 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing an Image Caption Generator Using Off-Line Human Feedback
Nov 21, 2019

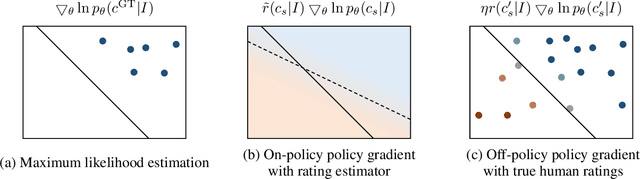
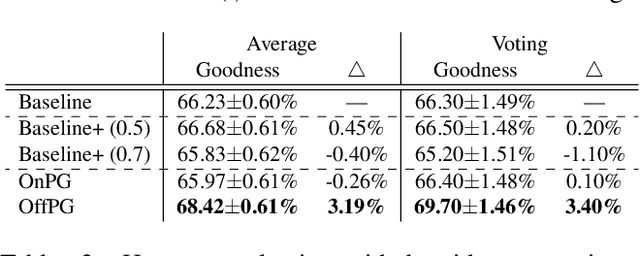
Human ratings are currently the most accurate way to assess the quality of an image captioning model, yet most often the only used outcome of an expensive human rating evaluation is a few overall statistics over the evaluation dataset. In this paper, we show that the signal from instance-level human caption ratings can be leveraged to improve captioning models, even when the amount of caption ratings is several orders of magnitude less than the caption training data. We employ a policy gradient method to maximize the human ratings as rewards in an off-policy reinforcement learning setting, where policy gradients are estimated by samples from a distribution that focuses on the captions in a caption ratings dataset. Our empirical evidence indicates that the proposed method learns to generalize the human raters' judgments to a previously unseen set of images, as judged by a different set of human judges, and additionally on a different, multi-dimensional side-by-side human evaluation procedure.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Oct 30, 2019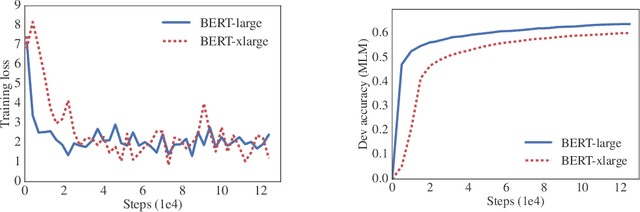

