 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Learning with Margin Guarantees
Apr 21, 2022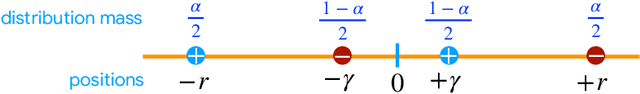
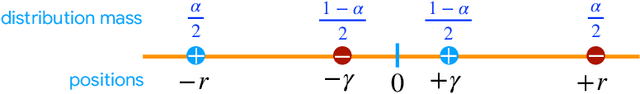
We present a series of new differentially private (DP) algorithms with dimension-independent margin guarantees. For the family of linear hypotheses, we give a pure DP learning algorithm that benefits from relative deviation margin guarantees, as well as an efficient DP learning algorithm with margin guarantees. We also present a new efficient DP learning algorithm with margin guarantees for kernel-based hypotheses with shift-invariant kernels, such as Gaussian kernels, and point out how our results can be extended to other kernels using oblivious sketching techniques. We further give a pure DP learning algorithm for a family of feed-forward neural networks for which we prove margin guarantees that are independent of the input dimension. Additionally, we describe a general label DP learning algorithm, which benefits from relative deviation margin bounds and is applicable to a broad family of hypothesis sets, including that of neural networks. Finally, we show how our DP learning algorithms can be augmented in a general way to include model selection, to select the best confidence margin parameter.
Differentially Private Stochastic Optimization: New Results in Convex and Non-Convex Settings
Jul 13, 2021
We study differentially private stochastic optimization in convex and non-convex settings. For the convex case, we focus on the family of non-smooth generalized linear losses (GLLs). Our algorithm for the $\ell_2$ setting achieves optimal excess population risk in near-linear time, while the best known differentially private algorithms for general convex losses run in super-linear time. Our algorithm for the $\ell_1$ setting has nearly-optimal excess population risk $\tilde{O}\big(\sqrt{\frac{\log{d}}{n}}\big)$, and circumvents the dimension dependent lower bound of [AFKT21] for general non-smooth convex losses. In the differentially private non-convex setting, we provide several new algorithms for approximating stationary points of the population risk. For the $\ell_1$-case with smooth losses and polyhedral constraint, we provide the first nearly dimension independent rate, $\tilde O\big(\frac{\log^{2/3}{d}}{{n^{1/3}}}\big)$ in linear time. For the constrained $\ell_2$-case, with smooth losses, we obtain a linear-time algorithm with rate $\tilde O\big(\frac{1}{n^{3/10}d^{1/10}}+\big(\frac{d}{n^2}\big)^{1/5}\big)$. Finally, for the $\ell_2$-case we provide the first method for {\em non-smooth weakly convex} stochastic optimization with rate $\tilde O\big(\frac{1}{n^{1/4}}+\big(\frac{d}{n^2}\big)^{1/6}\big)$ which matches the best existing non-private algorithm when $d= O(\sqrt{n})$. We also extend all our results above for the non-convex $\ell_2$ setting to the $\ell_p$ setting, where $1 < p \leq 2$, with only polylogarithmic (in the dimension) overhead in the rates.
Non-Euclidean Differentially Private Stochastic Convex Optimization
Mar 01, 2021
Differentially private (DP) stochastic convex optimization (SCO) is a fundamental problem, where the goal is to approximately minimize the population risk with respect to a convex loss function, given a dataset of i.i.d. samples from a distribution, while satisfying differential privacy with respect to the dataset. Most of the existing works in the literature of private convex optimization focus on the Euclidean (i.e., $\ell_2$) setting, where the loss is assumed to be Lipschitz (and possibly smooth) w.r.t. the $\ell_2$ norm over a constraint set with bounded $\ell_2$ diameter. Algorithms based on noisy stochastic gradient descent (SGD) are known to attain the optimal excess risk in this setting. In this work, we conduct a systematic study of DP-SCO for $\ell_p$-setups. For $p=1$, under a standard smoothness assumption, we give a new algorithm with nearly optimal excess risk. This result also extends to general polyhedral norms and feasible sets. For $p\in(1, 2)$, we give two new algorithms, whose central building block is a novel privacy mechanism, which generalizes the Gaussian mechanism. Moreover, we establish a lower bound on the excess risk for this range of $p$, showing a necessary dependence on $\sqrt{d}$, where $d$ is the dimension of the space. Our lower bound implies a sudden transition of the excess risk at $p=1$, where the dependence on $d$ changes from logarithmic to polynomial, resolving an open question in prior work [TTZ15] . For $p\in (2, \infty)$, noisy SGD attains optimal excess risk in the low-dimensional regime; in particular, this proves the optimality of noisy SGD for $p=\infty$. Our work draws upon concepts from the geometry of normed spaces, such as the notions of regularity, uniform convexity, and uniform smoothness.
