 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Factorization Methods Using a Gaussian/Uniform Mixture Model
Dec 15, 2020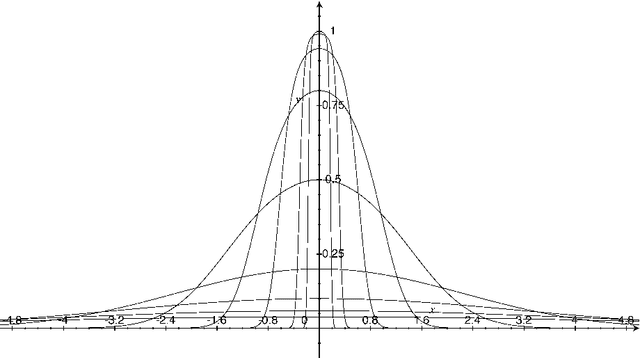
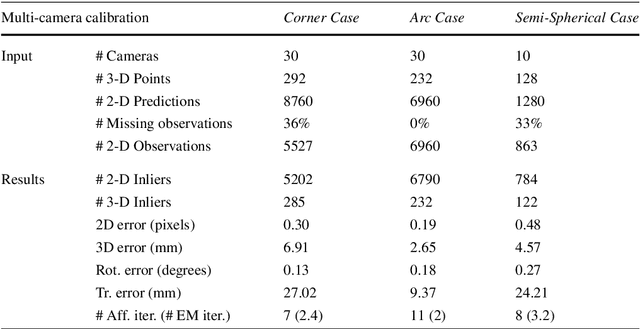


In this paper we address the problem of building a class of robust factorization algorithms that solve for the shape and motion parameters with both affine (weak perspective) and perspective camera models. We introduce a Gaussian/uniform mixture model and its associated EM algorithm. This allows us to address robust parameter estimation within a data clustering approach. We propose a robust technique that works with any affine factorization method and makes it robust to outliers. In addition, we show how such a framework can be further embedded into an iterative perspective factorization scheme. We carry out a large number of experiments to validate our algorithms and to compare them with existing ones. We also compare our approach with factorization methods that use M-estimators.
Articulated Shape Matching Using Laplacian Eigenfunctions and Unsupervised Point Registration
Dec 14, 2020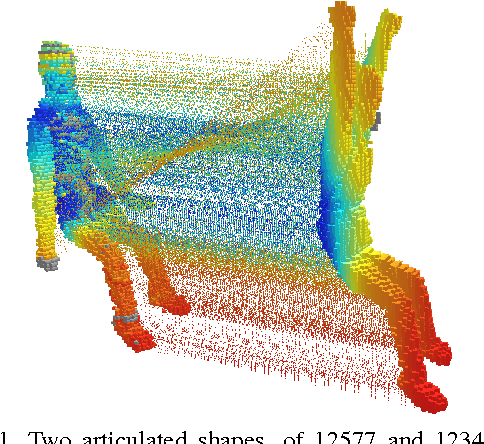
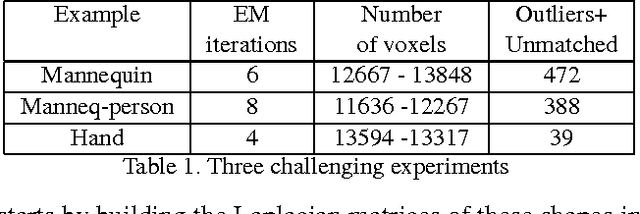
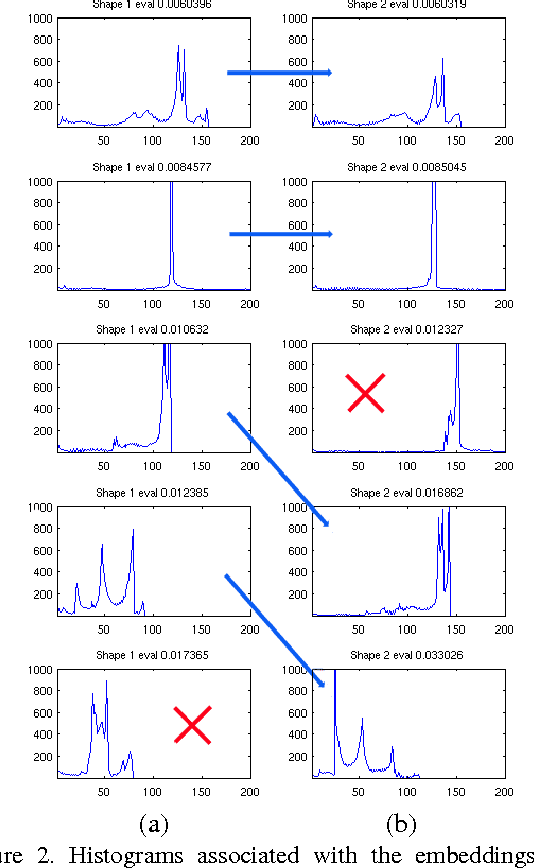
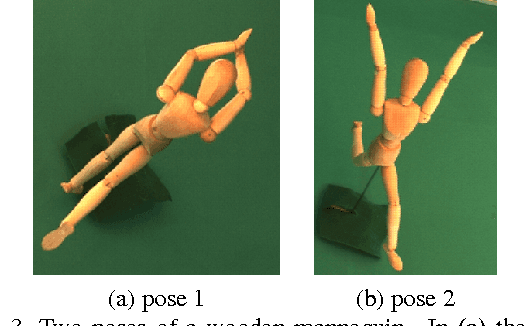
Matching articulated shapes represented by voxel-sets reduces to maximal sub-graph isomorphism when each set is described by a weighted graph. Spectral graph theory can be used to map these graphs onto lower dimensional spaces and match shapes by aligning their embeddings in virtue of their invariance to change of pose. Classical graph isomorphism schemes relying on the ordering of the eigenvalues to align the eigenspaces fail when handling large data-sets or noisy data. We derive a new formulation that finds the best alignment between two