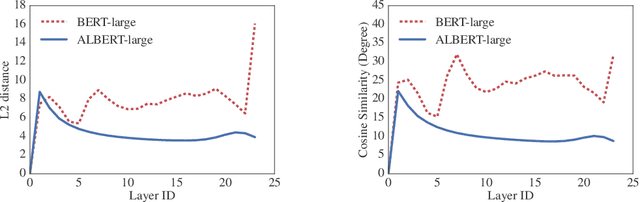

Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations, longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows that our proposed methods lead to models that scale much better compared to the original BERT. We also use a self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and SQuAD benchmarks while having fewer parameters compared to BERT-large.The code and the pretrained models are available at https://github.com/google-research/google-research/tree/master/albert.
A Case Study on Combining ASR and Visual Features for Generating Instructional Video Captions
Oct 07, 2019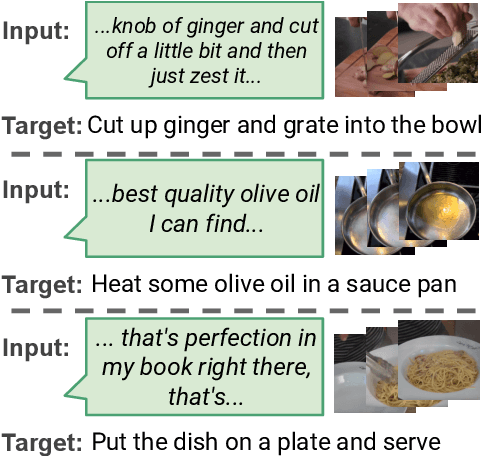
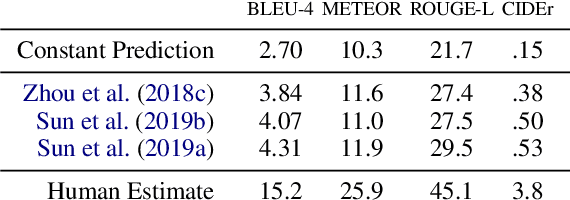
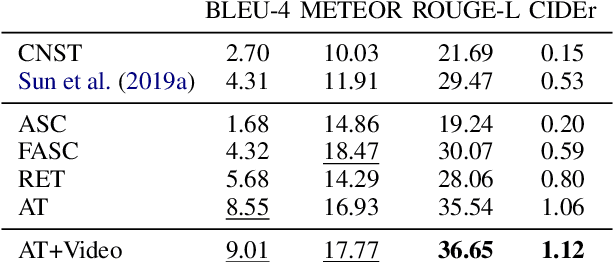
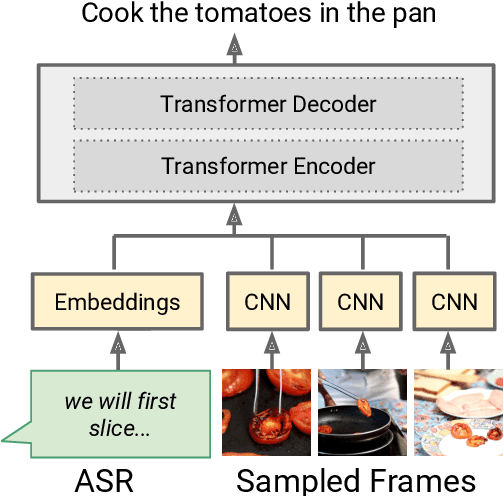
Instructional videos get high-traffic on video sharing platforms, and prior work suggests that providing time-stamped, subtask annotations (e.g., "heat the oil in the pan") improves user experiences. However, current automatic annotation methods based on visual features alone perform only slightly better than constant prediction. Taking cues from prior work, we show that we can improve performance significantly by considering automatic speech recognition (ASR) tokens as input. Furthermore, jointly modeling ASR tokens and visual features results in higher performance compared to training individually on either modality. We find that unstated background information is better explained by visual features, whereas fine-grained distinctions (e.g., "add oil" vs. "add olive oil") are disambiguated more easily via ASR tokens.
Multi-stage Pretraining for Abstractive Summarization
Sep 23, 2019
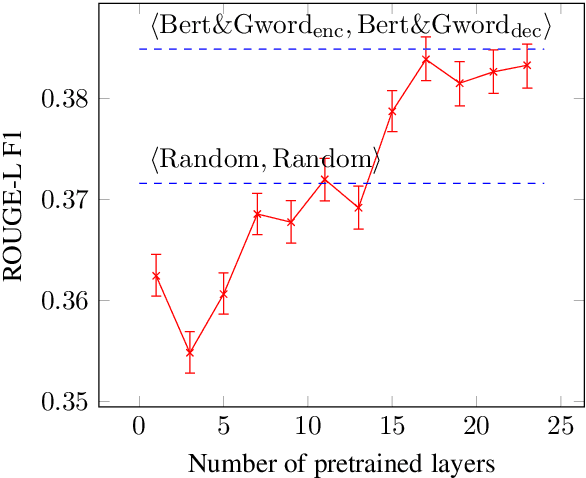


