 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory II: Landscape of the Empirical Risk in Deep Learning
Jun 22, 2017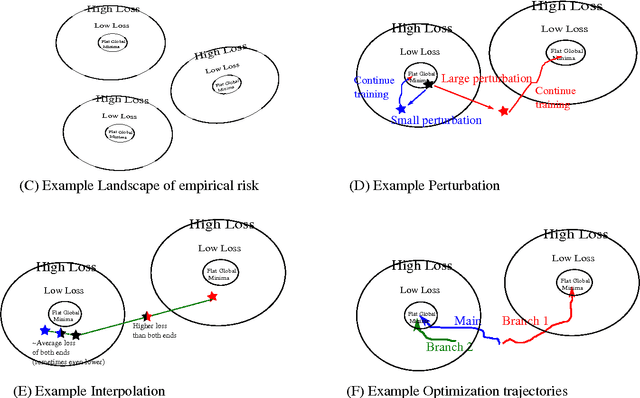
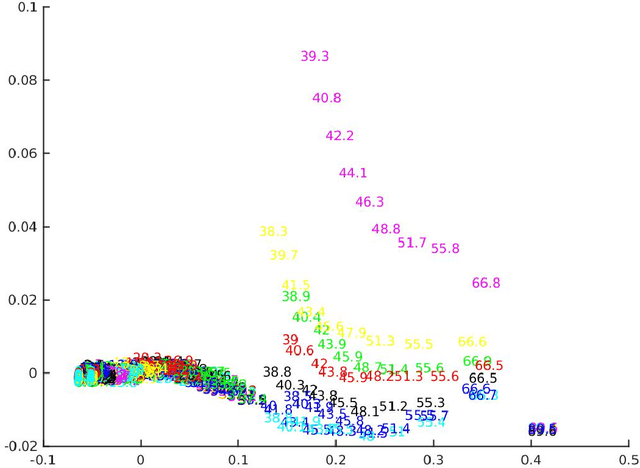
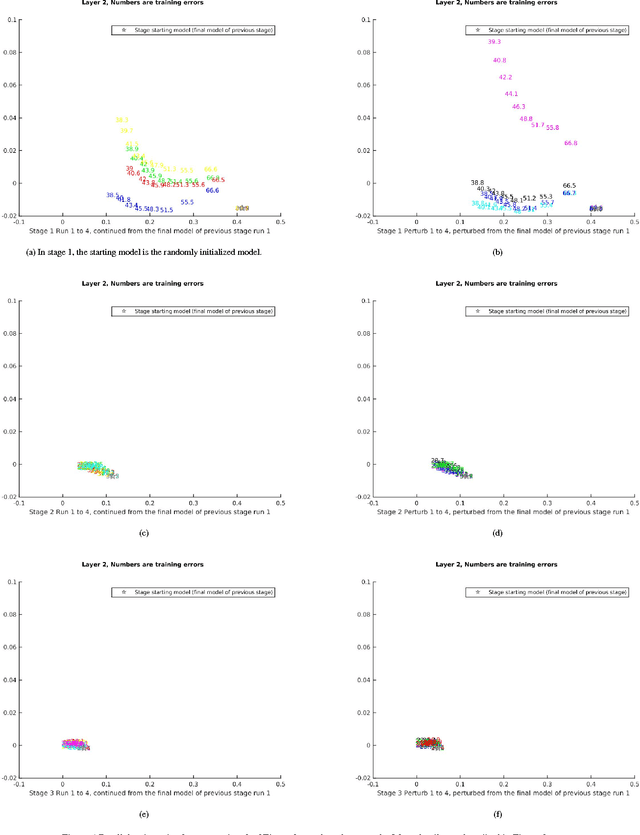
Previous theoretical work on deep learning and neural network optimization tend to focus on avoiding saddle points and local minima. However, the practical observation is that, at least in the case of the most successful Deep Convolutional Neural Networks (DCNNs), practitioners can always increase the network size to fit the training data (an extreme example would be [1]). The most successful DCNNs such as VGG and ResNets are best used with a degree of "overparametrization". In this work, we characterize with a mix of theory and experiments, the landscape of the empirical risk of overparametrized DCNNs. We first prove in the regression framework the existence of a large number of degenerate global minimizers with zero empirical error (modulo inconsistent equations). The argument that relies on the use of Bezout theorem is rigorous when the RELUs are replaced by a polynomial nonlinearity (which empirically works as well). As described in our Theory III [2] paper, the same minimizers are degenerate and thus very likely to be found by SGD that will furthermore select with higher probability the most robust zero-minimizer. We further experimentally explored and visualized the landscape of empirical risk of a DCNN on CIFAR-10 during the entire training process and especially the global minima. Finally, based on our theoretical and experimental results, we propose an intuitive model of the landscape of DCNN's empirical loss surface, which might not be as complicated as people commonly believe.
