 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk, Acquire, and Attack: Data-free UAP Generation using Class Impressions
Aug 03, 2018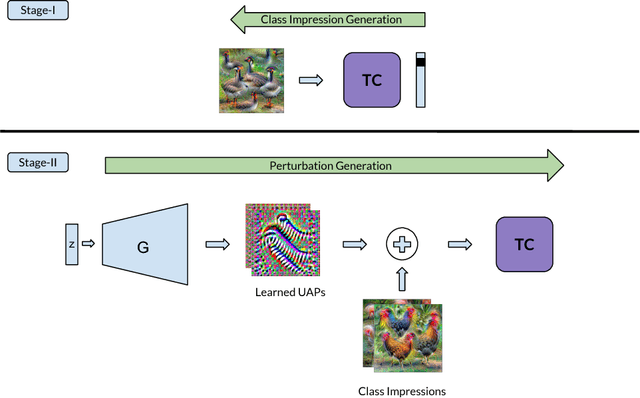
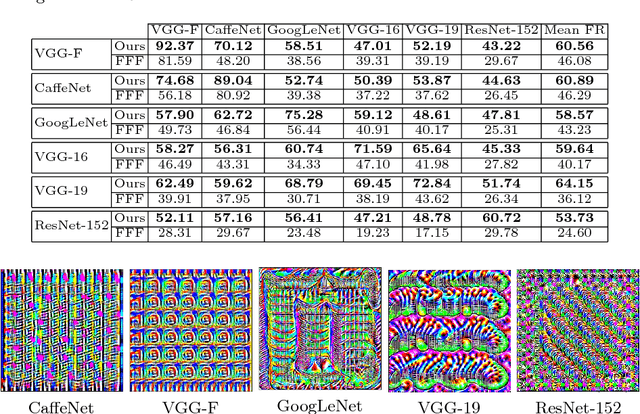

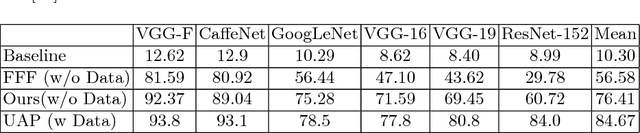
Deep learning models are susceptible to input specific noise, called adversarial perturbations. Moreover, there exist input-agnostic noise, called Universal Adversarial Perturbations (UAP) that can affect inference of the models over most input samples. Given a model, there exist broadly two approaches to craft UAPs: (i) data-driven: that require data, and (ii) data-free: that do not require data samples. Data-driven approaches require actual samples from the underlying data distribution and craft UAPs with high success (fooling) rate. However, data-free approaches craft UAPs without utilizing any data samples and therefore result in lesser success rates. In this paper, for data-free scenarios, we propose a novel approach that emulates the effect of data samples with class impressions in order to craft UAPs using data-driven objectives. Class impression for a given pair of category and model is a generic representation (in the input space) of the samples belonging to that category. Further, we present a neural network based generative model that utilizes the acquired class impressions to learn crafting UAPs. Experimental evaluation demonstrates that the learned generative model, (i) readily crafts UAPs via simple feed-forwarding through neural network layers, and (ii) achieves state-of-the-art success rates for data-free scenario and closer to that for data-driven setting without actually utilizing any data samples.