congruent $K$-dimensional sets of points by selecting the best subset of eigenfunctions of the Laplacian matrix. The selection is done by matching eigenfunction signatures built with histograms, and the retained set provides a smart initialization for the alignment problem with a considerable impact on the overall performance. Dense shape matching casted into graph matching reduces then, to point registration of embeddings under orthogonal transformations; the registration is solved using the framework of unsupervised clustering and the EM algorithm. Maximal subset matching of non identical shapes is handled by defining an appropriate outlier class. Experimental results on challenging examples show how the algorithm naturally treats changes of topology, shape variations and different sampling densities.
An Overview of Depth Cameras and Range Scanners Based on Time-of-Flight Technologies
Dec 12, 2020



Time-of-flight (TOF) cameras are sensors that can measure the depths of scene-points, by illuminating the scene with a controlled laser or LED source, and then analyzing the reflected light. In this paper, we will first describe the underlying measurement principles of time-of-flight cameras, including: (i) pulsed-light cameras, which measure directly the time taken for a light pulse to travel from the device to the object and back again, and (ii) continuous-wave modulated-light cameras, which measure the phase difference between the emitted and received signals, and hence obtain the travel time indirectly. We review the main existing designs, including prototypes as well as commercially available devices. We also review the relevant camera calibration principles, and how they are applied to TOF devices. Finally, we discuss the benefits and challenges of combined TOF and color camera systems.