Learning from Mixtures of Private and Public Populations
Aug 01, 2020We initiate the study of a new model of supervised learning under privacy constraints. Imagine a medical study where a dataset is sampled from a population of both healthy and unhealthy individuals. Suppose healthy individuals have no privacy concerns (in such case, we call their data "public") while the unhealthy individuals desire stringent privacy protection for their data. In this example, the population (data distribution) is a mixture of private (unhealthy) and public (healthy) sub-populations that could be very different. Inspired by the above example, we consider a model in which the population $\mathcal{D}$ is a mixture of two sub-populations: a private sub-population $\mathcal{D}_{\sf priv}$ of private and sensitive data, and a public sub-population $\mathcal{D}_{\sf pub}$ of data with no privacy concerns. Each example drawn from $\mathcal{D}$ is assumed to contain a privacy-status bit that indicates whether the example is private or public. The goal is to design a learning algorithm that satisfies differential privacy only with respect to the private examples. Prior works in this context assumed a homogeneous population where private and public data arise from the same distribution, and in particular designed solutions which exploit this assumption. We demonstrate how to circumvent this assumption by considering, as a case study, the problem of learning linear classifiers in $\mathbb{R}^d$. We show that in the case where the privacy status is correlated with the target label (as in the above example), linear classifiers in $\mathbb{R}^d$ can be learned, in the agnostic as well as the realizable setting, with sample complexity which is comparable to that of the classical (non-private) PAC-learning. It is known that this task is impossible if all the data is considered private.
Stability of Stochastic Gradient Descent on Nonsmooth Convex Losses
Jun 12, 2020
Uniform stability is a notion of algorithmic stability that bounds the worst case change in the model output by the algorithm when a single data point in the dataset is replaced. An influential work of Hardt et al. (2016) provides strong upper bounds on the uniform stability of the stochastic gradient descent (SGD) algorithm on sufficiently smooth convex losses. These results led to important progress in understanding of the generalization properties of SGD and several applications to differentially private convex optimization for smooth losses. Our work is the first to address uniform stability of SGD on {\em nonsmooth} convex losses. Specifically, we provide sharp upper and lower bounds for several forms of SGD and full-batch GD on arbitrary Lipschitz nonsmooth convex losses. Our lower bounds show that, in the nonsmooth case, (S)GD can be inherently less stable than in the smooth case. On the other hand, our upper bounds show that (S)GD is sufficiently stable for deriving new and useful bounds on generalization error. Most notably, we obtain the first dimension-independent generalization bounds for multi-pass SGD in the nonsmooth case. In addition, our bounds allow us to derive a new algorithm for differentially private nonsmooth stochastic convex optimization with optimal excess population risk. Our algorithm is simpler and more efficient than the best known algorithm for the nonsmooth case Feldman et al. (2020).
Private Query Release Assisted by Public Data
Apr 23, 2020
We study the problem of differentially private query release assisted by access to public data. In this problem, the goal is to answer a large class $\mathcal{H}$ of statistical queries with error no more than $\alpha$ using a combination of public and private samples. The algorithm is required to satisfy differential privacy only with respect to the private samples. We study the limits of this task in terms of the private and public sample complexities. First, we show that we can solve the problem for any query class $\mathcal{H}$ of finite VC-dimension using only $d/\alpha$ public samples and $\sqrt{p}d^{3/2}/\alpha^2$ private samples, where $d$ and $p$ are the VC-dimension and dual VC-dimension of $\mathcal{H}$, respectively. In comparison, with only private samples, this problem cannot be solved even for simple query classes with VC-dimension one, and without any private samples, a larger public sample of size $d/\alpha^2$ is needed. Next, we give sample complexity lower bounds that exhibit tight dependence on $p$ and $\alpha$. For the class of decision stumps, we give a lower bound of $\sqrt{p}/\alpha$ on the private sample complexity whenever the public sample size is less than $1/\alpha^2$. Given our upper bounds, this shows that the dependence on $\sqrt{p}$ is necessary in the private sample complexity. We also give a lower bound of $1/\alpha$ on the public sample complexity for a broad family of query classes, which by our upper bound, is tight in $\alpha$.