iSPA-Net: Iterative Semantic Pose Alignment Network
Aug 03, 2018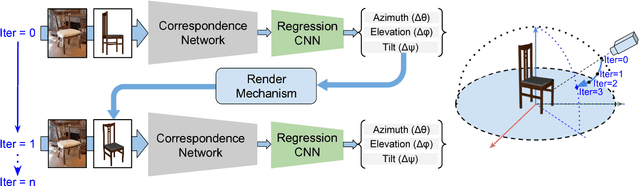
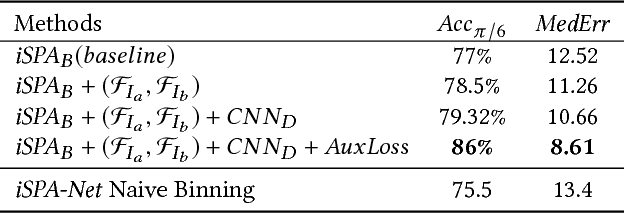
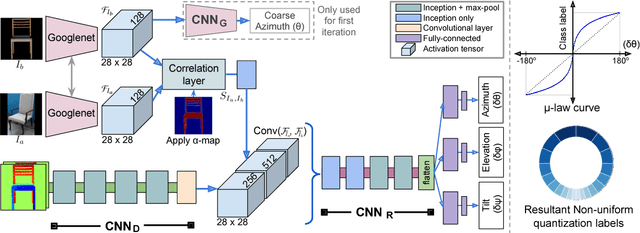
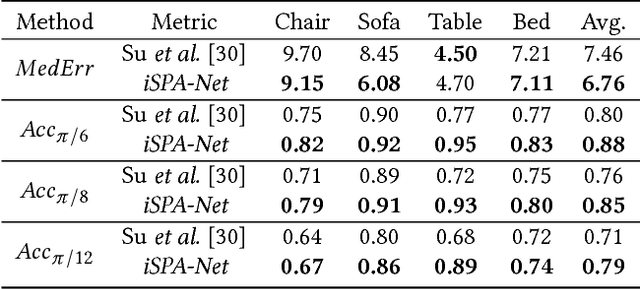
Understanding and extracting 3D information of objects from monocular 2D images is a fundamental problem in computer vision. In the task of 3D object pose estimation, recent data driven deep neural network based approaches suffer from scarcity of real images with 3D keypoint and pose annotations. Drawing inspiration from human cognition, where the annotators use a 3D CAD model as structural reference to acquire ground-truth viewpoints for real images; we propose an iterative Semantic Pose Alignment Network, called iSPA-Net. Our approach focuses on exploiting semantic 3D structural regularity to solve the task of fine-grained pose estimation by predicting viewpoint difference between a given pair of images. Such image comparison based approach also alleviates the problem of data scarcity and hence enhances scalability of the proposed approach for novel object categories with minimal annotation. The fine-grained object pose estimator is also aided by correspondence of learned spatial descriptor of the input image pair. The proposed pose alignment framework enjoys the faculty to refine its initial pose estimation in consecutive iterations by utilizing an online rendering setup along with effectiveness of a non-uniform bin classification of pose-difference. This enables iSPA-Net to achieve state-of-the-art performance on various real image viewpoint estimation datasets. Further, we demonstrate effectiveness of the approach for multiple applications. First, we show results for active object viewpoint localization to capture images from similar pose considering only a single image as pose reference. Second, we demonstrate the ability of the learned semantic correspondence to perform unsupervised part-segmentation transfer using only a single part-annotated 3D template model per object class. To encourage reproducible research, we have released the codes for our proposed algorithm.
Top-Down Feedback for Crowd Counting Convolutional Neural Network
Jul 27, 2018
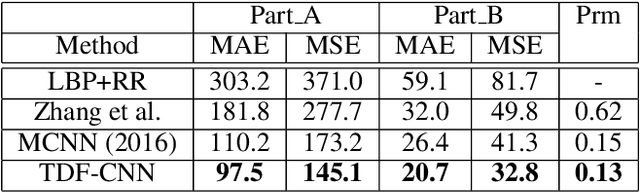
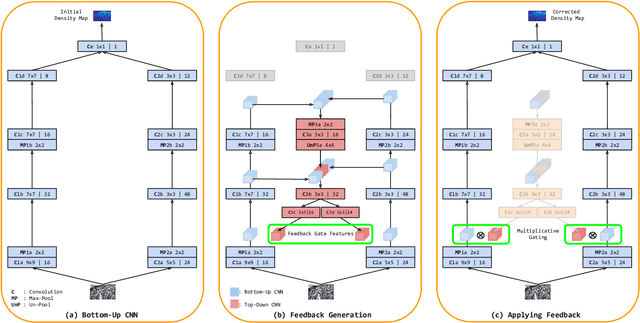
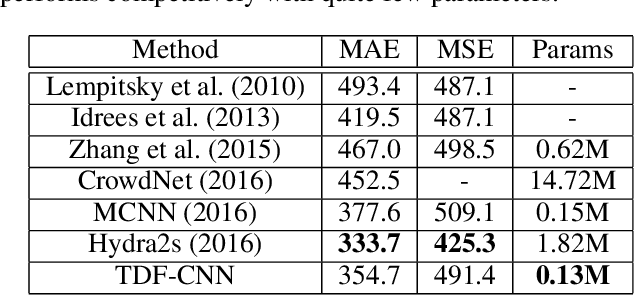
