 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformed Low-Rank Parameterization Can Help Robust Generalization for Tensor Neural Networks
Mar 01, 2023
Achieving efficient and robust multi-channel data learning is a challenging task in data science. By exploiting low-rankness in the transformed domain, i.e., transformed low-rankness, tensor Singular Value Decomposition (t-SVD) has achieved extensive success in multi-channel data representation and has recently been extended to function representation such as Neural Networks with t-product layers (t-NNs). However, it still remains unclear how t-SVD theoretically affects the learning behavior of t-NNs. This paper is the first to answer this question by deriving the upper bounds of the generalization error of both standard and adversarially trained t-NNs. It reveals that the t-NNs compressed by exact transformed low-rank parameterization can achieve a sharper adversarial generalization bound. In practice, although t-NNs rarely have exactly transformed low-rank weights, our analysis further shows that by adversarial training with gradient flow (GF), the over-parameterized t-NNs with ReLU activations are trained with implicit regularization towards transformed low-rank parameterization under certain conditions. We also establish adversarial generalization bounds for t-NNs with approximately transformed low-rank weights. Our analysis indicates that the transformed low-rank parameterization can promisingly enhance robust generalization for t-NNs.
Towards Efficient and Accurate Approximation: Tensor Decomposition Based on Randomized Block Krylov Iteration
Nov 27, 2022



Efficient and accurate low-rank approximation (LRA) methods are of great significance for large-scale data analysis. Randomized tensor decompositions have emerged as powerful tools to meet this need, but most existing methods perform poorly in the presence of noise interference. Inspired by the remarkable performance of randomized block Krylov iteration (rBKI) in reducing the effect of tail singular values, this work designs an rBKI-based Tucker decomposition (rBKI-TK) for accurate approximation, together with a hierarchical tensor ring decomposition based on rBKI-TK for efficient compression of large-scale data. Besides, the error bound between the deterministic LRA and the randomized LRA is studied. Numerical experiences demonstrate the efficiency, accuracy and scalability of the proposed methods in both data compression and denoising.
Permutation Search of Tensor Network Structures via Local Sampling
Jun 14, 2022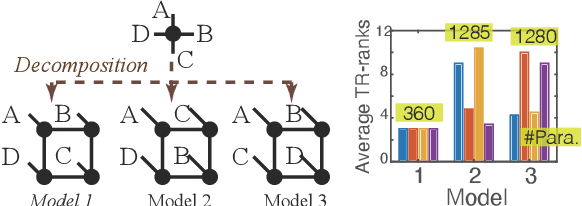
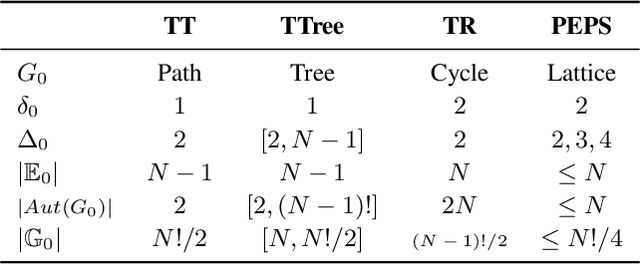
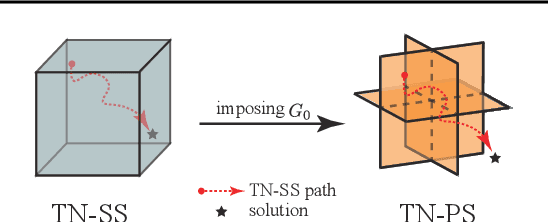
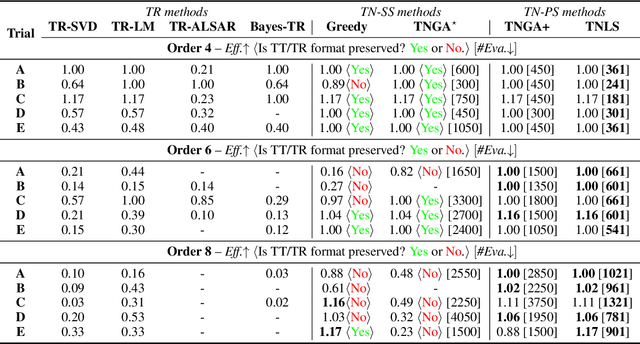
Recent works put much effort into tensor network structure search (TN-SS), aiming to select suitable tensor network (TN) structures, involving the TN-ranks, formats, and so on, for the decomposition or learning tasks. In this paper, we consider a practical variant of TN-SS, dubbed TN permutation search (TN-PS), in which we search for good mappings from tensor modes onto TN vertices (core tensors) for compact TN representations. We conduct a theoretical investigation of TN-PS and propose a practically-efficient algorithm to resolve the problem. Theoretically, we prove the counting and metric properties of search spaces of TN-PS, analyzing for the first time the impact of TN structures on these unique properties. Numerically, we propose a novel meta-heuristic algorithm, in which the searching is done by randomly sampling in a neighborhood established in our theory, and then recurrently updating the neighborhood until convergence. Numerical results demonstrate that the new algorithm can reduce the required model size of TNs in extensive benchmarks, implying the improvement in the expressive power of TNs. Furthermore, the computational cost for the new algorithm is significantly less than that in~\cite{li2020evolutionary}.
