 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Stochastic Coordinate Descent
Jul 10, 2020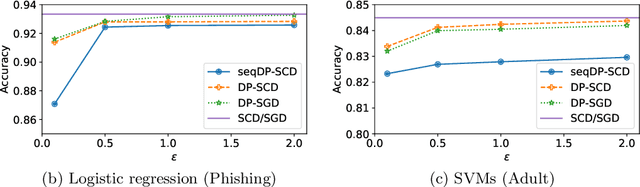

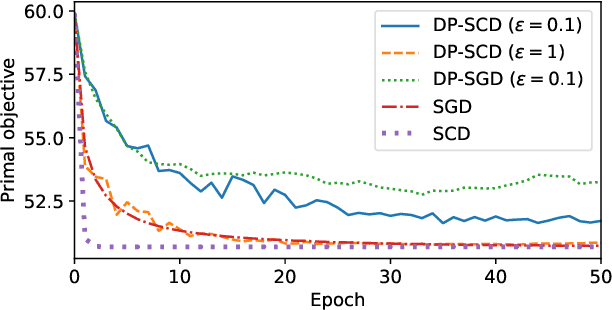
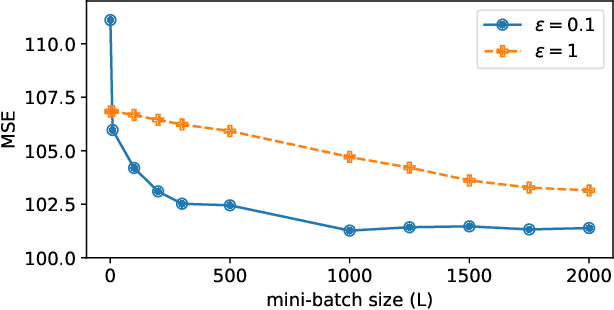
In this paper we tackle the challenge of making the stochastic coordinate descent algorithm differentially private. Compared to the classical gradient descent algorithm where updates operate on a single model vector and controlled noise addition to this vector suffices to hide critical information about individuals, stochastic coordinate descent crucially relies on keeping auxiliary information in memory during training. This auxiliary information provides an additional privacy leak and poses the major challenge addressed in this work. Driven by the insight that under independent noise addition, the consistency of the auxiliary information holds in expectation, we present DP-SCD, the first differentially private stochastic coordinate descent algorithm. We analyze our new method theoretically and argue that decoupling and parallelizing coordinate updates is essential for its utility. On the empirical side we demonstrate competitive performance against the popular stochastic gradient descent alternative (DP-SGD) while requiring significantly less tuning.
FLeet: Online Federated Learning via Staleness Awareness and Performance Prediction
Jun 12, 2020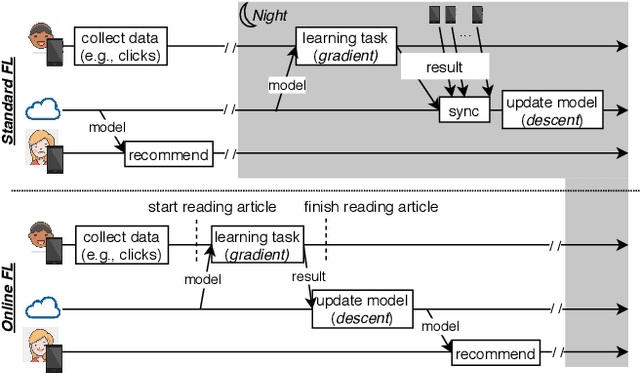
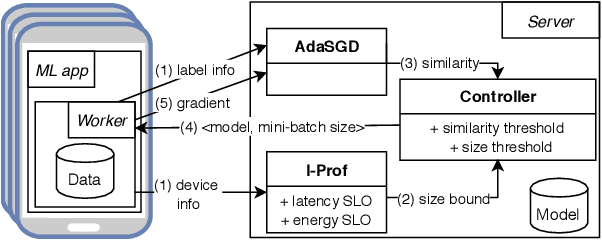
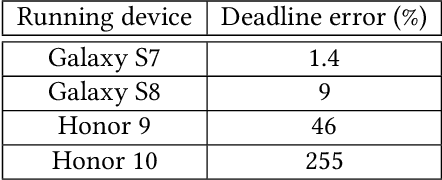
Federated Learning (FL) is very appealing for its privacy benefits: essentially, a global model is trained with updates computed on mobile devices while keeping the data of users local. Standard FL infrastructures are however designed to have no energy or performance impact on mobile devices, and are therefore not suitable for applications that require frequent (online) model updates, such as news recommenders. This paper presents FLeet, the first Online FL system, acting as a middleware between the Android OS and the machine learning application. FLeet combines the privacy of Standard FL with the precision of online learning thanks to two core components: (i) I-Prof, a new