 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Head-Pose Estimation Based on Partially-Latent Mixture of Linear Regressions
Mar 06, 2017



Head-pose estimation has many applications, such as social event analysis, human-robot and human-computer interaction, driving assistance, and so forth. Head-pose estimation is challenging because it must cope with changing illumination conditions, variabilities in face orientation and in appearance, partial occlusions of facial landmarks, as well as bounding-box-to-face alignment errors. We propose tu use a mixture of linear regressions with partially-latent output. This regression method learns to map high-dimensional feature vectors (extracted from bounding boxes of faces) onto the joint space of head-pose angles and bounding-box shifts, such that they are robustly predicted in the presence of unobservable phenomena. We describe in detail the mapping method that combines the merits of unsupervised manifold learning techniques and of mixtures of regressions. We validate our method with three publicly available datasets and we thoroughly benchmark four variants of the proposed algorithm with several state-of-the-art head-pose estimation methods.
* 12 pages, 5 figures, 3 tables
Joint Alignment of Multiple Point Sets with Batch and Incremental Expectation-Maximization
Mar 06, 2017



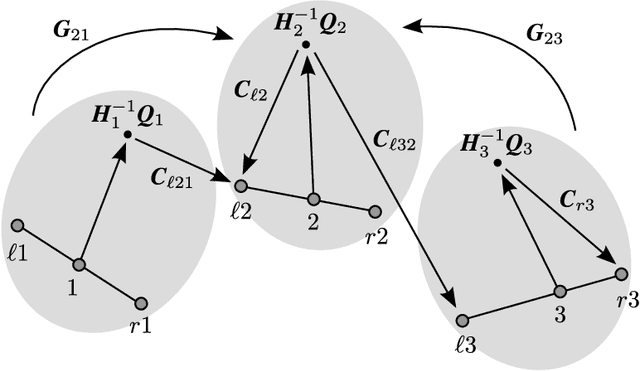
This paper addresses the problem of registering multiple point sets. Solutions to this problem are often approximated by repeatedly solving for pairwise registration, which results in an uneven treatment of the sets forming a pair: a model set and a data set. The main drawback of this strategy is that the model set may contain noise and outliers, which negatively affects the estimation of the registration parameters. In contrast, the proposed formulation treats all the point sets on an equal footing. Indeed, all the points are drawn from a central Gaussian mixture, hence the registration is cast into a clustering problem. We formally derive batch and incremental EM algorithms that robustly estimate both the GMM parameters and the rotations and translations that optimally align the sets. Moreover, the mixture's means play the role of the registered set of points while the variances provide rich information about the contribution of each component to the alignment. We thoroughly test the proposed algorithms on simulated data and on challenging real data collected with range sensors. We compare them with several state-of-the-art algorithms, and we show their potential for surface reconstruction from depth data.