Counting people in dense crowds is a demanding task even for humans. This is primarily due to the large variability in appearance of people. Often people are only seen as a bunch of blobs. Occlusions, pose variations and background clutter further compound the difficulty. In this scenario, identifying a person requires larger spatial context and semantics of the scene. But the current state-of-the-art CNN regressors for crowd counting are feedforward and use only limited spatial context to detect people. They look for local crowd patterns to regress the crowd density map, resulting in false predictions. Hence, we propose top-down feedback to correct the initial prediction of the CNN. Our architecture consists of a bottom-up CNN along with a separate top-down CNN to generate feedback. The bottom-up network, which regresses the crowd density map, has two columns of CNN with different receptive fields. Features from various layers of the bottom-up CNN are fed to the top-down network. The feedback, thus generated, is applied on the lower layers of the bottom-up network in the form of multiplicative gating. This masking weighs activations of the bottom-up network at spatial as well as feature levels to correct the density prediction. We evaluate the performance of our model on all major crowd datasets and show the effectiveness of top-down feedback.
Divide and Grow: Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN
Jul 26, 2018
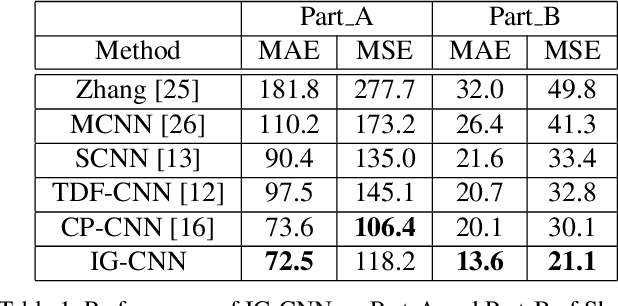
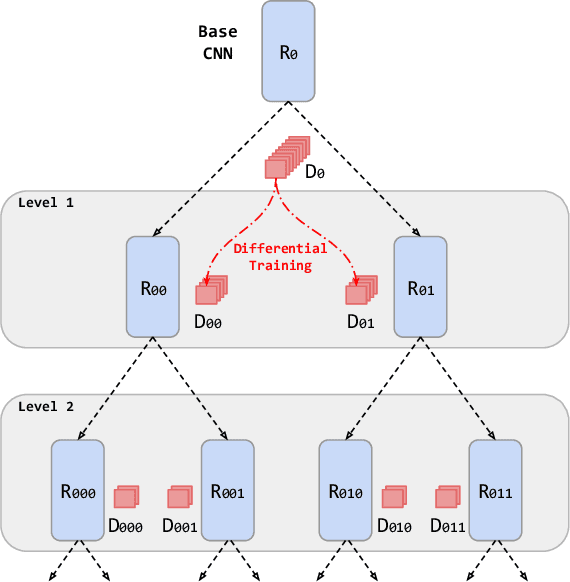
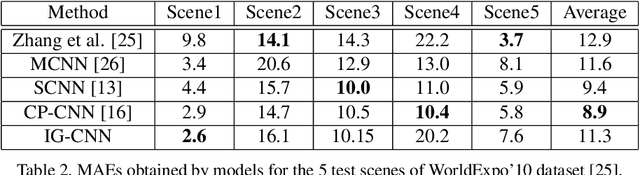
Automated counting of people in crowd images is a challenging task. The major difficulty stems from the large diversity in the way people appear in crowds. In fact, features available for crowd discrimination largely depend on the crowd density to the extent that people are only seen as blobs in a highly dense scene. We tackle this problem with a growing CNN which can progressively increase its capacity to account for the wide variability seen in crowd scenes. Our model starts from a base CNN density regressor, which is trained in equivalence on all types of crowd images. In order to adapt with the huge diversity, we create two child regressors which are exact copies of the base CNN. A differential training procedure divides the dataset into two clusters and fine-tunes the child networks on their respective specialties. Consequently, without any hand-crafted criteria for forming specialties, the child regressors become experts on certain types of crowds. The child networks are again split recursively, creating two experts at every division. This hierarchical training leads to a CNN tree, where the child regressors are more fine experts than any of their parents. The leaf nodes are taken as the final experts and a classifier network is then trained to predict the correct specialty for a given test image patch. The proposed model achieves higher count accuracy on major crowd datasets. Further, we analyse the characteristics of specialties mined automatically by our method.