lightweight profiler that predicts and controls the impact of learning tasks on mobile devices, and (ii) AdaSGD, a new adaptive learning algorithm that is resilient to delayed updates. Our extensive evaluation shows that Online FL, as implemented by FLeet, can deliver a 2.3x quality boost compared to Standard FL, while only consuming 0.036% of the battery per day. I-Prof can accurately control the impact of learning tasks by improving the prediction accuracy up to 3.6x (computation time) and up to 19x (energy). AdaSGD outperforms alternative FL approaches by 18.4% in terms of convergence speed on heterogeneous data.
Host-Pathongen Co-evolution Inspired Algorithm Enables Robust GAN Training
Jun 09, 2020
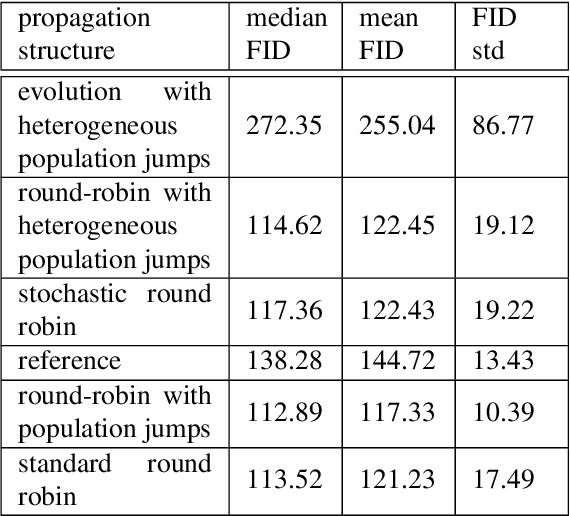
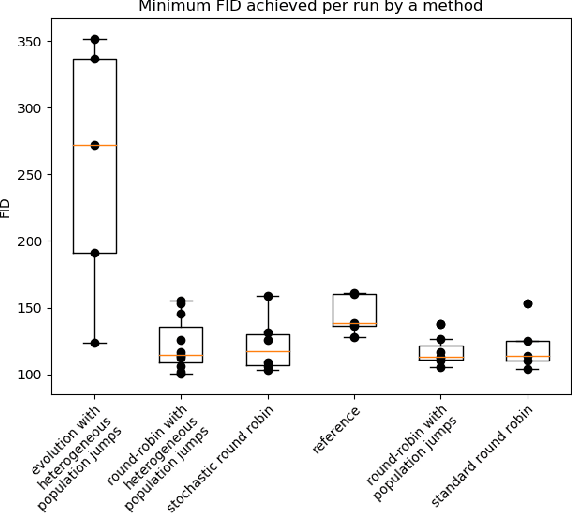
Generative adversarial networks (GANs) are pairs of artificial neural networks that are trained one against each other. The outputs from a generator are mixed with the real-world inputs to the discriminator and both networks are trained until an equilibrium is reached, where the discriminator cannot distinguish generated inputs from real ones. Since their introduction, GANs have allowed for the generation of impressive imitations of real-life films, images and texts, whose fakeness is barely noticeable to humans. Despite their impressive performance, training GANs remains to this day more of an art than a reliable procedure, in a large part due to training process stability. Generators are susceptible to mode dropping and convergence to random patterns, which have to be mitigated by computationally expensive multiple restarts. Curiously, GANs bear an uncanny similarity to a co-evolution of a pathogen and its host's immune system in biology. In a biological context, the majority of potential pathogens indeed never make it and are kept at bay by the hots' immune system. Yet some are efficient enough to present a risk of a serious condition and recurrent infections. Here, we explore that similarity to propose a more robust algorithm for GANs training. We empirically show the increased stability and a better ability to generate high-quality images while using less computational power.