Neural models for abstractive summarization tend to achieve the best performance in the presence of highly specialized, summarization specific modeling add-ons such as pointer-generator, coverage-modeling, and inferencetime heuristics. We show here that pretraining can complement such modeling advancements to yield improved results in both short-form and long-form abstractive summarization using two key concepts: full-network initialization and multi-stage pretraining. Our method allows the model to transitively benefit from multiple pretraining tasks, from generic language tasks to a specialized summarization task to an even more specialized one such as bullet-based summarization. Using this approach, we demonstrate improvements of 1.05 ROUGE-L points on the Gigaword benchmark and 1.78 ROUGE-L points on the CNN/DailyMail benchmark, compared to a randomly-initialized baseline.
Quality Estimation for Image Captions Based on Large-scale Human Evaluations
Sep 08, 2019
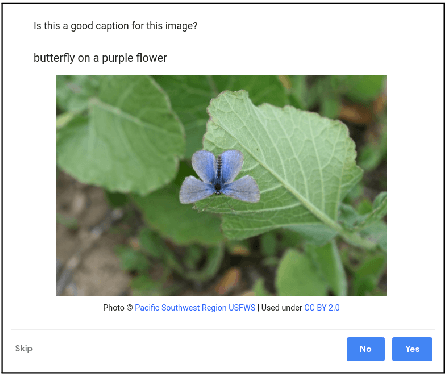
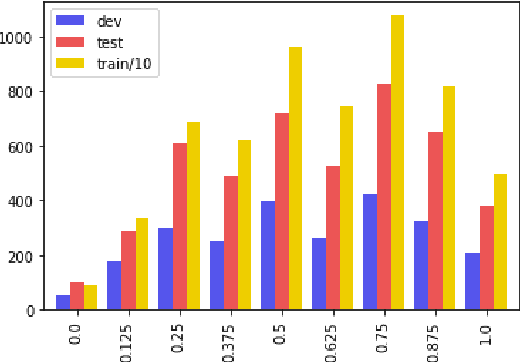

Automatic image captioning has improved significantly in the last few years, but the problem is far from being solved. Furthermore, while the standard automatic metrics, such as CIDEr and SPICE~\cite{cider,spice}, can be used for model selection, they cannot be used at inference-time given a previously unseen image since they require ground-truth references. In this paper, we focus on the related problem called Quality Estimation (QE) of image-captions. In contrast to automatic metrics, QE attempts to model caption quality without relying on ground-truth references. It can thus be applied as a second-pass model (after caption generation) to estimate the quality of captions even for previously unseen images. We conduct a large-scale human evaluation experiment, in which we collect a new dataset of more than 600k ratings of image-caption pairs. Using this dataset, we design and experiment with several QE modeling approaches and provide an analysis of their performance. Our results show that QE is feasible for image captioning.
Decoupled Box Proposal and Featurization with Ultrafine-Grained Semantic Labels Improve Image Captioning and Visual Question Answering
Sep 04, 2019
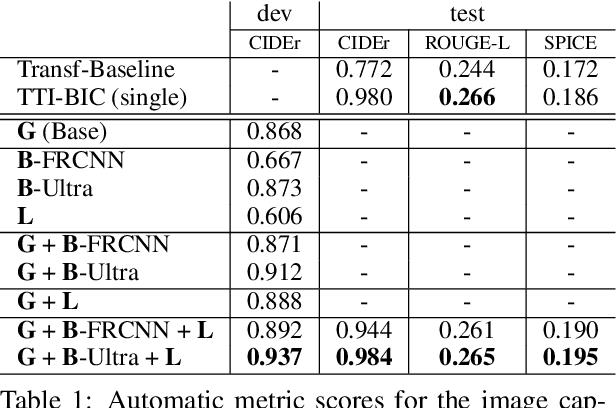

