 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Explainability as a Training-Time Reliability Signal for Efficient ECG Classification
Jun 10, 2026Training deep neural networks for clinical time-series analysis is computationally demanding, yet many healthcare settings lack the resources required for repeated model development and deployment. This challenge is particularly evident in electrocardiogram classification, where large datasets and long training schedules make efficiency practically important. Progressive Data Dropout reduces training cost by excluding samples from gradient updates once they are learned, but it relies on model confidence and may retain samples that are difficult due to noise or ambiguity rather than useful signal. In this work, we introduce ERTS, an explainability-based reliability training signal for efficient ECG classification. ERTS uses explanation quality during training to distinguish between informative and unreliable uncertainty. Building on progressive data selection, we compute Grad-CAM attention maps for candidate samples and derive a focus score that measures whether model predictions are supported by coherent and localised patterns. Samples with low focus are filtered out, while those with meaningful attention are prioritised for gradient updates. We evaluate ERTS across three ECG datasets and multiple backbone architectures, showing consistent improvements in macro-F1 alongside reduced effective training cost. These results suggest that explanation quality can serve as a practical signal for improving both efficiency and reliability in clinical time-series learning. Code will be released.
Distribution-Based Masked Medical Vision-Language Model Using Structured Reports
Jul 29, 2025Medical image-language pre-training aims to align medical images with clinically relevant text to improve model performance on various downstream tasks. However, existing models often struggle with the variability and ambiguity inherent in medical data, limiting their ability to capture nuanced clinical information and uncertainty. This work introduces an uncertainty-aware medical image-text pre-training model that enhances generalization capabilities in medical image analysis. Building on previous methods and focusing on Chest X-Rays, our approach utilizes structured text reports generated by a large language model (LLM) to augment image data with clinically relevant context. These reports begin with a definition of the disease, followed by the `appearance' section to highlight critical regions of interest, and finally `observations' and `verdicts' that ground model predictions in clinical semantics. By modeling both inter- and intra-modal uncertainty, our framework captures the inherent ambiguity in medical images and text, yielding improved representations and performance on downstream tasks. Our model demonstrates significant advances in medical image-text pre-training, obtaining state-of-the-art performance on multiple downstream tasks.
On the Memory Mechanism of Tensor-Power Recurrent Models
Mar 02, 2021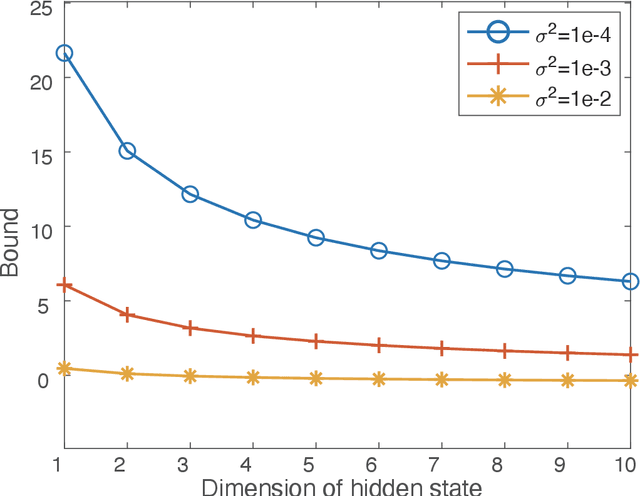
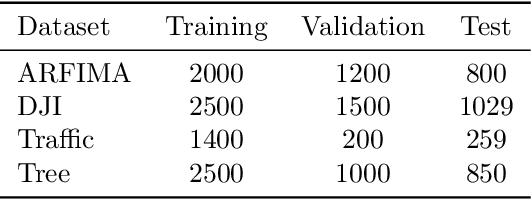
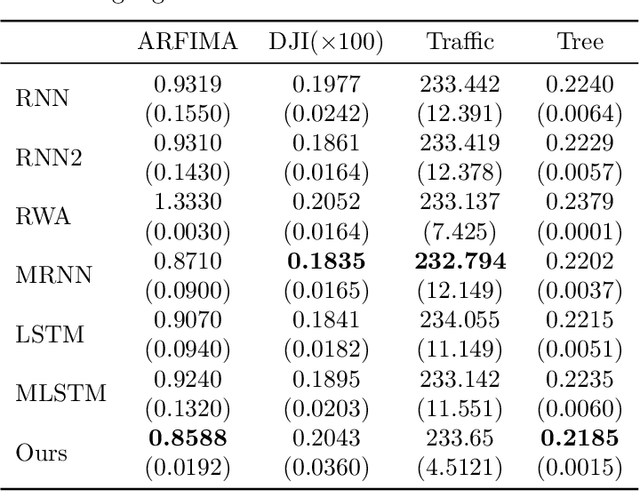
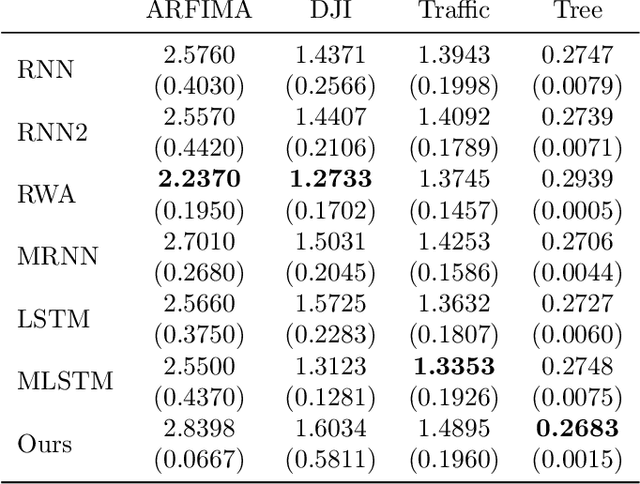
Tensor-power (TP) recurrent model is a family of non-linear dynamical systems, of which the recurrence relation consists of a p-fold (a.k.a., degree-p) tensor product. Despite such the model frequently appears in the advanced recurrent neural networks (RNNs), to this date there is limited study on its memory property, a critical characteristic in sequence tasks. In this work, we conduct a thorough investigation of the memory mechanism of TP recurrent models. Theoretically, we prove that a large degree p is an essential condition to achieve the long memory effect, yet it would lead to unstable dynamical behaviors. Empirically, we tackle this issue by extending the degree p from discrete to a differentiable domain, such that it is efficiently learnable from a variety of datasets. Taken together, the new model is expected to benefit from the long memory effect in a stable manner. We experimentally show that the proposed model achieves competitive performance compared to various advanced RNNs in both the single-cell and seq2seq architectures.