Why and When Can Deep -- but Not Shallow -- Networks Avoid the Curse of Dimensionality: a Review
Feb 04, 2017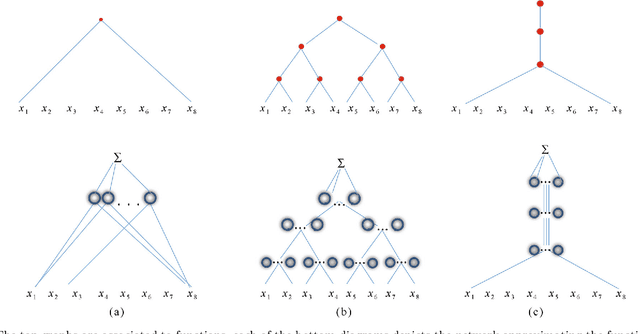
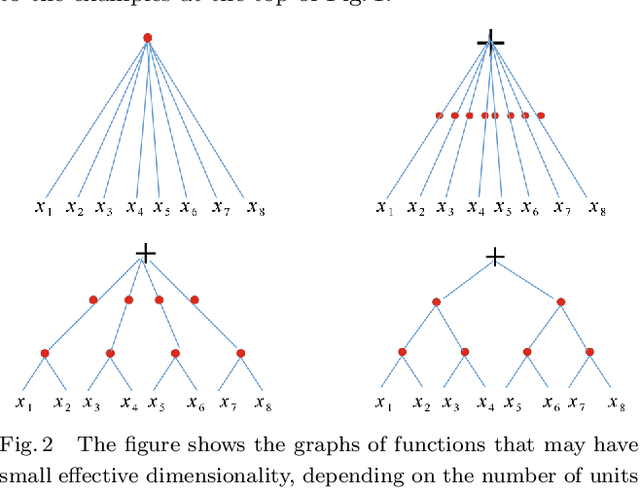
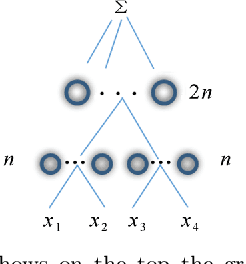
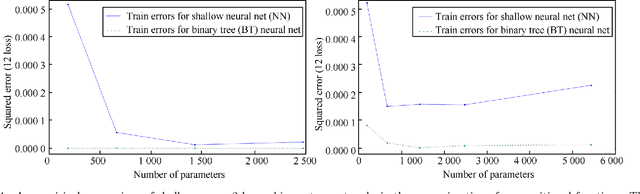
The paper characterizes classes of functions for which deep learning can be exponentially better than shallow learning. Deep convolutional networks are a special case of these conditions, though weight sharing is not the main reason for their exponential advantage.
Compression of Deep Neural Networks for Image Instance Retrieval
Jan 18, 2017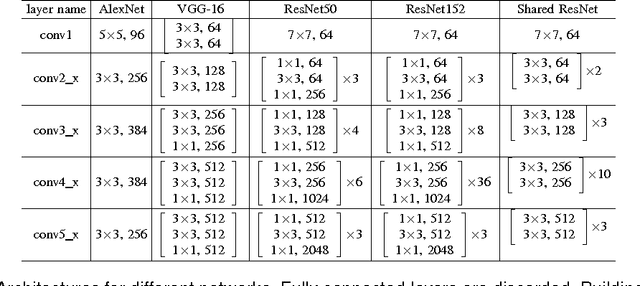
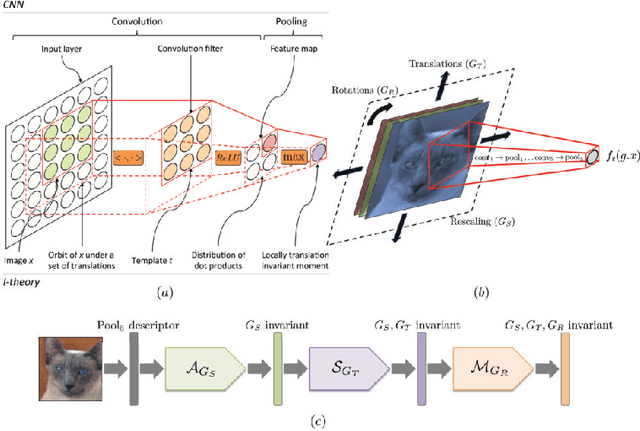
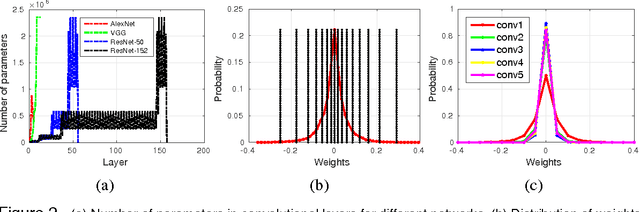

Image instance retrieval is the problem of retrieving images from a database which contain the same object. Convolutional Neural Network (CNN) based descriptors are becoming the dominant approach for generating {\it global image descriptors} for the instance retrieval problem. One major drawback of CNN-based {\it global descriptors} is that uncompressed deep neural network models require hundreds of megabytes of storage making them inconvenient to deploy in mobile applications or in custom hardware. In this work, we study the problem of neural network model compression focusing on the image instance retrieval task. We study quantization, coding, pruning and weight sharing techniques for reducing model size for the instance retrieval problem. We provide