Generalizable Data-free Objective for Crafting Universal Adversarial Perturbations
Jul 24, 2018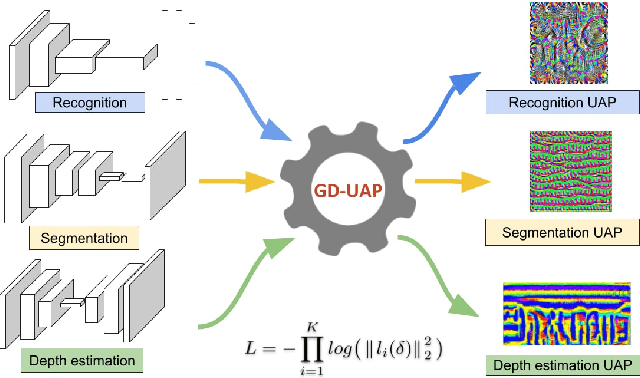
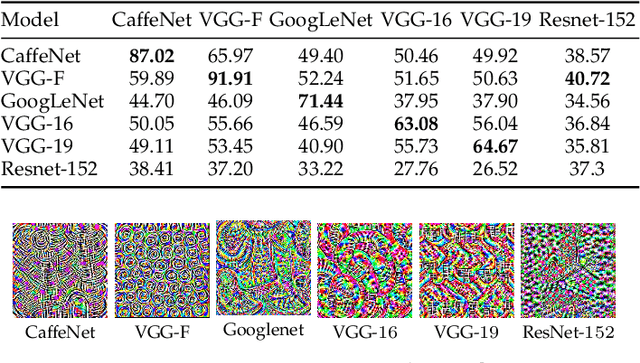
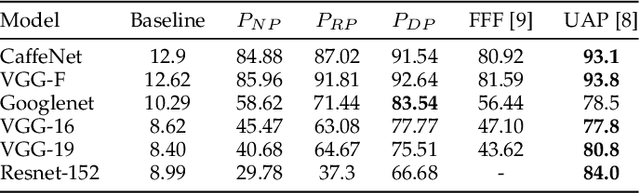

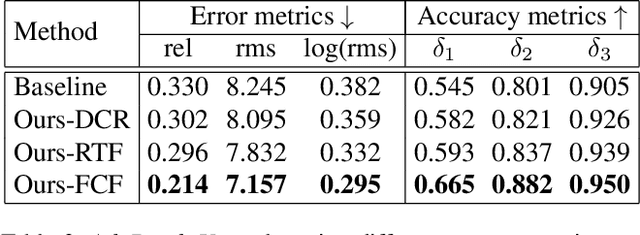
Machine learning models are susceptible to adversarial perturbations: small changes to input that can cause large changes in output. It is also demonstrated that there exist input-agnostic perturbations, called universal adversarial perturbations, which can change the inference of target model on most of the data samples. However, existing methods to craft universal perturbations are (i) task specific, (ii) require samples from the training data distribution, and (iii) perform complex optimizations. Additionally, because of the data dependence, fooling ability of the crafted perturbations is proportional to the available training data. In this paper, we present a novel, generalizable and data-free approaches for crafting universal adversarial perturbations. Independent of the underlying task, our objective achieves fooling via corrupting the extracted features at multiple layers. Therefore, the proposed objective is generalizable to craft image-agnostic perturbations across multiple vision tasks such as object recognition, semantic segmentation, and depth estimation. In the practical setting of black-box attack scenario (when the attacker does not have access to the target model and it's training data), we show that our objective outperforms the data dependent objectives to fool the learned models. Further, via exploiting simple priors related to the data distribution, our objective remarkably boosts the fooling ability of the crafted perturbations. Significant fooling rates achieved by our objective emphasize that the current deep learning models are now at an increased risk, since our objective generalizes across multiple tasks without the requirement of training data for crafting the perturbations. To encourage reproducible research, we have released the codes for our proposed algorithm.