Fusion of Range and Stereo Data for High-Resolution Scene-Modeling
Dec 12, 2020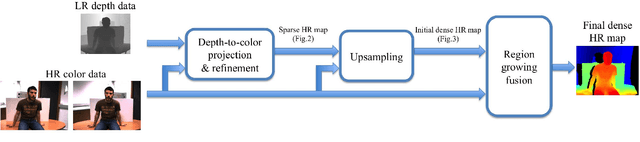
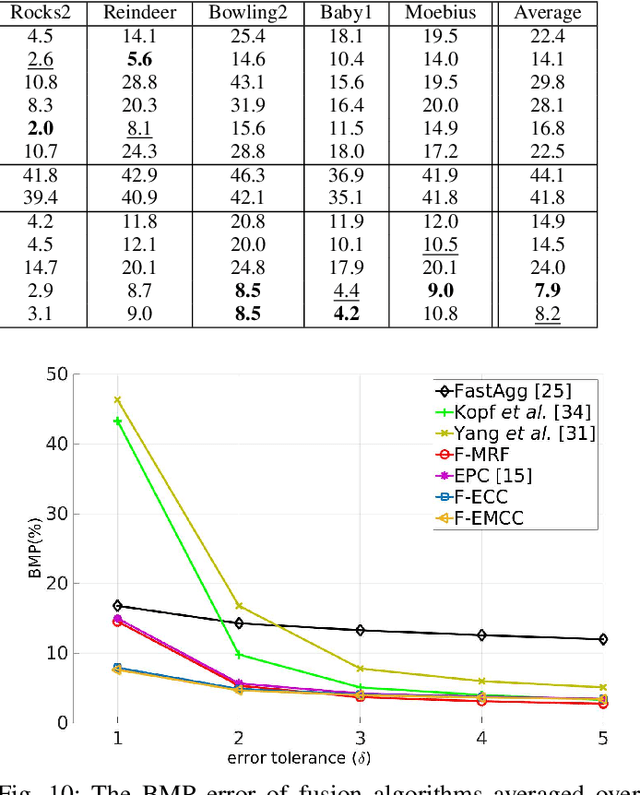


This paper addresses the problem of range-stereo fusion, for the construction of high-resolution depth maps. In particular, we combine low-resolution depth data with high-resolution stereo data, in a maximum a posteriori (MAP) formulation. Unlike existing schemes that build on MRF optimizers, we infer the disparity map from a series of local energy minimization problems that are solved hierarchically, by growing sparse initial disparities obtained from the depth data. The accuracy of the method is not compromised, owing to three properties of the data-term in the energy function. Firstly, it incorporates a new correlation function that is capable of providing refined correlations and disparities, via subpixel correction. Secondly, the correlation scores rely on an adaptive cost aggregation step, based on the depth data. Thirdly, the stereo and depth likelihoods are adaptively fused, based on the scene texture and camera geometry. These properties lead to a more selective growing process which, unlike previous seed-growing methods, avoids the tendency to propagate incorrect disparities. The proposed method gives rise to an intrinsically efficient algorithm, which runs at 3FPS on 2.0MP images on a standard desktop computer. The strong performance of the new method is established both by quantitative comparisons with state-of-the-art methods, and by qualitative comparisons using real depth-stereo data-sets.
Cyclopean Geometry of Binocular Vision
Dec 11, 2020
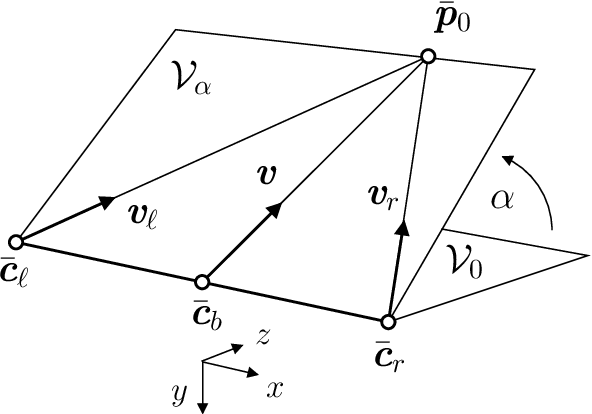
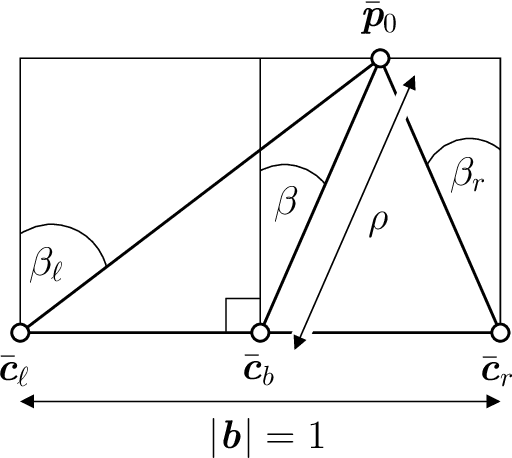

The geometry of binocular projection is analyzed, with reference to the primate visual system. In particular, the effects of coordinated eye movements on the retinal images are investigated. An appropriate oculomotor parameterization is defined, and is shown to complement the classical version and vergence angles. The midline horopter is identified, and subsequently used to construct the epipolar geometry of the system. It is shown that the Essential matrix can be obtained by combining the epipoles with the projection of the midline horopter. A local model of the scene is adopted, in which depth is measured relative to a plane containing the fixation point. The binocular disparity field is given a symmetric parameterization, in which the unknown scene-depths determine the location of corresponding image-features. The resulting Cyclopean depth-map can be combined with the estimated oculomotor parameters, to produce a local representation of the scene. The recovery of visual direction and depth from retinal images is discussed, with reference to the relevant psychophysical and neurophysiological literature.