Limits of Private Learning with Access to Public Data
Oct 25, 2019We consider learning problems where the training set consists of two types of examples: private and public. The goal is to design a learning algorithm that satisfies differential privacy only with respect to the private examples. This setting interpolates between private learning (where all examples are private) and classical learning (where all examples are public). We study the limits of learning in this setting in terms of private and public sample complexities. We show that any hypothesis class of VC-dimension $d$ can be agnostically learned up to an excess error of $\alpha$ using only (roughly) $d/\alpha$ public examples and $d/\alpha^2$ private labeled examples. This result holds even when the public examples are unlabeled. This gives a quadratic improvement over the standard $d/\alpha^2$ upper bound on the public sample complexity (where private examples can be ignored altogether if the public examples are labeled). Furthermore, we give a nearly matching lower bound, which we prove via a generic reduction from this setting to the one of private learning without public data.
Private Stochastic Convex Optimization with Optimal Rates
Aug 27, 2019We study differentially private (DP) algorithms for stochastic convex optimization (SCO). In this problem the goal is to approximately minimize the population loss given i.i.d. samples from a distribution over convex and Lipschitz loss functions. A long line of existing work on private convex optimization focuses on the empirical loss and derives asymptotically tight bounds on the excess empirical loss. However a significant gap exists in the known bounds for the population loss. We show that, up to logarithmic factors, the optimal excess population loss for DP algorithms is equal to the larger of the optimal non-private excess population loss, and the optimal excess empirical loss of DP algorithms. This implies that, contrary to intuition based on private ERM, private SCO has asymptotically the same rate of $1/\sqrt{n}$ as non-private SCO in the parameter regime most common in practice. The best previous result in this setting gives rate of $1/n^{1/4}$. Our approach builds on existing differentially private algorithms and relies on the analysis of algorithmic stability to ensure generalization.
Privately Answering Classification Queries in the Agnostic PAC Model
Jul 31, 2019We revisit the problem of differentially private release of classification queries. In this problem, the goal is to design an algorithm that can accurately answer a sequence of classification queries based on a private training set while ensuring differential privacy. We formally study this problem in the agnostic PAC model and derive a new upper bound on the private sample complexity. Our results improve over those obtained in a recent work [BTT18] for the agnostic PAC setting. In particular, we give an improved construction that yields a tighter upper bound on the sample complexity. Moreover, unlike [BTT18], our accuracy guarantee does not involve any blow-up in the approximation error associated with the given hypothesis class. Given any hypothesis class with VC-dimension $d$, we show that our construction can privately answer up to $m$ classification queries with average excess error $\alpha$ using a private sample of size $\approx \frac{d}{\alpha^2}\max\left(1, \sqrt{m}\alpha^{3/2}\right)$. Using recent results on private learning with auxiliary public data, we extend our construction to show that one can privately answer any number of classification queries with average excess error $\alpha$ using a private sample of size $\approx \frac{d}{\alpha^2}\max\left(1, \sqrt{d} \alpha\right)$. Our results imply that when $\alpha$ is sufficiently small (high-accuracy regime), the private sample size is essentially the same as the non-private sample complexity of agnostic PAC learning.
On exponential convergence of SGD in non-convex over-parametrized learning
Nov 06, 2018Large over-parametrized models learned via stochastic gradient descent (SGD) methods have become a key element in modern machine learning. Although SGD methods are very effective in practice, most theoretical analyses of SGD suggest slower convergence than what is empirically observed. In our recent work [8] we analyzed how interpolation, common in modern over-parametrized learning, results in exponential convergence of SGD with constant step size for convex loss functions. In this note, we extend those results to a much broader non-convex function class satisfying the Polyak-Lojasiewicz (PL) condition. A number of important non-convex problems in machine learning, including some classes of neural networks, have been recently shown to satisfy the PL condition. We argue that the PL condition provides a relevant and attractive setting for many machine learning problems, particularly in the over-parametrized regime.