 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMD-45: A Large-Scale CCTV Vehicle Detection Dataset for Urban Traffic in Developing Cities
Apr 27, 2026Robust vehicle detection from fixed CCTV cameras is critical for Intelligent Transportation Systems. Yet existing benchmarks predominantly feature relatively homogeneous, highly organized traffic patterns captured from ego-centric driving perspectives or controlled aerial views. This regional and sensor view bias creates a significant gap. Models trained on datasets such as UA-DETRAC and COCO struggle to generalize to the dense, heterogeneous, disorganized traffic conditions observed in rapidly developing urban centers in emerging economies. To address this limitation, we introduce BMD-45, a large-scale dataset comprising 480K bounding boxes annotated over 45K images captured from over 3.6K operational Safe City CCTV cameras. BMD-45 contains 14 fine-grained vehicle categories, including region-specific modes such as auto-rickshaws and tempo travellers, which are not present in existing benchmarks. The dataset captures real-world deployment challenges, including extreme viewpoint variation, occlusion, and vehicle density . We establish comprehensive baselines using state-of-the-art detectors and reveal a striking domain gap: models fine-tuned on UA-DETRAC achieve only 33.6% mAP@0.50:0.95, compared to 83.8% when trained in-domain on BMD-45, representing a 2.5x improvement that persists even when accounting for novel vehicle classes. This performance gap underscores the critical need for geographically diverse traffic benchmarks and establishes BMD-45 as a baseline for developing robust perception systems in underrepresented urban environments worldwide. The dataset is available at: https://huggingface.co/datasets/iisc-aim/BMD-45.
Autonomous Cooperative Multi-Vehicle System for Interception of Aerial and Stationary Targets in Unknown Environments
Sep 01, 2021This paper presents the design, development, and testing of hardware-software systems by the IISc-TCS team for Challenge 1 of the Mohammed Bin Zayed International Robotics Challenge 2020. The goal of Challenge 1 was to grab a ball suspended from a moving and maneuvering UAV and pop balloons anchored to the ground, using suitable manipulators. The important tasks carried out to address this challenge include the design and development of a hardware system with efficient grabbing and popping mechanisms, considering the restrictions in volume and payload, design of accurate target interception algorithms using visual information suitable for outdoor environments, and development of a software architecture for dynamic multi-agent aerial systems performing complex dynamic missions. In this paper, a single degree of freedom manipulator attached with an end-effector is designed for grabbing and popping, and robust algorithms are developed for the interception of targets in an uncertain environment. Vision-based guidance and tracking laws are proposed based on the concept of pursuit engagement and artificial potential function. The software architecture presented in this work proposes an Operation Management System (OMS) architecture that allocates static and dynamic tasks collaboratively among multiple UAVs to perform any given mission. An important aspect of this work is that all the systems developed were designed to operate in completely autonomous mode. A detailed description of the architecture along with simulations of complete challenge in the Gazebo environment and field experiment results are also included in this work. The proposed hardware-software system is particularly useful for counter-UAV systems and can also be modified in order to cater to several other applications.
Vision based Target Interception using Aerial Manipulation
Sep 28, 2020



Selective interception of objects in unknown environment autonomously by UAVs is an interesting problem. In this work, vision based interception is carried out. This problem is a part of challenge 1 of Mohammed Bin Zayed International Robotic Challenge, 2020, where, balloons are kept at five random locations for the UAVs to autonomously explore, detect, approach and intercept. The problem requires a different formulation to execute compared to the normal interception problems in literature. This work details the different aspect of this problem from vision to manipulator design. The frame work is implemented on hardware using Robot Operating System (ROS) communication architecture.
WYSIWYE: An Algebra for Expressing Spatial and Textual Rules for Visual Information Extraction
Sep 27, 2016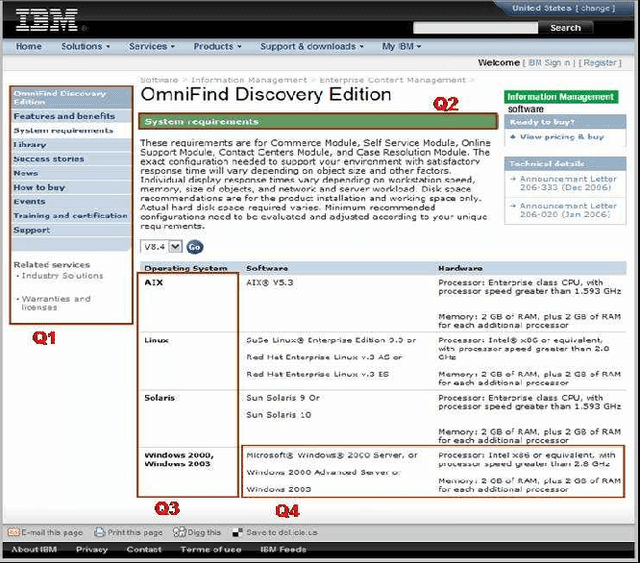
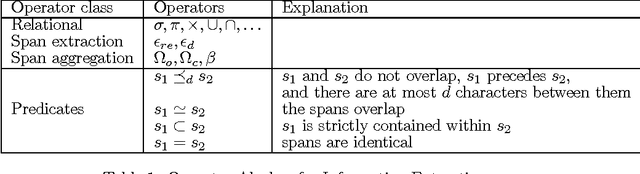

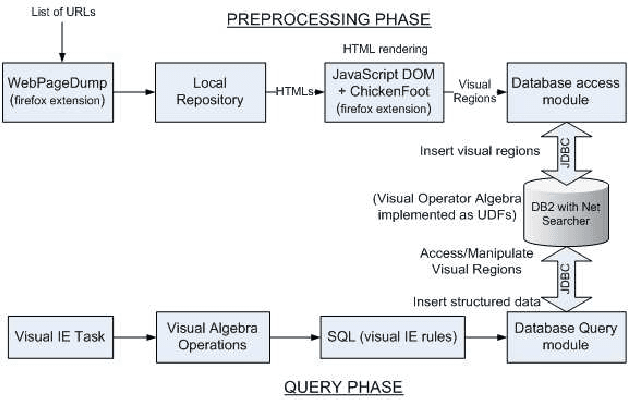
The visual layout of a webpage can provide valuable clues for certain types of Information Extraction (IE) tasks. In traditional rule based IE frameworks, these layout cues are mapped to rules that operate on the HTML source of the webpages. In contrast, we have developed a framework in which the rules can be specified directly at the layout level. This has many advantages, since the higher level of abstraction leads to simpler extraction rules that are largely independent of the source code of the page, and, therefore, more robust. It can also enable specification of new types of rules that are not otherwise possible. To the best of our knowledge, there is no general framework that allows declarative specification of information extraction rules based on spatial layout. Our framework is complementary to traditional text based rules framework and allows a seamless combination of spatial layout based rules with traditional text based rules. We describe the algebra that enables such a system and its efficient implementation using standard relational and text indexing features of a relational database. We demonstrate the simplicity and efficiency of this system for a task involving the extraction of software system requirements from software product pages.