Image Matching with Scale Adjustment
Dec 10, 2020
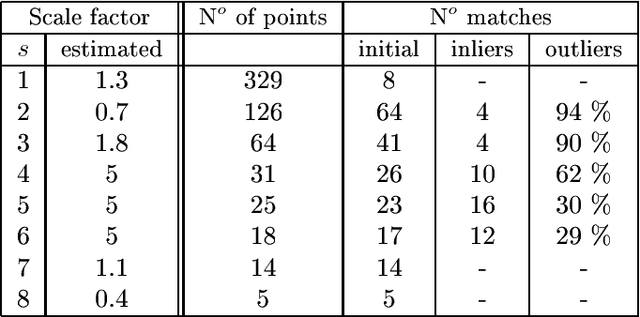

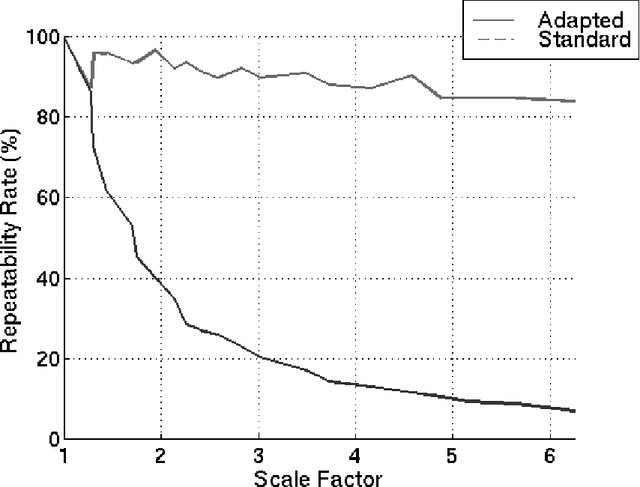
In this paper we address the problem of matching two images with two different resolutions: a high-resolution image and a low-resolution one. The difference in resolution between the two images is not known and without loss of generality one of the images is assumed to be the high-resolution one. On the premise that changes in resolution act as a smoothing equivalent to changes in scale, a scale-space representation of the high-resolution image is produced. Hence the one-to-one classical image matching paradigm becomes one-to-many because the low-resolution image is compared with all the scale-space representations of the high-resolution one. Key to the success of such a process is the proper representation of the features to be matched in scale-space. We show how to represent and extract interest points at variable scales and we devise a method allowing the comparison of two images at two different resolutions. The method comprises the use of photometric- and rotation-invariant descriptors, a geometric model mapping the high-resolution image onto a low-resolution image region, and an image matching strategy based on local constraints and on the robust estimation of this geometric model. Extensive experiments show that our matching method can be used for scale changes up to a factor of 6.