Distributed Momentum for Byzantine-resilient Learning
Mar 09, 2020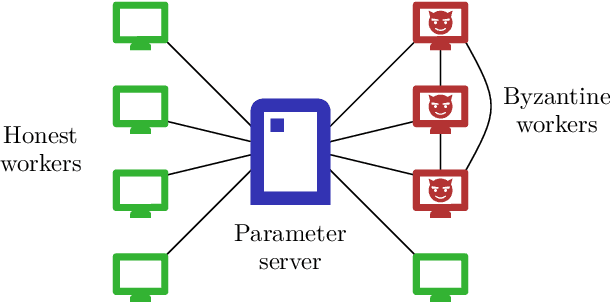
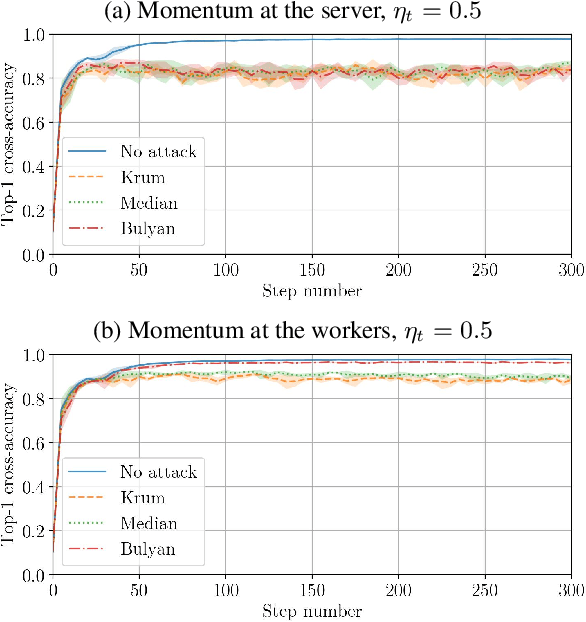
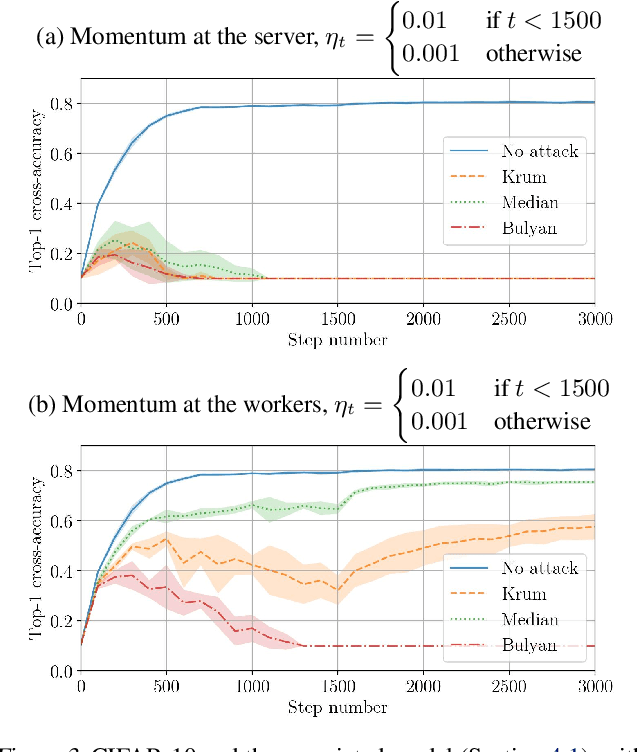
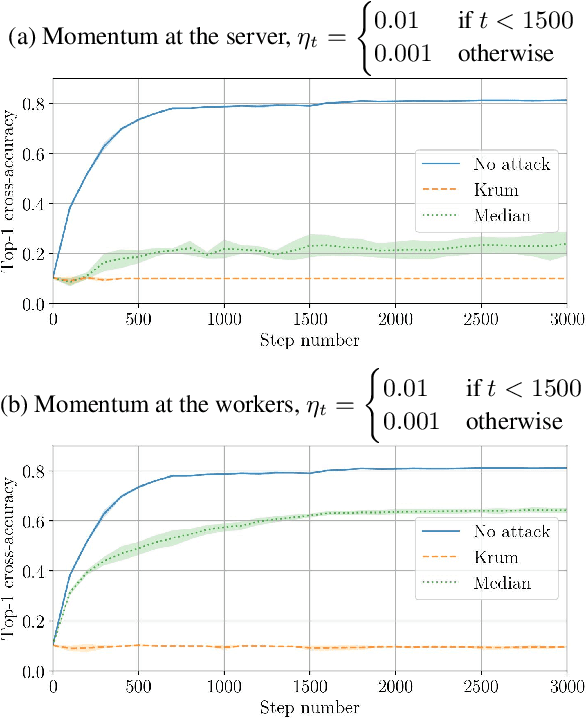
Momentum is a variant of gradient descent that has been proposed for its benefits on convergence. In a distributed setting, momentum can be implemented either at the server or the worker side. When the aggregation rule used by the server is linear, commutativity with addition makes both deployments equivalent. Robustness and privacy are however among motivations to abandon linear aggregation rules. In this work, we demonstrate the benefits on robustness of using momentum at the worker side. We first prove that computing momentum at the workers reduces the variance-norm ratio of the gradient estimation at the server, strengthening Byzantine resilient aggregation rules. We then provide an extensive experimental demonstration of the robustness effect of worker-side momentum on distributed SGD.
Fast Machine Learning with Byzantine Workers and Servers
Nov 18, 2019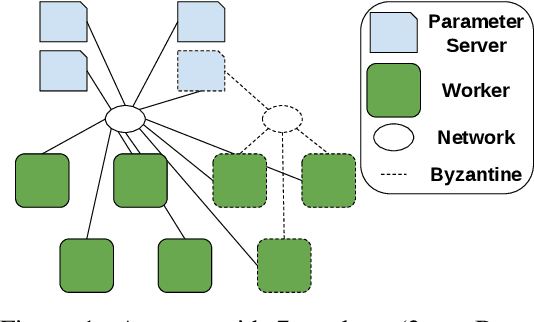
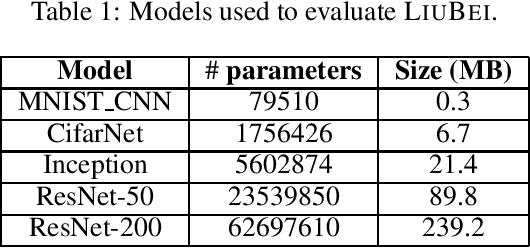
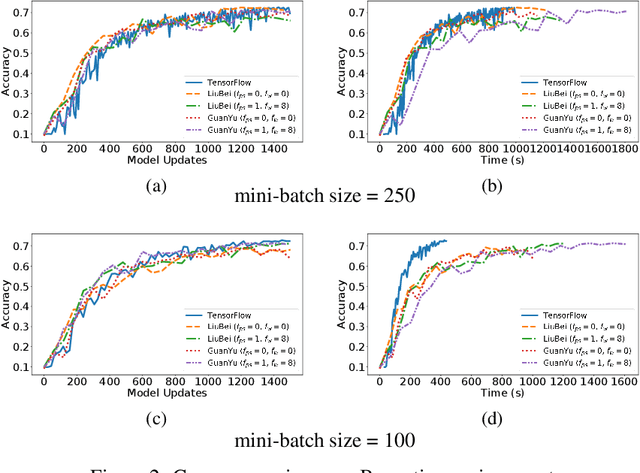
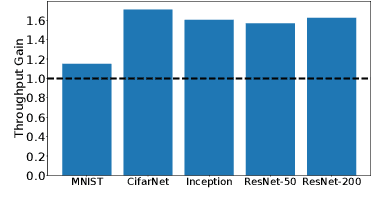
Machine Learning (ML) solutions are nowadays distributed and are prone to various types of component failures, which can be encompassed in so-called Byzantine behavior. This paper introduces LiuBei, a Byzantine-resilient ML algorithm that does not trust any individual component in the network (neither workers nor servers), nor does it