Object detection plays an important role in current solutions to vision and language tasks like image captioning and visual question answering. However, popular models like Faster R-CNN rely on a costly process of annotating ground-truths for both the bounding boxes and their corresponding semantic labels, making it less amenable as a primitive task for transfer learning. In this paper, we examine the effect of decoupling box proposal and featurization for down-stream tasks. The key insight is that this allows us to leverage a large amount of labeled annotations that were previously unavailable for standard object detection benchmarks. Empirically, we demonstrate that this leads to effective transfer learning and improved image captioning and visual question answering models, as measured on publicly available benchmarks.
Informative Image Captioning with External Sources of Information
Jun 20, 2019
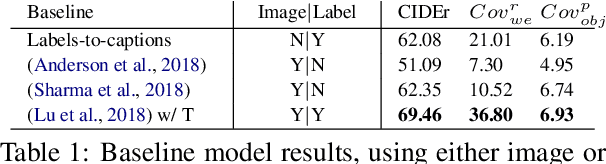
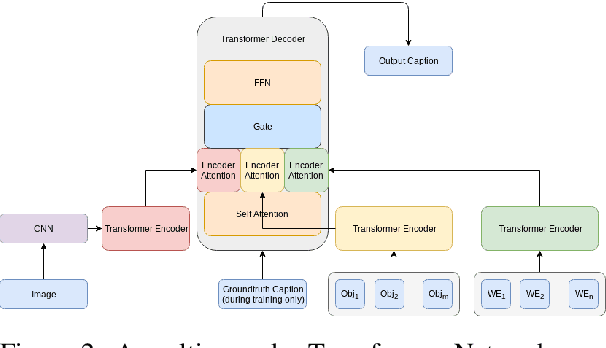
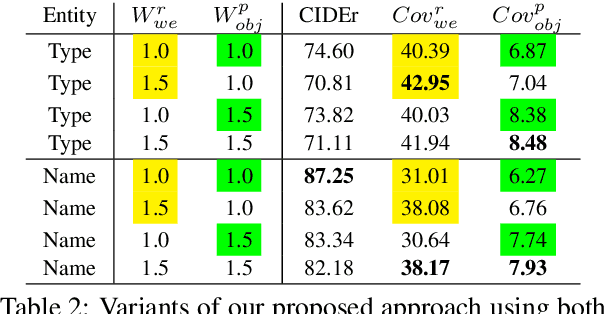
An image caption should fluently present the essential information in a given image, including informative, fine-grained entity mentions and the manner in which these entities interact. However, current captioning models are usually trained to generate captions that only contain common object names, thus falling short on an important "informativeness" dimension. We present a mechanism for integrating image information together with fine-grained labels (assumed to be generated by some upstream models) into a caption that describes the image in a fluent and informative manner. We introduce a multimodal, multi-encoder model based on Transformer that ingests both image features and multiple sources of entity labels. We demonstrate that we can learn to control the appearance of these entity labels in the output, resulting in captions that are both fluent and informative.
SHAPED: Shared-Private Encoder-Decoder for Text Style Adaptation
Apr 11, 2018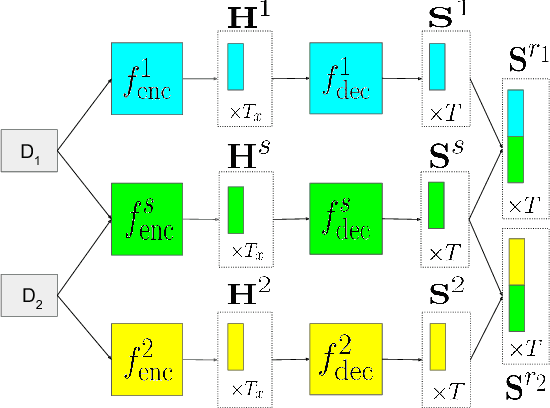
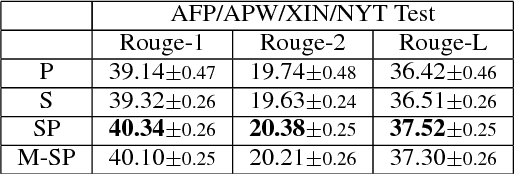
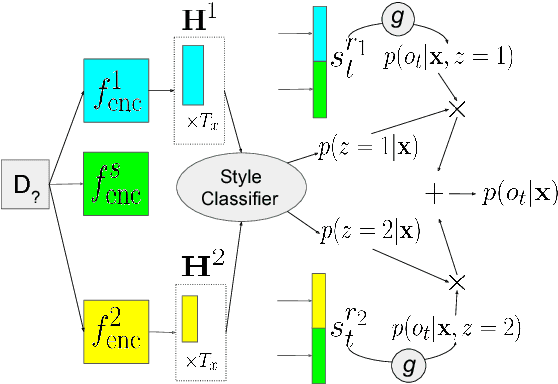