* 14 pages, 12 figures, 5 tables
Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion
Nov 03, 2016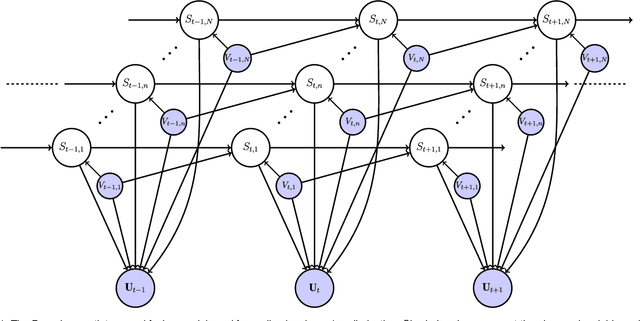
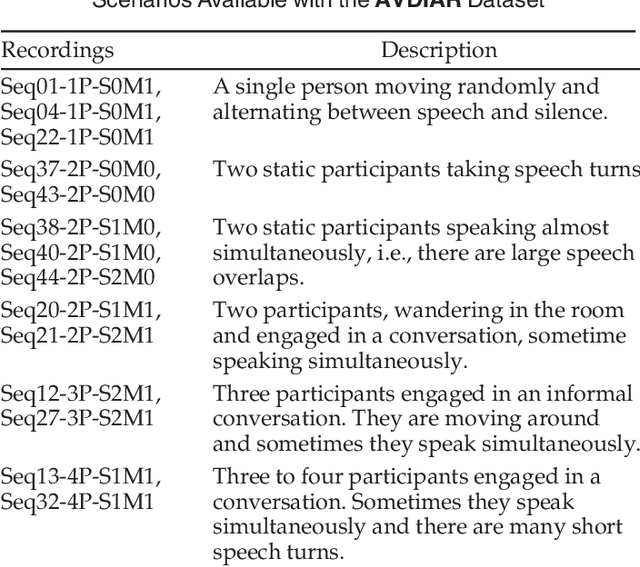
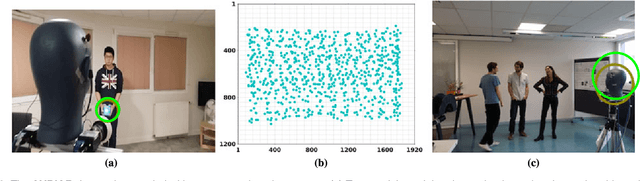
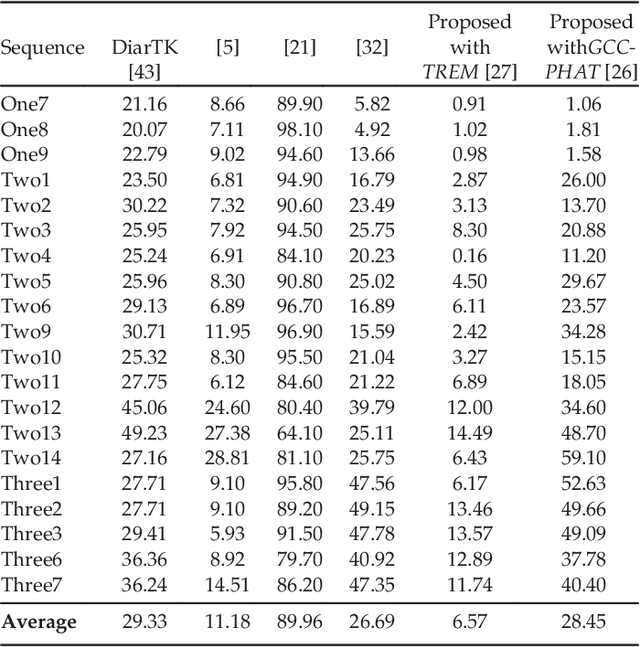
Speaker diarization consists of assigning speech signals to people engaged in a dialogue. An audio-visual spatiotemporal diarization model is proposed. The model is well suited for challenging scenarios that consist of several participants engaged in multi-party interaction while they move around and turn their heads towards the other participants rather than facing the cameras and the microphones. Multiple-person visual tracking is combined with multiple speech-source localization in order to tackle the speech-to-person association problem. The latter is solved within a novel audio-visual fusion method on the following grounds: binaural spectral features are first extracted from a microphone pair, then a supervised audio-visual alignment technique maps these features onto an image, and finally a semi-supervised clustering method assigns binaural spectral features to visible persons. The main advantage of this method over previous work is that it processes in a principled way speech signals uttered simultaneously by multiple persons. The diarization itself is cast into a latent-variable temporal graphical model that infers speaker identities and speech turns, based on the output of an audio-visual association process, executed at each time slice, and on the dynamics of the diarization variable itself. The proposed formulation yields an efficient exact inference procedure. A novel dataset, that contains audio-visual training data as well as a number of scenarios involving several participants engaged in formal and informal dialogue, is introduced. The proposed method is thoroughly tested and benchmarked with respect to several state-of-the art diarization algorithms.