SPD domain-specific batch normalization to crack interpretable unsupervised domain adaptation in EEG
Jun 02, 2022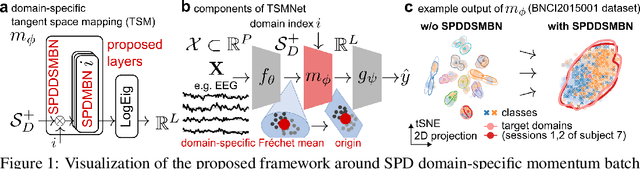
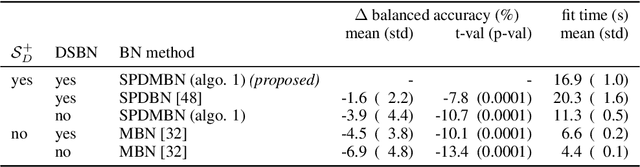
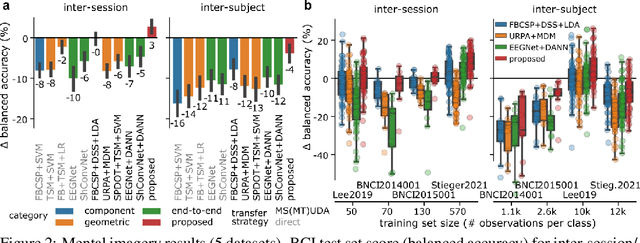
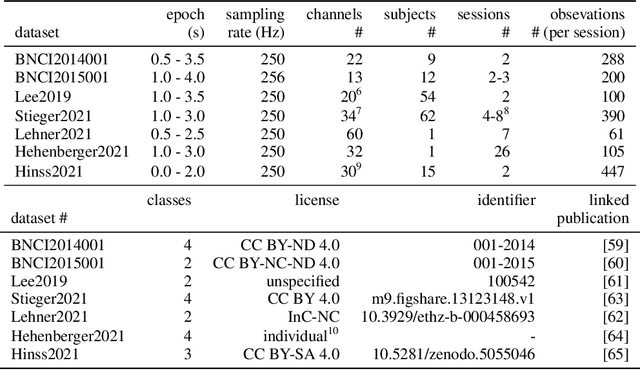
Electroencephalography (EEG) provides access to neuronal dynamics non-invasively with millisecond resolution, rendering it a viable method in neuroscience and healthcare. However, its utility is limited as current EEG technology does not generalize well across domains (i.e., sessions and subjects) without expensive supervised re-calibration. Contemporary methods cast this transfer learning (TL) problem as a multi-source/-target unsupervised domain adaptation (UDA) problem and address it with deep learning or shallow, Riemannian geometry aware alignment methods. Both directions have, so far, failed to consistently close the performance gap to state-of-the-art domain-specific methods based on tangent space mapping (TSM) on the symmetric positive definite (SPD) manifold. Here, we propose a theory-based machine learning framework that enables, for the first time, learning domain-invariant TSM models in an end-to-end fashion. To achieve this, we propose a new building block for geometric deep learning, which we denote SPD domain-specific momentum batch normalization (SPDDSMBN). A SPDDSMBN layer can transform domain-specific SPD inputs into domain-invariant SPD outputs, and can be readily applied to multi-source/-target and online UDA scenarios. In extensive experiments with 6 diverse EEG brain-computer interface (BCI) datasets, we obtain state-of-the-art performance in inter-session and -subject TL with a simple, intrinsically interpretable network architecture, which we denote TSMNet.
