection of Disease by Two-Dimensional Echocardiography
Jan 12, 2018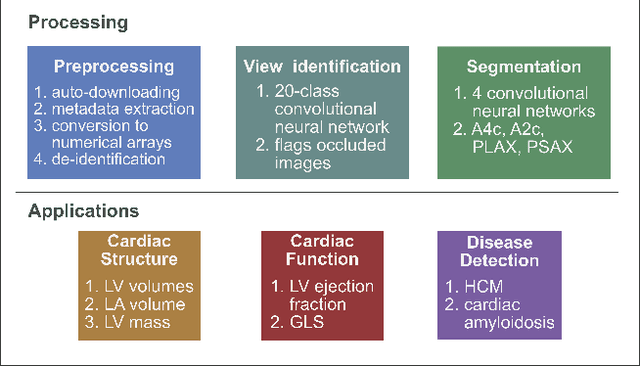
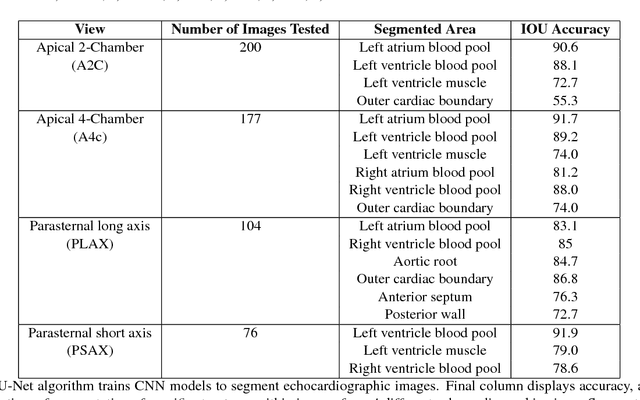
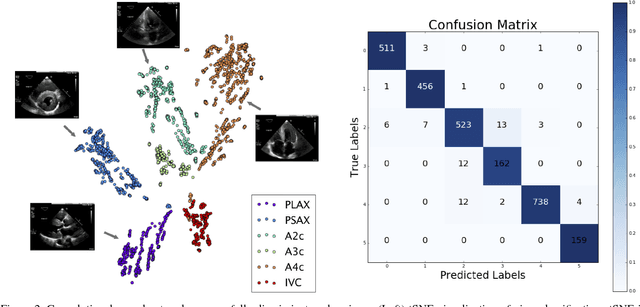
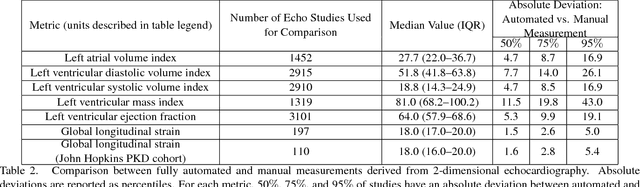
Automated cardiac image interpretation has the potential to transform clinical practice in multiple ways including enabling low-cost serial assessment of cardiac function in the primary care and rural setting. We hypothesized that advances in computer vision could enable building a fully automated, scalable analysis pipeline for echocardiogram (echo) interpretation. Our approach entailed: 1) preprocessing; 2) convolutional neural networks (CNN) for view identification, image segmentation, and phasing of the cardiac cycle; 3) quantification of chamber volumes and left ventricular mass; 4) particle tracking to compute longitudinal strain; and 5) targeted disease detection. CNNs accurately identified views (e.g. 99% for apical 4-chamber) and segmented individual cardiac chambers. Cardiac structure measurements agreed with study report values (e.g. mean absolute deviations (MAD) of 7.7 mL/kg/m2 for left ventricular diastolic volume index, 2918 studies). We computed automated ejection fraction and longitudinal strain measurements (within 2 cohorts), which agreed with commercial software-derived values [for ejection fraction, MAD=5.3%, N=3101 studies; for strain, MAD=1.5% (n=197) and 1.6% (n=110)], and demonstrated applicability to serial monitoring of breast cancer patients for trastuzumab cardiotoxicity. Overall, we found that, compared to manual measurements, automated measurements had superior performance across seven internal consistency metrics with an average increase in the Spearman correlation coefficient of 0.05 (p=0.02). Finally, we developed disease detection algorithms for hypertrophic cardiomyopathy and cardiac amyloidosis, with C-statistics of 0.93 and 0.84, respectively. Our pipeline lays the groundwork for using automated interpretation to support point-of-care handheld cardiac ultrasound and large-scale analysis of the millions of echos archived within healthcare systems.