* 14 pages, 6 figures, 5 tables
An On-line Variational Bayesian Model for Multi-Person Tracking from Cluttered Scenes
Jun 30, 2016
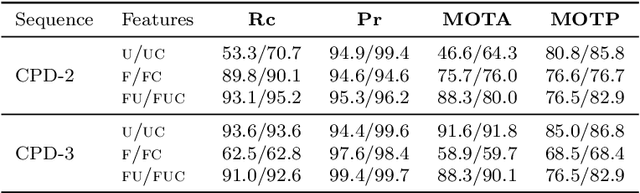
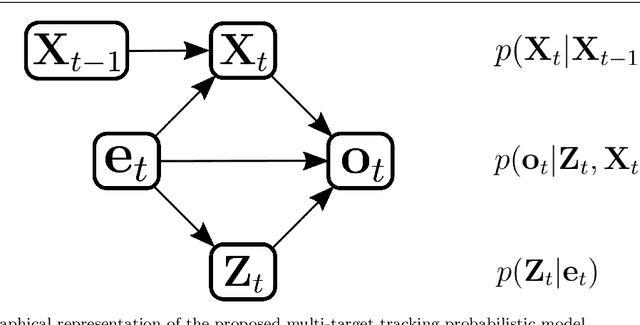
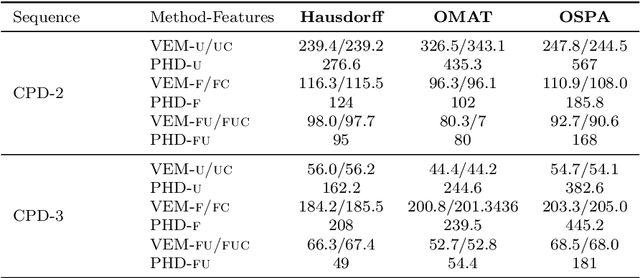
Object tracking is an ubiquitous problem that appears in many applications such as remote sensing, audio processing, computer vision, human-machine interfaces, human-robot interaction, etc. Although thoroughly investigated in computer vision, tracking a time-varying number of persons remains a challenging open problem. In this paper, we propose an on-line variational Bayesian model for multi-person tracking from cluttered visual observations provided by person detectors. The contributions of this paper are the followings. First, we propose a variational Bayesian framework for tracking an unknown and varying number of persons. Second, our model results in a variational expectation-maximization (VEM) algorithm with closed-form expressions for the posterior distributions of the latent variables and for the estimation of the model parameters. Third, the proposed model exploits observations from multiple detectors, and it is therefore multimodal by nature. Finally, we propose to embed both object-birth and object-visibility processes in an effort to robustly handle person appearances and disappearances over time. Evaluated on classical multiple person tracking datasets, our method shows competitive results with respect to state-of-the-art multiple-object tracking models, such as the probability hypothesis density (PHD) filter among others.
* 21 pages, 9 figures, 4 tables
Co-Localization of Audio Sources in Images Using Binaural Features and Locally-Linear Regression
Apr 15, 2016

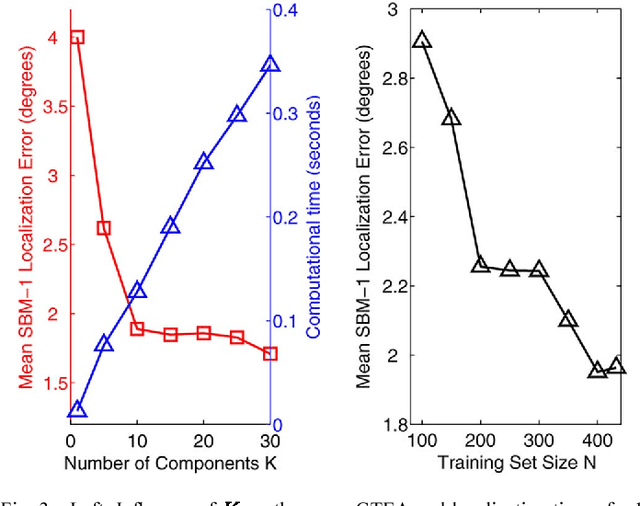

This paper addresses the problem of localizing audio sources using binaural measurements. We propose a supervised formulation that simultaneously localizes multiple sources at different locations. The approach is intrinsically efficient because, contrary to prior work, it relies neither on source separation, nor on monaural segregation. The method starts with a training stage that establishes a locally-linear Gaussian regression model between the directional coordinates of all the sources and the auditory features extracted from binaural measurements. While fixed-length wide-spectrum sounds (white noise) are used for training to reliably estimate the model parameters, we show that the testing (localization) can be extended to variable-length sparse-spectrum sounds (such as speech), thus enabling a wide range of realistic applications. Indeed, we demonstrate that the method can be used for audio-visual fusion, namely to map speech signals onto images and hence to spatially align the audio and visual modalities, thus enabling to discriminate between speaking and non-speaking faces. We release a novel corpus of real-room recordings that allow quantitative evaluation of the co-localization method in the presence of one or two sound sources. Experiments demonstrate increased accuracy and speed relative to several state-of-the-art methods.