Noisy Tensor Completion via Low-rank Tensor Ring
Mar 14, 2022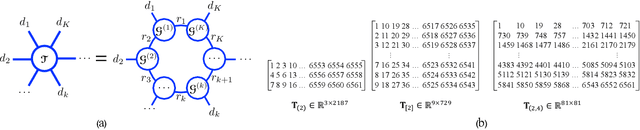
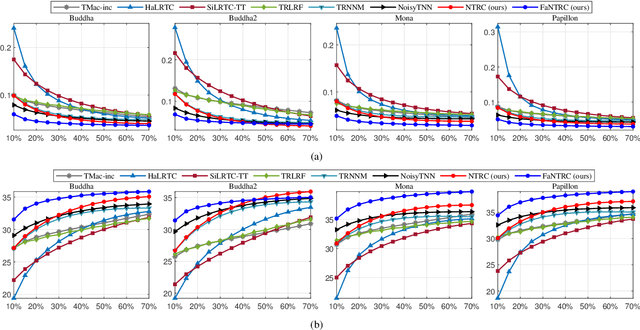
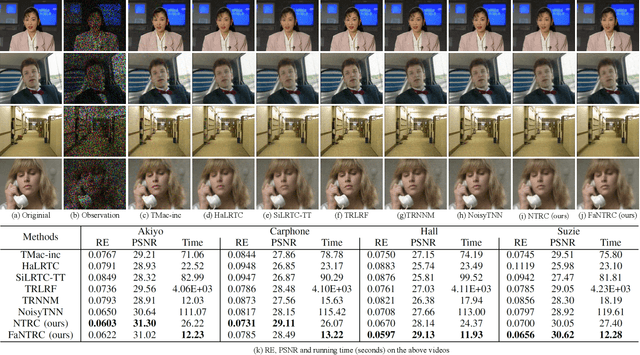
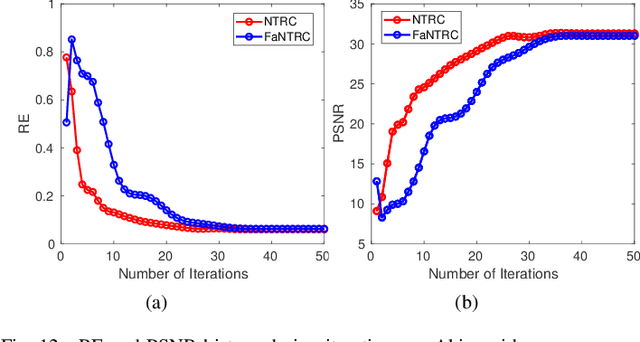
Tensor completion is a fundamental tool for incomplete data analysis, where the goal is to predict missing entries from partial observations. However, existing methods often make the explicit or implicit assumption that the observed entries are noise-free to provide a theoretical guarantee of exact recovery of missing entries, which is quite restrictive in practice. To remedy such drawbacks, this paper proposes a novel noisy tensor completion model, which complements the incompetence of existing works in handling the degeneration of high-order and noisy observations. Specifically, the tensor ring nuclear norm (TRNN) and least-squares estimator are adopted to regularize the underlying tensor and the observed entries, respectively. In addition, a non-asymptotic upper bound of estimation error is provided to depict the statistical performance of the proposed estimator. Two efficient algorithms are developed to solve the optimization problem with convergence guarantee, one of which is specially tailored to handle large-scale tensors by replacing the minimization of TRNN of the original tensor equivalently with that of a much smaller one in a heterogeneous tensor decomposition framework. Experimental results on both synthetic and real-world data demonstrate the effectiveness and efficiency of the proposed model in recovering noisy incomplete tensor data compared with state-of-the-art tensor completion models.