induce additional communication rounds (on average), compared to standard non-Byzantine resilient algorithms. LiuBei builds upon gradient aggregation rules (GARs) to tolerate a minority of Byzantine workers. Besides, LiuBei replicates the parameter server on multiple machines instead of trusting it. We introduce a novel filtering mechanism that enables workers to filter out replies from Byzantine server replicas without requiring communication with all servers. Such a filtering mechanism is based on network synchrony, Lipschitz continuity of the loss function, and the GAR used to aggregate workers' gradients. We also introduce a protocol, scatter/gather, to bound drifts between models on correct servers with a small number of communication messages. We theoretically prove that LiuBei achieves Byzantine resilience to both servers and workers and guarantees convergence. We build LiuBei using TensorFlow, and we show that LiuBei tolerates Byzantine behavior with an accuracy loss of around 5% and around 24% convergence overhead compared to vanilla TensorFlow. We moreover show that the throughput gain of LiuBei compared to another state-of-the-art Byzantine-resilient ML algorithm (that assumes network asynchrony) is 70%.
Fast and Secure Distributed Learning in High Dimension
May 05, 2019
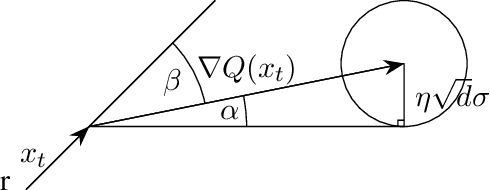
Modern machine learning is distributed and the work of several machines is typically aggregated by \emph{averaging} which is the optimal rule in terms of speed, offering a speedup of $n$ (with respect to using a single machine) when $n$ processes are learning