* 15 pages, 8 figures
EM Algorithms for Weighted-Data Clustering with Application to Audio-Visual Scene Analysis
Jan 25, 2016
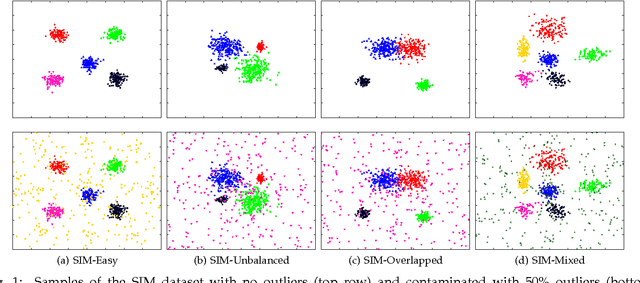

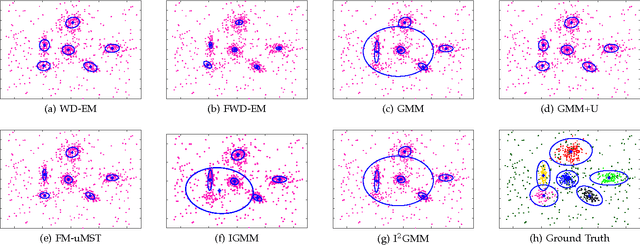
Data clustering has received a lot of attention and numerous methods, algorithms and software packages are available. Among these techniques, parametric finite-mixture models play a central role due to their interesting mathematical properties and to the existence of maximum-likelihood estimators based on expectation-maximization (EM). In this paper we propose a new mixture model that associates a weight with each observed point. We introduce the weighted-data Gaussian mixture and we derive two EM algorithms. The first one considers a fixed weight for each observation. The second one treats each weight as a random variable following a gamma distribution. We propose a model selection method based on a minimum message length criterion, provide a weight initialization strategy, and validate the proposed algorithms by comparing them with several state of the art parametric and non-parametric clustering techniques. We also demonstrate the effectiveness and robustness of the proposed clustering technique in the presence of heterogeneous data, namely audio-visual scene analysis.