extensive experimental results on the trade-off between retrieval performance and model size for different types of networks on several data sets providing the most comprehensive study on this topic. We compress models to the order of a few MBs: two orders of magnitude smaller than the uncompressed models while achieving negligible loss in retrieval performance.
Streaming Normalization: Towards Simpler and More Biologically-plausible Normalizations for Online and Recurrent Learning
Oct 19, 2016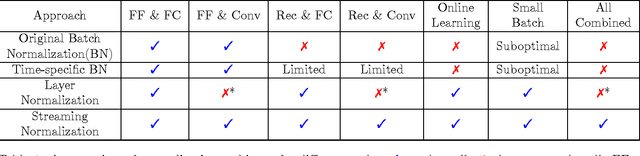
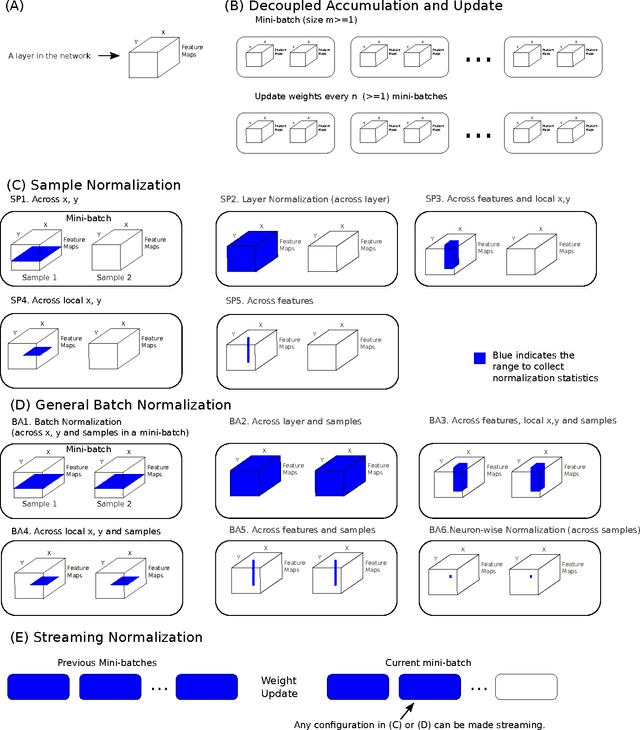
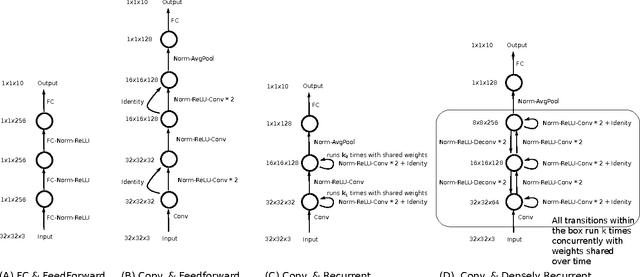
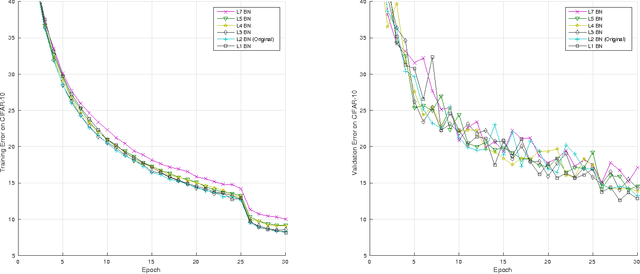
We systematically explored a spectrum of normalization algorithms related to Batch Normalization (BN) and propose a generalized formulation that simultaneously solves two major limitations of BN: (1) online learning and (2) recurrent learning. Our proposal is simpler and more biologically-plausible. Unlike previous approaches, our technique can be applied out of the box to all learning scenarios (e.g., online learning, batch learning, fully-connected, convolutional, feedforward, recurrent and mixed --- recurrent and convolutional) and compare favorably with existing approaches. We also propose Lp Normalization for normalizing by different orders of statistical moments. In particular, L1 normalization is well-performing, simple to implement, fast to compute, more biologically-plausible and thus ideal for GPU or hardware implementations.