together. Distributing data and models poses however fundamental vulnerabilities, be they to software bugs, asynchrony, or worse, to malicious attackers controlling some machines or injecting misleading data in the network. Such behavior is best modeled as Byzantine failures, and averaging does not tolerate a single one from a worker. Krum, the first provably Byzantine resilient aggregation rule for SGD only uses one worker per step, which hampers its speed of convergence, especially in best case conditions when none of the workers is actually Byzantine. An idea, coined multi-Krum, of using $m$ different workers per step was mentioned, without however any proof neither on its Byzantine resilience nor on its slowdown. More recently, it was shown that in high dimensional machine learning, guaranteeing convergence is not a sufficient condition for \emph{strong} Byzantine resilience. A improvement on Krum, coined Bulyan, was proposed and proved to guarantee stronger resilience. However, Bulyan suffers from the same weakness of Krum: using only one worker per step. This adds up to the aforementioned open problem and leaves the crucial need for both fast and strong Byzantine resilience unfulfilled. The present paper proposes using Bulyan over Multi-Krum (we call it Multi-Bulyan), a combination for which we provide proofs of strong Byzantine resilience, as well as an ${\frac{m}{n}}$ slowdown, compared to averaging, the fastest (but non Byzantine resilient) rule for distributed machine learning, finally we prove that Multi-Bulyan inherits the $O(d)$ merits of both multi-Krum and Bulyan.