Supervised training of abstractive language generation models results in learning conditional probabilities over language sequences based on the supervised training signal. When the training signal contains a variety of writing styles, such models may end up learning an 'average' style that is directly influenced by the training data make-up and cannot be controlled by the needs of an application. We describe a family of model architectures capable of capturing both generic language characteristics via shared model parameters, as well as particular style characteristics via private model parameters. Such models are able to generate language according to a specific learned style, while still taking advantage of their power to model generic language phenomena. Furthermore, we describe an extension that uses a mixture of output distributions from all learned styles to perform on-the fly style adaptation based on the textual input alone. Experimentally, we find that the proposed models consistently outperform models that encapsulate single-style or average-style language generation capabilities.
Cold-Start Reinforcement Learning with Softmax Policy Gradient
Oct 13, 2017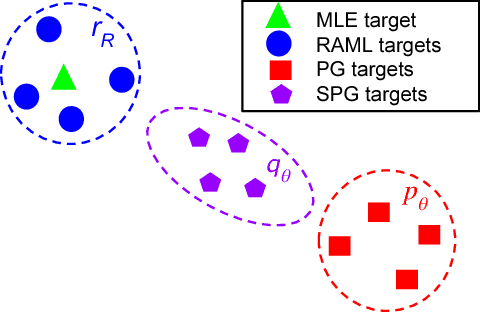

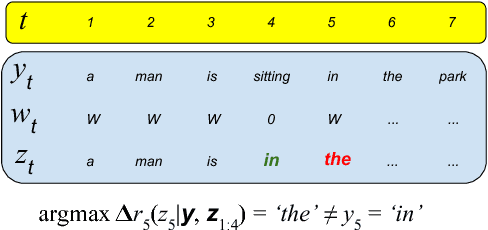

Policy-gradient approaches to reinforcement learning have two common and undesirable overhead procedures, namely warm-start training and sample variance reduction. In this paper, we describe a reinforcement learning method based on a softmax value function that requires neither of these procedures. Our method combines the advantages of policy-gradient methods with the efficiency and simplicity of maximum-likelihood approaches. We apply this new cold-start reinforcement learning method in training sequence generation models for structured output prediction problems. Empirical evidence validates this method on automatic summarization and image captioning tasks.
Understanding Image and Text Simultaneously: a Dual Vision-Language Machine Comprehension Task
Dec 22, 2016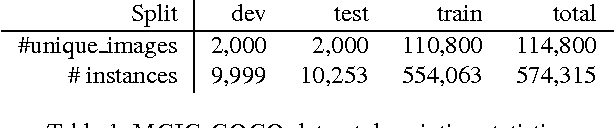

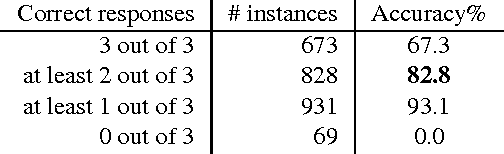

We introduce a new multi-modal task for computer systems, posed as a combined vision-language comprehension challenge: identifying the most suitable text describing a scene, given several similar options. Accomplishing the task entails demonstrating comprehension beyond just recognizing "keywords" (or key-phrases) and their corresponding visual concepts. Instead, it requires an alignment between the representations of the two modalities that achieves a visually-grounded "understanding" of various linguistic elements and their dependencies. This new task also admits an easy-to-compute and well-studied metric: the accuracy in detecting the true target among the decoys. The paper makes several contributions: an effective and extensible mechanism for generating decoys from (human-created) image captions; an instance of applying this mechanism, yielding a large-scale machine comprehension dataset (based on the COCO images and captions) that we make publicly available; human evaluation results on this dataset, informing a performance upper-bound; and several baseline and competitive learning approaches that illustrate the utility of the proposed task and dataset in advancing both image and language comprehension. We also show that, in a multi-task learning setting, the performance on the proposed task is positively correlated with the end-to-end task of image captioning.