Multi-view Data Classification with a Label-driven Auto-weighted Strategy
Jan 03, 2022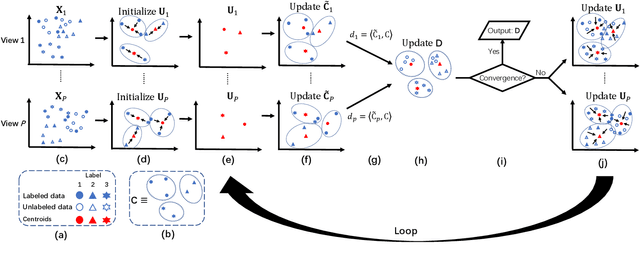
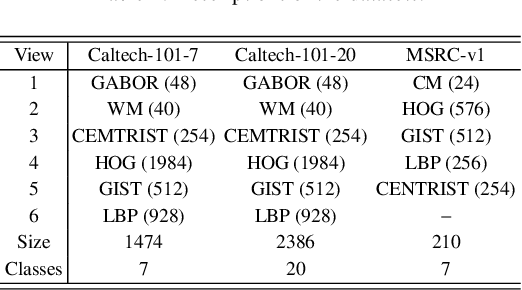
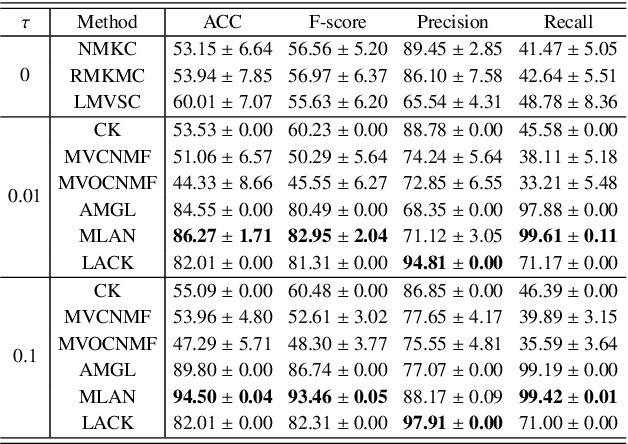
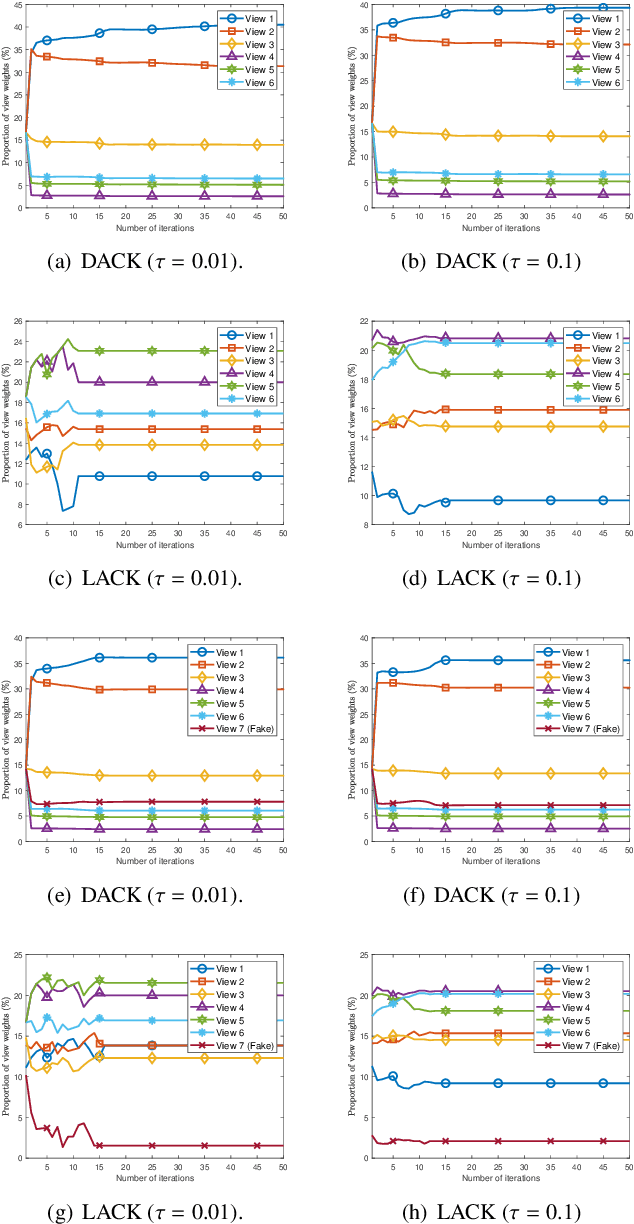
Distinguishing the importance of views has proven to be quite helpful for semi-supervised multi-view learning models. However, existing strategies cannot take advantage of semi-supervised information, only distinguishing the importance of views from a data feature perspective, which is often influenced by low-quality views then leading to poor performance. In this paper, by establishing a link between labeled data and the importance of different views, we propose an auto-weighted strategy to evaluate the importance of views from a label perspective to avoid the negative impact of unimportant or low-quality views. Based on this strategy, we propose a transductive semi-supervised auto-weighted multi-view classification model. The initialization of the proposed model can be effectively determined by labeled data, which is practical. The model is decoupled into three small-scale sub-problems that can efficiently be optimized with a local convergence guarantee. The experimental results on classification tasks show that the proposed method achieves optimal or sub-optimal classification