Topology-Adaptive Mesh Deformation for Surface Evolution, Morphing, and Multi-View Reconstruction
Dec 10, 2020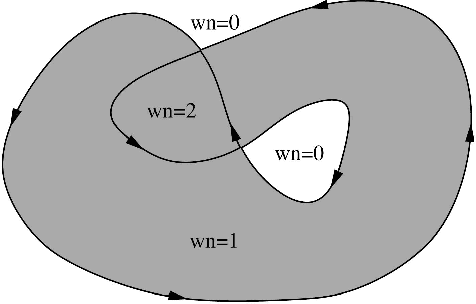
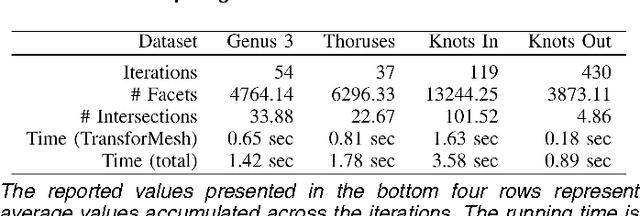
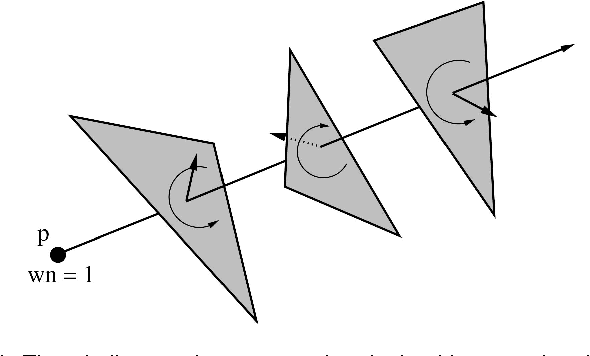
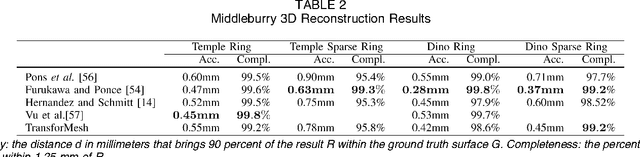
Triangulated meshes have become ubiquitous discrete-surface representations. In this paper we address the problem of how to maintain the manifold properties of a surface while it undergoes strong deformations that may cause topological changes. We introduce a new self-intersection removal algorithm, TransforMesh, and we propose a mesh evolution framework based on this algorithm. Numerous shape modelling applications use surface evolution in order to improve shape properties, such as appearance or accuracy. Both explicit and implicit representations can be considered for that purpose. However, explicit mesh representations, while allowing for accurate surface modelling, suffer from the inherent difficulty of reliably dealing with self-intersections and topological changes such as merges and splits. As a consequence, a majority of methods rely on implicit representations of surfaces, e.g. level-sets, that naturally overcome these issues. Nevertheless, these methods are based on volumetric discretizations, which introduce an unwanted precision-complexity trade-off. The method that we propose handles topological changes in a robust manner and removes self intersections, thus overcoming the traditional limitations of mesh-based approaches. To illustrate the effectiveness of TransforMesh, we describe two challenging applications, namely surface morphing and 3-D reconstruction.
Rigid and Articulated Point Registration with Expectation Conditional Maximization
Dec 09, 2020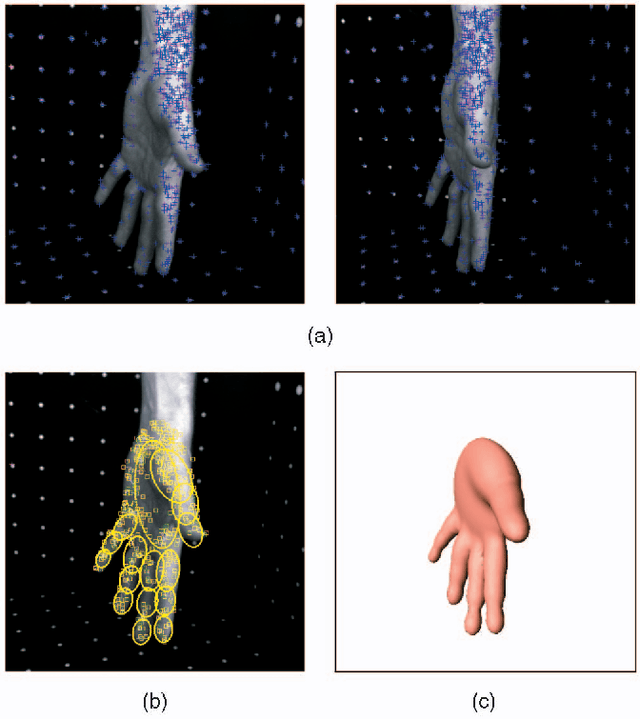
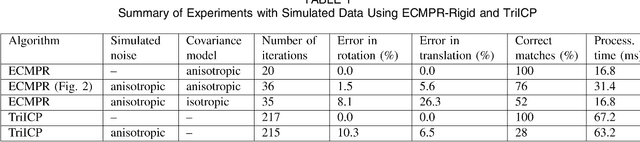
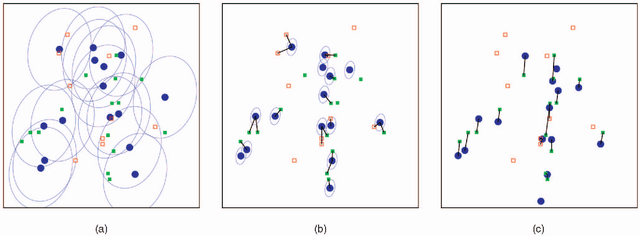
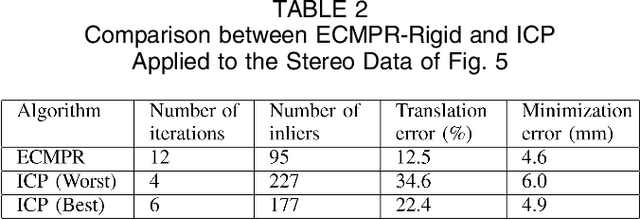
This paper addresses the issue of matching rigid and articulated shapes through probabilistic point registration. The problem is recast into a missing data framework where unknown correspondences are handled via mixture models. Adopting a maximum likelihood principle, we introduce an innovative EM-like algorithm, namely the Expectation Conditional Maximization for Point Registration (ECMPR) algorithm. The algorithm allows the use of general covariance matrices for the mixture model components and improves over the isotropic covariance case. We analyse in detail the associated consequences in terms of estimation of the registration parameters, and we propose an optimal method for estimating the rotational and translational parameters based on semi-definite positive relaxation. We extend rigid registration to articulated registration. Robustness is ensured by detecting and rejecting outliers through the addition of a uniform component to the Gaussian mixture model at hand. We provide an in-depth analysis of our method and we compare it both theoretically and experimentally with other robust methods for point registration.