* 14 pages, 4 figures, 4 tables
Hyper-Spectral Image Analysis with Partially-Latent Regression and Spatial Markov Dependencies
Mar 27, 2015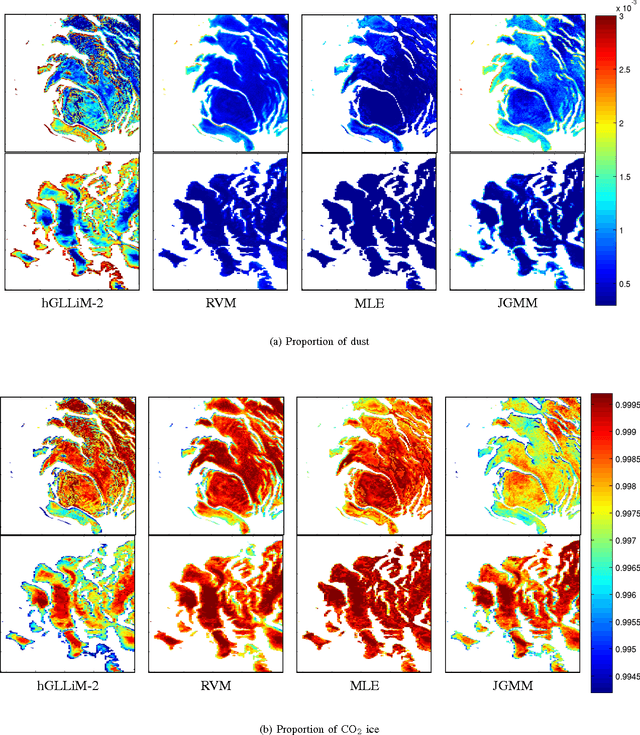
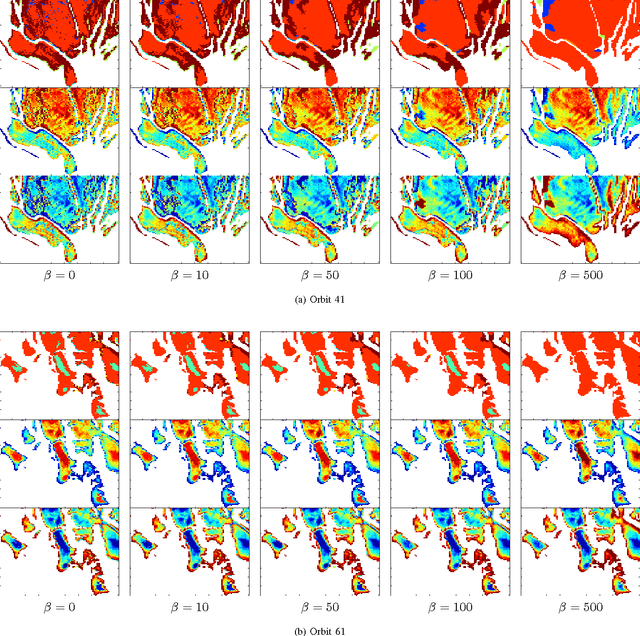
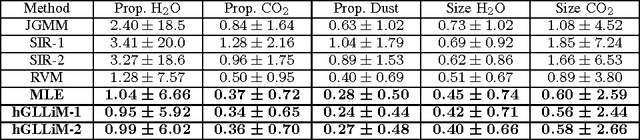
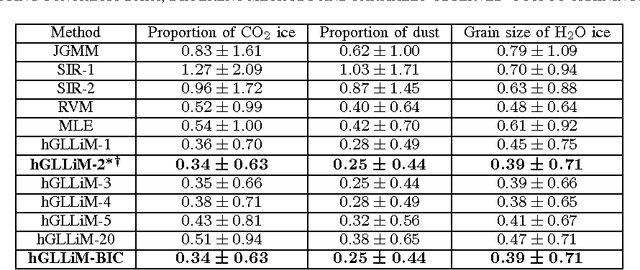
Hyper-spectral data can be analyzed to recover physical properties at large planetary scales. This involves resolving inverse problems which can be addressed within machine learning, with the advantage that, once a relationship between physical parameters and spectra has been established in a data-driven fashion, the learned relationship can be used to estimate physical parameters for new hyper-spectral observations. Within this framework, we propose a spatially-constrained and partially-latent regression method which maps high-dimensional inputs (hyper-spectral images) onto low-dimensional responses (physical parameters such as the local chemical composition of the soil). The proposed regression model comprises two key features. Firstly, it combines a Gaussian mixture of locally-linear mappings (GLLiM) with a partially-latent response model. While the former makes high-dimensional regression tractable, the latter enables to deal with physical parameters that cannot be observed or, more generally, with data contaminated by experimental artifacts that cannot be explained with noise models. Secondly, spatial constraints are introduced in the model through a Markov random field (MRF) prior which provides a spatial structure to the Gaussian-mixture hidden variables. Experiments conducted on a database composed of remotely sensed observations collected from the Mars planet by the Mars Express orbiter demonstrate the effectiveness of the proposed model.