SGD: Decentralized Byzantine Resilience
May 05, 2019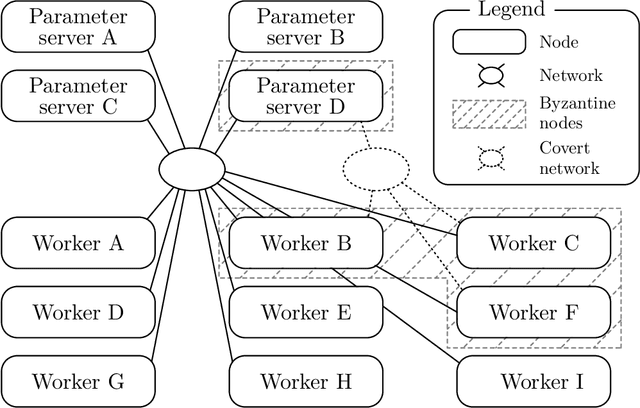

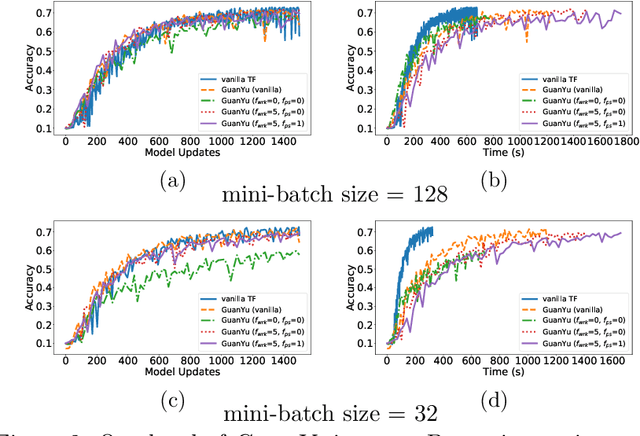
The size of the datasets available today leads to distribute Machine Learning (ML) tasks. An SGD--based optimization is for instance typically carried out by two categories of participants: parameter servers and workers. Some of these nodes can sometimes behave arbitrarily (called \emph{Byzantine} and caused by corrupt/bogus data/machines), impacting the accuracy of the entire learning activity. Several approaches recently studied how to tolerate Byzantine workers, while assuming honest and trusted parameter servers. In order to achieve total ML robustness, we introduce GuanYu, the first algorithm (to the best of our knowledge) to handle Byzantine parameter servers as well as Byzantine workers. We prove that GuanYu ensures convergence against $\frac{1}{3}$ Byzantine parameter servers and $\frac{1}{3}$ Byzantine workers, which is optimal in asynchronous networks (GuanYu does also tolerate unbounded communication delays, i.e.\ asynchrony). To prove the Byzantine resilience of GuanYu, we use a contraction argument, leveraging geometric properties of the median in high dimensional spaces to prevent (with probability 1) any drift on the models within each of the non-Byzantine servers. % To convey its practicality, we implemented GuanYu using the low-level TensorFlow APIs and deployed it in a distributed setup using the CIFAR-10 dataset. The overhead of tolerating Byzantine participants, compared to a vanilla TensorFlow deployment that is vulnerable to a single Byzantine participant, is around 30\% in terms of throughput (model updates per second) - while maintaining the same convergence rate (model updates required to reach some accuracy).