3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image
Jul 20, 2018

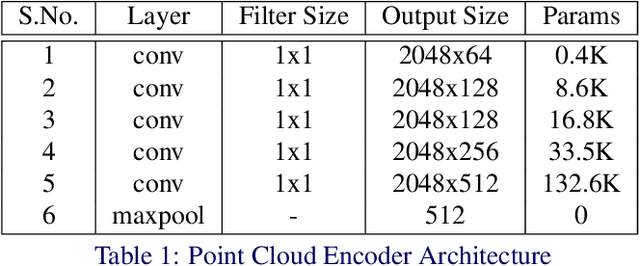

3D reconstruction from single view images is an ill-posed problem. Inferring the hidden regions from self-occluded images is both challenging and ambiguous. We propose a two-pronged approach to address these issues. To better incorporate the data prior and generate meaningful reconstructions, we propose 3D-LMNet, a latent embedding matching approach for 3D reconstruction. We first train a 3D point cloud auto-encoder and then learn a mapping from the 2D image to the corresponding learnt embedding. To tackle the issue of uncertainty in the reconstruction, we predict multiple reconstructions that are consistent with the input view. This is achieved by learning a probablistic latent space with a novel view-specific diversity loss. Thorough quantitative and qualitative analysis is performed to highlight the significance of the proposed approach. We outperform state-of-the-art approaches on the task of single-view 3D reconstruction on both real and synthetic datasets while generating multiple plausible reconstructions, demonstrating the generalizability and utility of our approach.
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
Jun 07, 2018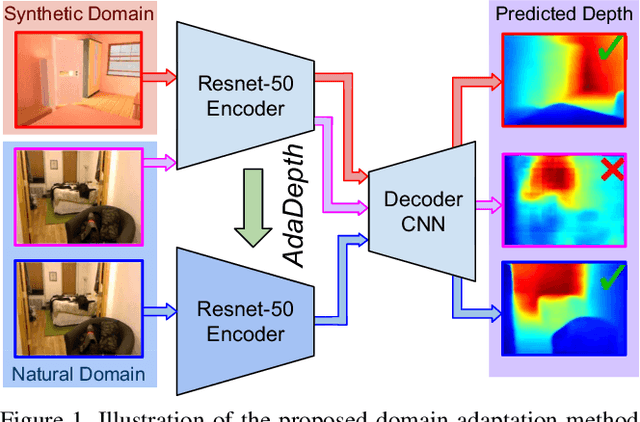
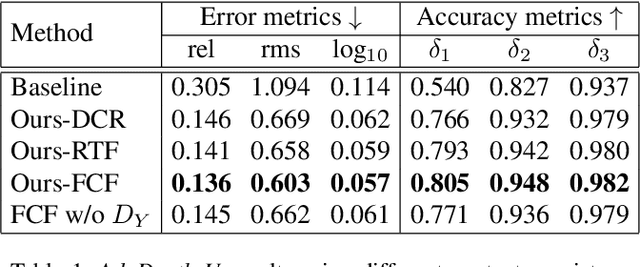
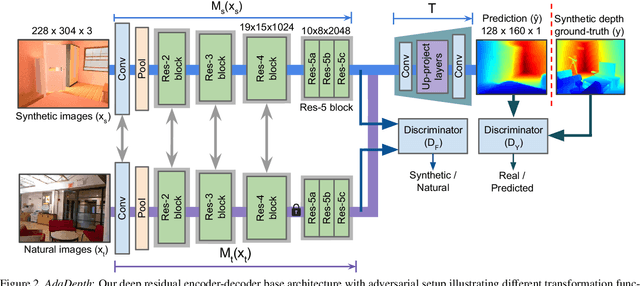
Supervised deep learning methods have shown promising results for the task of monocular depth estimation; but acquiring ground truth is costly, and prone to noise as well as inaccuracies. While synthetic datasets have been used to circumvent above problems, the resultant models do not generalize well to natural scenes due to the inherent domain shift. Recent adversarial approaches for domain adaption have performed well in mitigating the differences between the source and target domains. But these methods are mostly limited to a classification setup and do not scale well for fully-convolutional architectures. In this work, we propose AdaDepth - an unsupervised domain adaptation strategy for the pixel-wise regression task of monocular depth estimation. The proposed approach is devoid of above limitations through a) adversarial learning and b) explicit imposition of content consistency on the adapted target representation. Our unsupervised approach performs competitively with other established approaches on depth estimation tasks and achieves state-of-the-art results in a semi-supervised setting.