A Differential Model of the Complex Cell
Dec 09, 2020The receptive fields of simple cells in the visual cortex can be understood as linear filters. These filters can be modelled by Gabor functions, or by Gaussian derivatives. Gabor functions can also be combined in an `energy model' of the complex cell response. This paper proposes an alternative model of the complex cell, based on Gaussian derivatives. It is most important to account for the insensitivity of the complex response to small shifts of the image. The new model uses a linear combination of the first few derivative filters, at a single position, to approximate the first derivative filter, at a series of adjacent positions. The maximum response, over all positions, gives a signal that is insensitive to small shifts of the image. This model, unlike previous approaches, is based on the scale space theory of visual processing. In particular, the complex cell is built from filters that respond to the \twod\ differential structure of the image. The computational aspects of the new model are studied in one and two dimensions, using the steerability of the Gaussian derivatives. The response of the model to basic images, such as edges and gratings, is derived formally. The response to natural images is also evaluated, using statistical measures of shift insensitivity. The relevance of the new model to the cortical image representation is discussed.
Conjugate Mixture Models for Clustering Multimodal Data
Dec 09, 2020The problem of multimodal clustering arises whenever the data are gathered with several physically different sensors. Observations from different modalities are not necessarily aligned in the sense there there is no obvious way to associate or to compare them in some common space. A solution may consist in considering multiple clustering tasks independently for each modality. The main difficulty with such an approach is to guarantee that the unimodal clusterings are mutually consistent. In this paper we show that multimodal clustering can be addressed within a novel framework, namely conjugate mixture models. These models exploit the explicit transformations that are often available between an unobserved parameter space (objects) and each one of the observation spaces (sensors). We formulate the problem as a likelihood maximization task and we derive the associated conjugate expectation-maximization algorithm. The convergence properties of the proposed algorithm are thoroughly investigated. Several local/global optimization techniques are proposed in order to increase its convergence speed. Two initialization strategies are proposed and compared. A consistent model-selection criterion is proposed. The algorithm and its variants are tested and evaluated within the task of 3D localization of several speakers using both auditory and visual data.