accuracy at the lowest computational cost compared to other related methods, and the weight change experiments show that our proposed strategy can distinguish view importance more accurately than other related strategies on multi-view datasets with low-quality views.
Efficient Tensor Robust PCA under Hybrid Model of Tucker and Tensor Train
Dec 20, 2021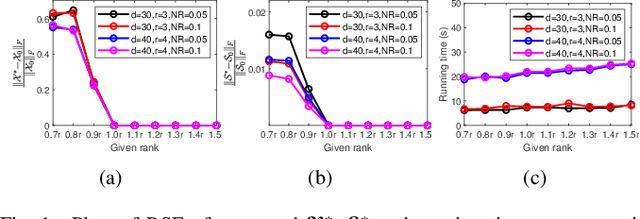

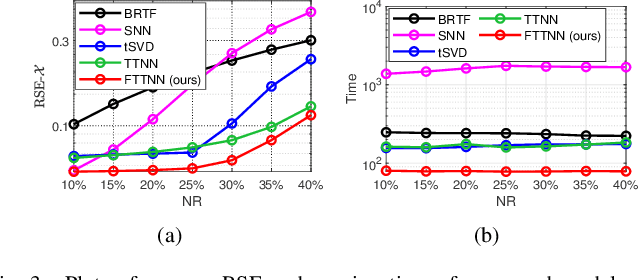
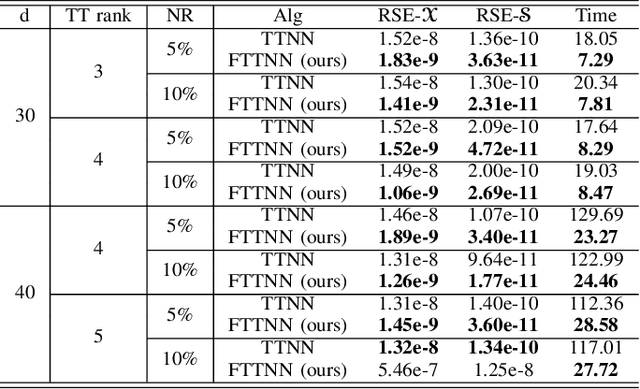
Tensor robust principal component analysis (TRPCA) is a fundamental model in machine learning and computer vision. Recently, tensor train (TT) decomposition has been verified effective to capture the global low-rank correlation for tensor recovery tasks. However, due to the large-scale tensor data in real-world applications, previous TRPCA models often suffer from high computational complexity. In this letter, we propose an efficient TRPCA under hybrid model of Tucker and TT. Specifically, in theory we reveal that TT nuclear norm (TTNN) of the original big tensor can be equivalently converted to that of a much smaller tensor via a Tucker compression format, thereby significantly reducing the computational cost of singular value decomposition (SVD). Numerical experiments on both synthetic and real-world tensor data verify the superiority of the proposed model.