NAG: Network for Adversary Generation
Mar 28, 2018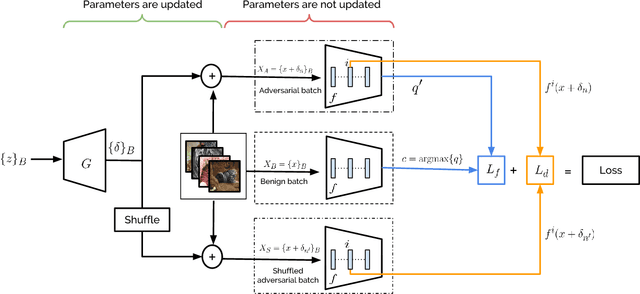
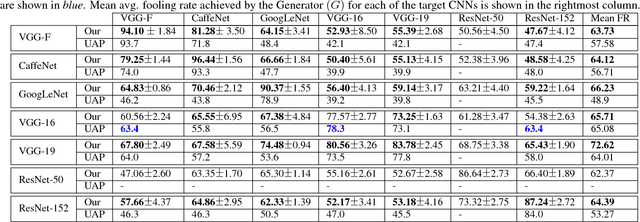
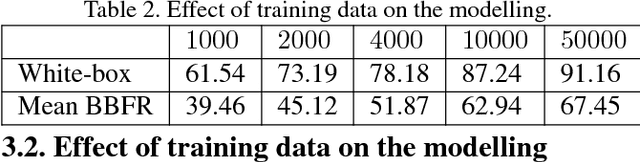

Adversarial perturbations can pose a serious threat for deploying machine learning systems. Recent works have shown existence of image-agnostic perturbations that can fool classifiers over most natural images. Existing methods present optimization approaches that solve for a fooling objective with an imperceptibility constraint to craft the perturbations. However, for a given classifier, they generate one perturbation at a time, which is a single instance from the manifold of adversarial perturbations. Also, in order to build robust models, it is essential to explore the manifold of adversarial perturbations. In this paper, we propose for the first time, a generative approach to model the distribution of adversarial perturbations. The architecture of the proposed model is inspired from that of GANs and is trained using fooling and diversity objectives. Our trained generator network attempts to capture the distribution of adversarial perturbations for a given classifier and readily generates a wide variety of such perturbations. Our experimental evaluation demonstrates that perturbations crafted by our model (i) achieve state-of-the-art fooling rates, (ii) exhibit wide variety and (iii) deliver excellent cross model generalizability. Our work can be deemed as an important step in the process of inferring about the complex manifolds of adversarial perturbations.