Fatal Brain Damage
Feb 05, 2019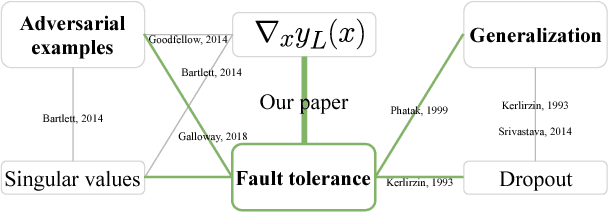

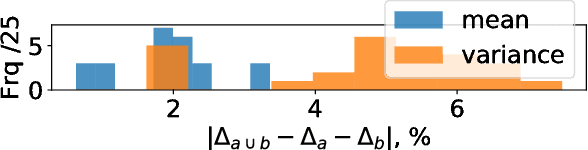
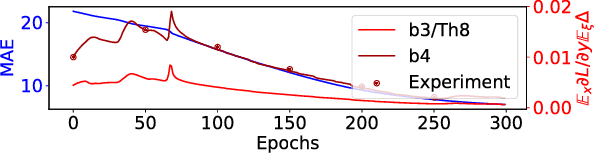
The loss of a few neurons in a brain often does not result in a visible loss of function. We propose to advance the understanding of neural networks through their remarkable ability to sustain individual neuron failures, i.e. their fault tolerance. Before the last AI winter, fault tolerance in NNs was a popular topic as NNs were expected to be implemented in neuromorphic hardware, which for a while did not happen. Moreover, since the number of possible crash subsets grows exponentially with the network size, additional assumptions are required to practically study this phenomenon for modern architectures. We prove a series of bounds on error propagation using justified assumptions, applicable to deep networks, show their location on the complexity versus tightness trade-off scale and test them empirically. We demonstrate how fault tolerance is connected to generalization and show that the data jacobian of a network determines its fault tolerance properties. We investigate this quantity and show how it is interlinked with other mathematical properties of the network such as Lipschitzness, singular values, weight matrices norms, and the loss gradients. Known results give a connection between the data jacobian and robustness to adversarial examples, providing another piece of the puzzle. Combining that with our results, we call for a unifying research endeavor encompassing fault tolerance, generalization capacity, and robustness to adversarial inputs together as we demonstrate a strong connection between these areas. Moreover, we argue that fault tolerance is an important overlooked AI safety problem since neuromorphic hardware is becoming popular again.
The Hidden Vulnerability of Distributed Learning in Byzantium
Jul 17, 2018
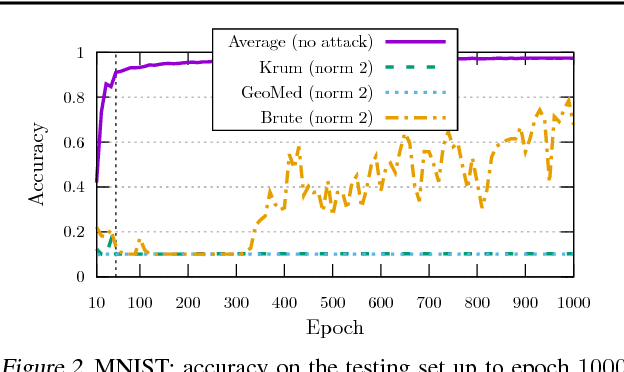
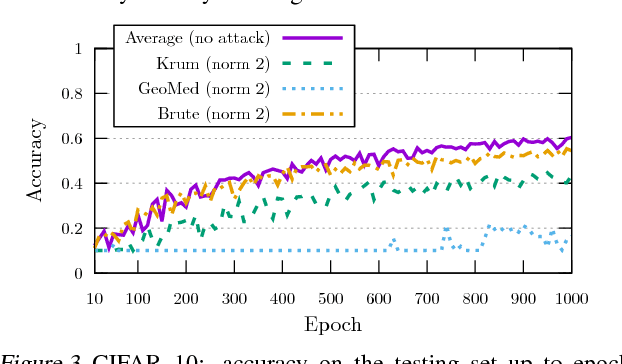
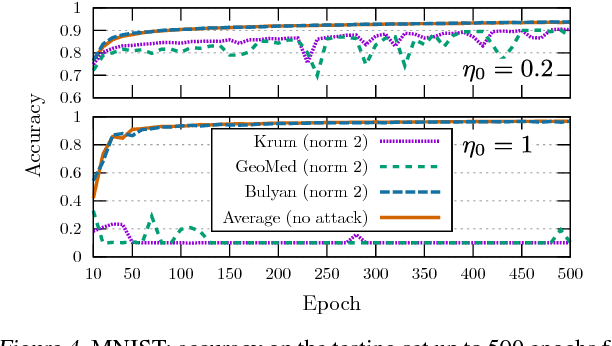
While machine learning is going through an era of celebrated success, concerns have been raised about the vulnerability of its backbone: stochastic gradient descent (SGD). Recent approaches have been proposed to ensure the robustness of distributed SGD against adversarial (Byzantine) workers sending poisoned gradients during the training phase. Some of these approaches have been proven Byzantine-resilient: they ensure the convergence of SGD despite the presence of a minority of adversarial workers. We show in this paper that convergence is not enough. In high dimension $d \gg 1$, an adver\-sary can build on the loss function's