Understanding Convolutional Neural Networks from Theoretical Perspective via Volterra Convolution
Oct 19, 2021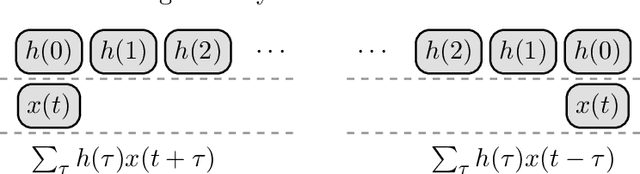

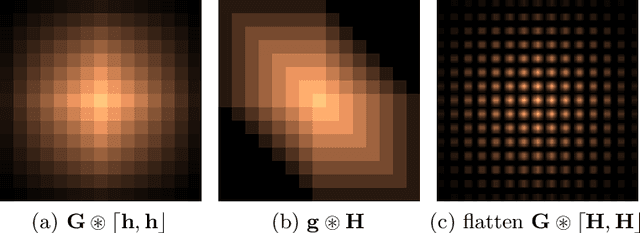
This study proposes a general and unified perspective of convolutional neural networks by exploring the relationship between (deep) convolutional neural networks and finite Volterra convolutions. It provides a novel approach to explain and study the overall characteristics of neural networks without being disturbed by the complex network architectures. Concretely, we examine the basic structures of finite term Volterra convolutions and convolutional neural networks. Our results show that convolutional neural network is an approximation of the finite term Volterra convolution, whose order increases exponentially with the number of layers and kernel size increases exponentially with the strides. With this perspective, the specialized perturbations are directly obtained from the approximated kernels rather than iterative generated adversarial examples. Extensive experiments on synthetic and real-world data sets show the correctness and effectiveness of our results.
Fast Hypergraph Regularized Nonnegative Tensor Ring Factorization Based on Low-Rank Approximation
Sep 06, 2021
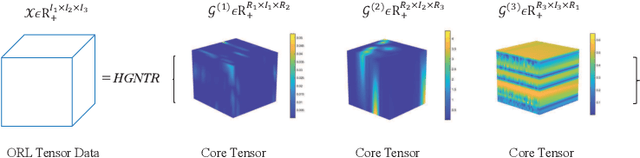
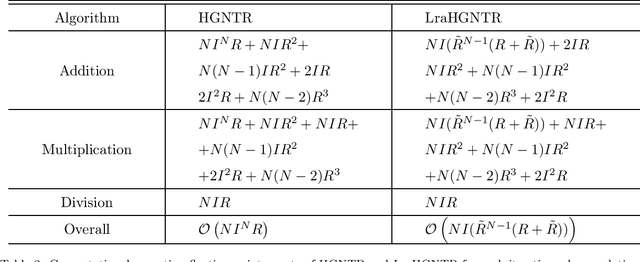
For the high dimensional data representation, nonnegative tensor ring (NTR) decomposition equipped with manifold learning has become a promising model to exploit the multi-dimensional structure and extract the feature from tensor data. However, the existing methods such as graph regularized tensor ring decomposition (GNTR) only models the pair-wise similarities of objects. For tensor data with complex manifold structure, the graph can not exactly construct similarity relationships. In this paper, in order to effectively utilize the higher-dimensional and complicated similarities among objects, we introduce hypergraph to the framework of NTR to further enhance the feature extraction, upon which a hypergraph regularized nonnegative tensor ring decomposition (HGNTR) method is developed. To reduce the computational complexity and suppress the noise, we apply the low-rank approximation trick to accelerate HGNTR (called LraHGNTR). Our experimental results show that compared with other state-of-the-art algorithms, the proposed HGNTR and LraHGNTR can achieve higher performance in clustering tasks, in addition, LraHGNTR can greatly reduce running time without decreasing accuracy.