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
Dec 20, 2017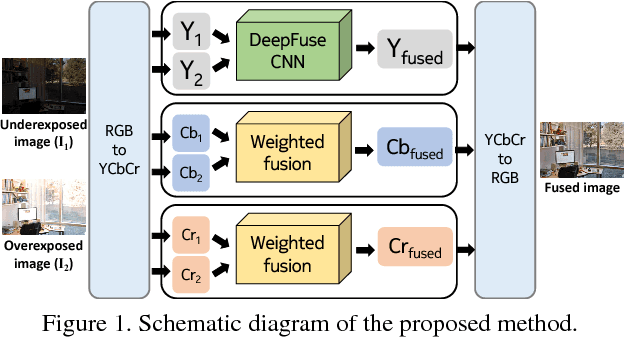
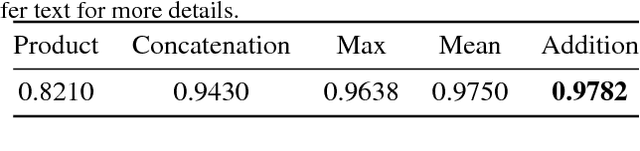
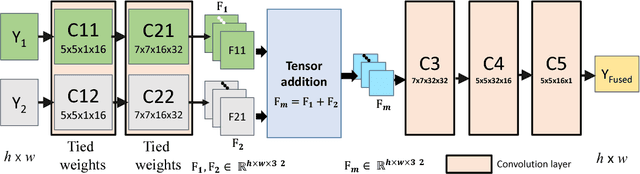
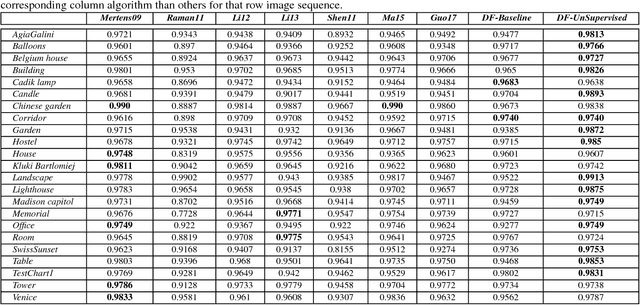
We present a novel deep learning architecture for fusing static multi-exposure images. Current multi-exposure fusion (MEF) approaches use hand-crafted features to fuse input sequence. However, the weak hand-crafted representations are not robust to varying input conditions. Moreover, they perform poorly for extreme exposure image pairs. Thus, it is highly desirable to have a method that is robust to varying input conditions and capable of handling extreme exposure without artifacts. Deep representations have known to be robust to input conditions and have shown phenomenal performance in a supervised setting. However, the stumbling block in using deep learning for MEF was the lack of sufficient training data and an oracle to provide the ground-truth for supervision. To address the above issues, we have gathered a large dataset of multi-exposure image stacks for training and to circumvent the need for ground truth images, we propose an unsupervised deep learning framework for MEF utilizing a no-reference quality metric as loss function. The proposed approach uses a novel CNN architecture trained to learn the fusion operation without reference ground truth image. The model fuses a set of common low level features extracted from each image to generate artifact-free perceptually pleasing results. We perform extensive quantitative and qualitative evaluation and show that the proposed technique outperforms existing state-of-the-art approaches for a variety of natural images.
SketchParse : Towards Rich Descriptions for Poorly Drawn Sketches using Multi-Task Hierarchical Deep Networks
Sep 05, 2017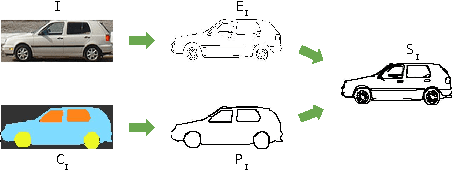

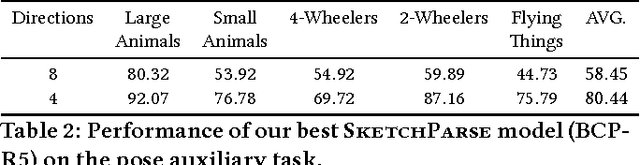

The ability to semantically interpret hand-drawn line sketches, although very challenging, can pave way for novel applications in multimedia. We propose SketchParse, the first deep-network architecture for fully automatic parsing of freehand object sketches. SketchParse is configured as a two-level fully convolutional network. The first level contains shared layers common to all object categories. The second level contains a number of expert sub-networks. Each expert specializes in parsing sketches from object categories which contain structurally similar parts. Effectively, the two-level configuration enables our architecture to scale up efficiently as additional categories are added. We introduce a router layer which (i) relays sketch features from shared layers to the correct expert (ii) eliminates the need to manually specify object category during inference. To bypass laborious part-level annotation, we sketchify photos from semantic object-part image datasets and use them for training. Our architecture also incorporates object pose prediction as a novel auxiliary task which boosts overall performance while providing supplementary information regarding the sketch. We demonstrate SketchParse's abilities (i) on two challenging large-scale sketch datasets (ii) in parsing unseen, semantically related object categories (iii) in improving fine-grained sketch-based image retrieval. As a novel application, we also outline how SketchParse's output can be used to generate caption-style descriptions for hand-drawn sketches.