* 12 pages, 4 figures, 3 tables
Cross-calibration of Time-of-flight and Colour Cameras
Jun 30, 2014
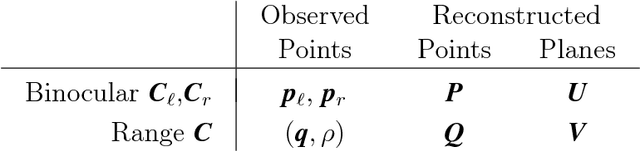
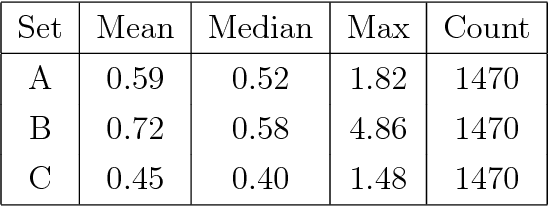
Time-of-flight cameras provide depth information, which is complementary to the photometric appearance of the scene in ordinary images. It is desirable to merge the depth and colour information, in order to obtain a coherent scene representation. However, the individual cameras will have different viewpoints, resolutions and fields of view, which means that they must be mutually calibrated. This paper presents a geometric framework for this multi-view and multi-modal calibration problem. It is shown that three-dimensional projective transformations can be used to align depth and parallax-based representations of the scene, with or without Euclidean reconstruction. A new evaluation procedure is also developed; this allows the reprojection error to be decomposed into calibration and sensor-dependent components. The complete approach is demonstrated on a network of three time-of-flight and six colour cameras. The applications of such a system, to a range of automatic scene-interpretation problems, are discussed.
Continuous Action Recognition Based on Sequence Alignment
Jun 02, 2014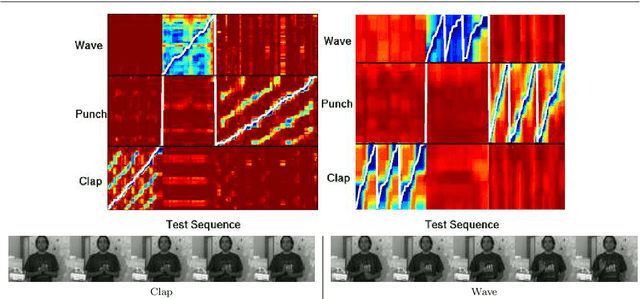
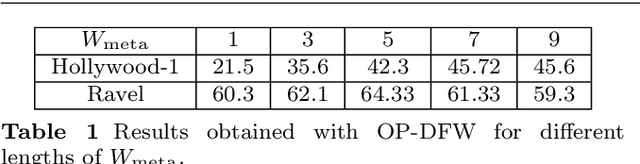

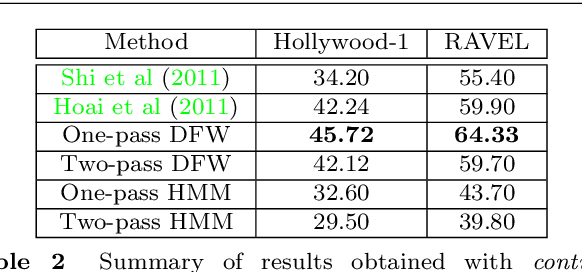
Continuous action recognition is more challenging than isolated recognition because classification and segmentation must be simultaneously carried out. We build on the well known dynamic time warping (DTW) framework and devise a novel visual alignment technique, namely dynamic frame warping (DFW), which performs isolated recognition based on per-frame representation of videos, and on aligning a test sequence with a model sequence. Moreover, we propose two extensions which enable to perform recognition concomitant with segmentation, namely one-pass DFW and two-pass DFW. These two methods have their roots in the domain of continuous recognition of speech and, to the best of our knowledge, their extension to continuous visual action recognition has been overlooked. We test and illustrate the proposed techniques with a recently released dataset (RAVEL) and with two public-domain datasets widely used in action recognition (Hollywood-1 and Hollywood-2). We also compare the performances of the proposed isolated and continuous recognition algorithms with several recently published methods.