On the Memory Mechanism of Tensor-Power Recurrent Models
Mar 02, 2021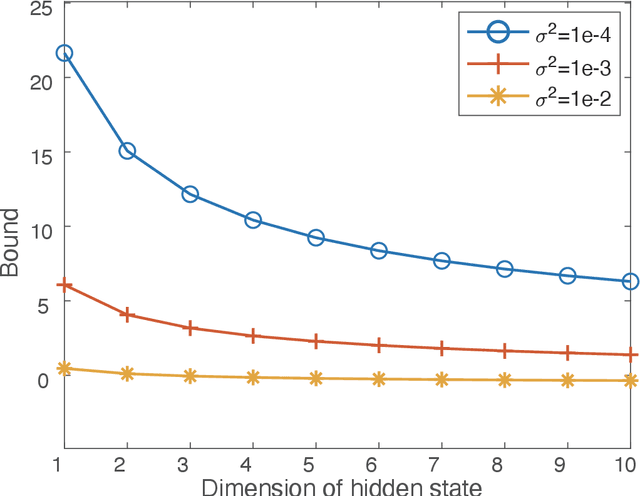
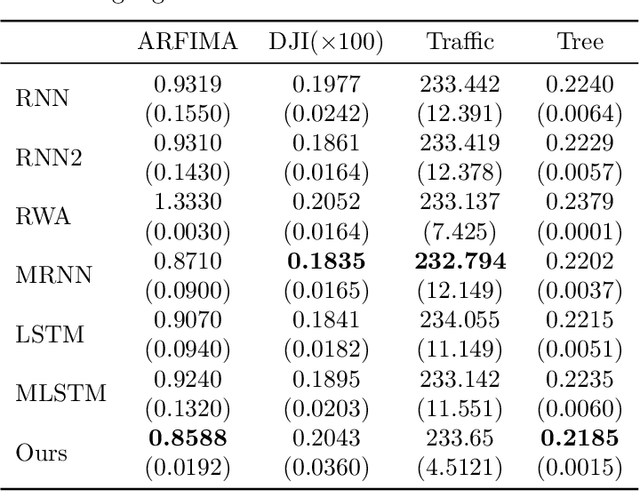
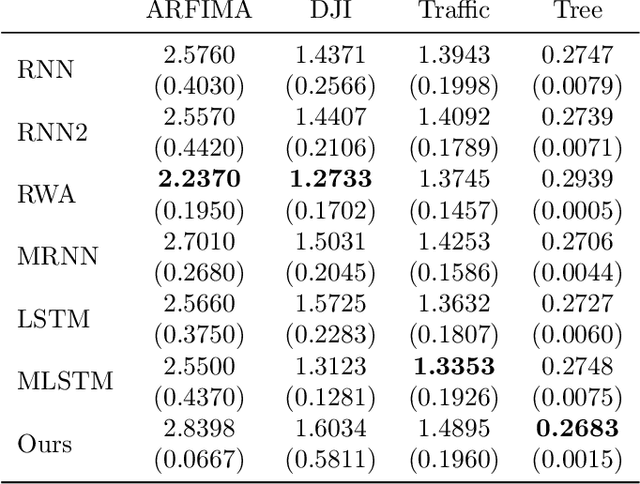
Tensor-power (TP) recurrent model is a family of non-linear dynamical systems, of which the recurrence relation consists of a p-fold (a.k.a., degree-p) tensor product. Despite such the model frequently appears in the advanced recurrent neural networks (RNNs), to this date there is limited study on its memory property, a critical characteristic in sequence tasks. In this work, we conduct a thorough investigation of the memory mechanism of TP recurrent models. Theoretically, we prove that a large degree p is an essential condition to achieve the long memory effect, yet it would lead to unstable dynamical behaviors. Empirically, we tackle this issue by extending the degree p from discrete to a differentiable domain, such that it is efficiently learnable from a variety of datasets. Taken together, the new model is expected to benefit from the long memory effect in a stable manner. We experimentally show that the proposed model achieves competitive performance compared to various advanced RNNs in both the single-cell and seq2seq architectures.