non-convexity to make SGD converge to ineffective models. More precisely, we bring to light that existing Byzantine-resilient schemes leave a margin of poisoning of $\Omega\left(f(d)\right)$, where $f(d)$ increases at least like $\sqrt{d~}$. Based on this leeway, we build a simple attack, and experimentally show its strong to utmost effectivity on CIFAR-10 and MNIST. We introduce Bulyan, and prove it significantly reduces the attackers leeway to a narrow $O( \frac{1}{\sqrt{d~}})$ bound. We empirically show that Bulyan does not suffer the fragility of existing aggregation rules and, at a reasonable cost in terms of required batch size, achieves convergence as if only non-Byzantine gradients had been used to update the model.
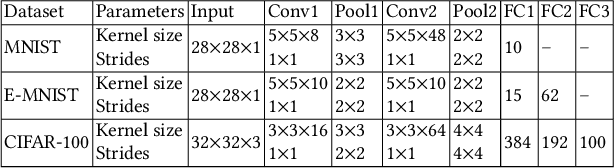
Asynchronous Byzantine Machine Learning (the case of SGD)
Jul 09, 2018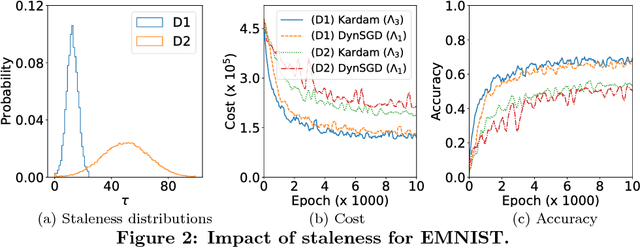
Asynchronous distributed machine learning solutions have proven very effective so far, but always assuming perfectly functioning workers. In practice, some of the workers can however exhibit Byzantine behavior, caused by hardware failures, software bugs, corrupt data, or even malicious attacks. We introduce \emph{Kardam}, the first distributed asynchronous stochastic gradient descent (SGD) algorithm that copes with Byzantine workers. Kardam consists of two complementary components: a filtering and a dampening component. The first is scalar-based and ensures resilience against $\frac{1}{3}$ Byzantine workers. Essentially, this filter leverages the Lipschitzness of cost functions and acts as a self-stabilizer against Byzantine workers that would attempt to corrupt the progress of SGD. The dampening component bounds the convergence rate by adjusting to stale information through a generic gradient weighting scheme. We prove that Kardam guarantees almost sure convergence in the presence of asynchrony and Byzantine behavior, and we derive its convergence rate. We evaluate Kardam on the CIFAR-100 and EMNIST datasets and measure its overhead with respect to non Byzantine-resilient solutions. We empirically show that Kardam does not introduce additional noise to the learning procedure but does induce a slowdown (the cost of Byzantine resilience) that we both theoretically and empirically show to be less than $f/n$, where $f$ is the number of Byzantine failures tolerated and $n$ the total number of workers. Interestingly, we also empirically observe that the dampening component is interesting in its own right for it enables to build an SGD algorithm that outperforms alternative staleness-aware asynchronous competitors in environments with honest workers.