Robust Temporally Coherent Laplacian Protrusion Segmentation of 3D Articulated Bodies
May 26, 2014
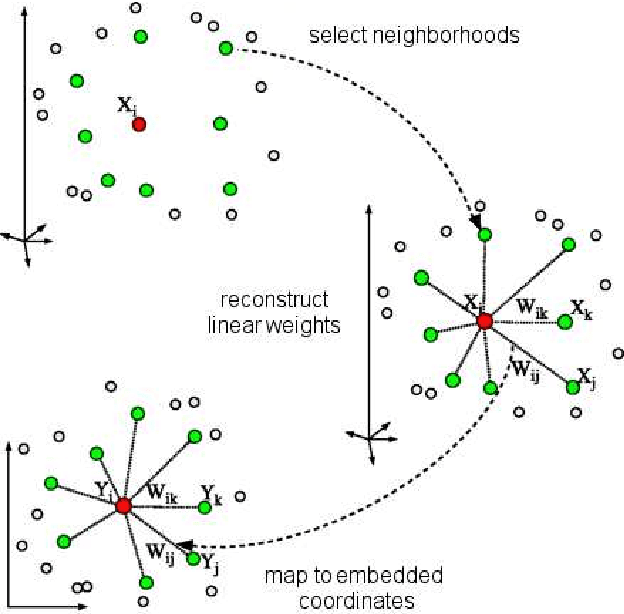
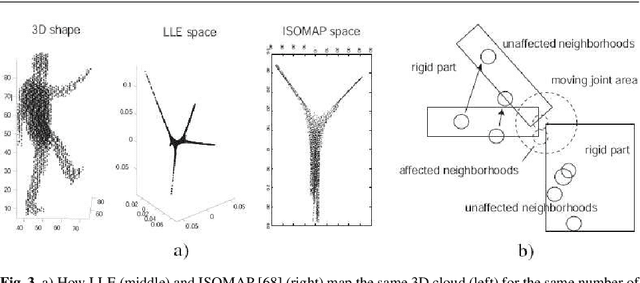

In motion analysis and understanding it is important to be able to fit a suitable model or structure to the temporal series of observed data, in order to describe motion patterns in a compact way, and to discriminate between them. In an unsupervised context, i.e., no prior model of the moving object(s) is available, such a structure has to be learned from the data in a bottom-up fashion. In recent times, volumetric approaches in which the motion is captured from a number of cameras and a voxel-set representation of the body is built from the camera views, have gained ground due to attractive features such as inherent view-invariance and robustness to occlusions. Automatic, unsupervised segmentation of moving bodies along entire sequences, in a temporally-coherent and robust way, has the potential to provide a means of constructing a bottom-up model of the moving body, and track motion cues that may be later exploited for motion classification. Spectral methods such as locally linear embedding (LLE) can be useful in this context, as they preserve "protrusions", i.e., high-curvature regions of the 3D volume, of articulated shapes, while improving their separation in a lower dimensional space, making them in this way easier to cluster. In this paper we therefore propose a spectral approach to unsupervised and temporally-coherent body-protrusion segmentation along time sequences. Volumetric shapes are clustered in an embedding space, clusters are propagated in time to ensure coherence, and merged or split to accommodate changes in the body's topology. Experiments on both synthetic and real sequences of dense voxel-set data are shown. This supports the ability of the proposed method to cluster body-parts consistently over time in a totally unsupervised fashion, its robustness to sampling density and shape quality, and its potential for bottom-up model construction
* 31 pages, 26 figures