View-tolerant face recognition and Hebbian learning imply mirror-symmetric neural tuning to head orientation
Jun 05, 2016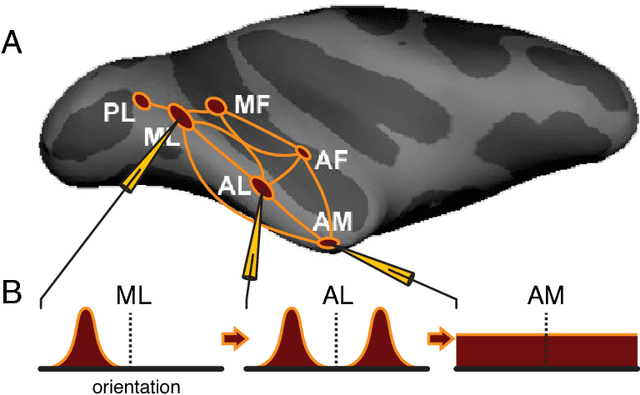
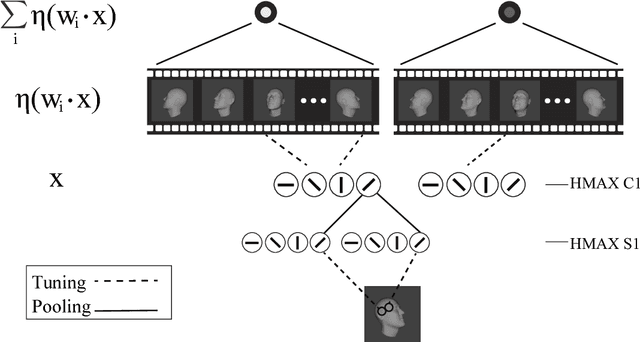
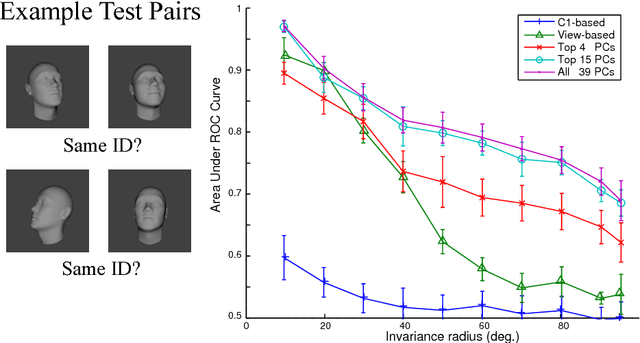
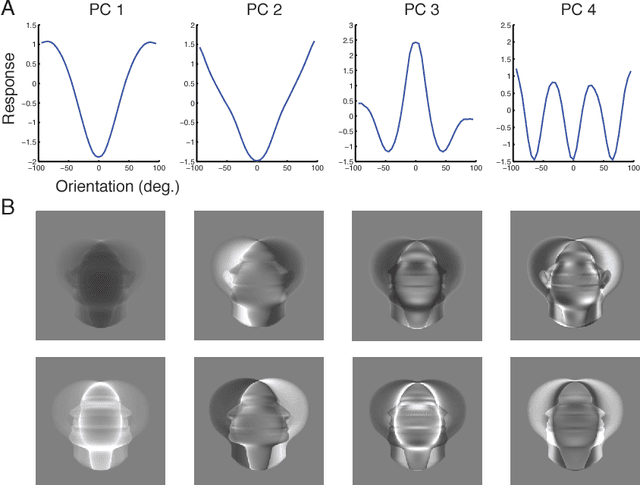
The primate brain contains a hierarchy of visual areas, dubbed the ventral stream, which rapidly computes object representations that are both specific for object identity and relatively robust against identity-preserving transformations like depth-rotations. Current computational models of object recognition, including recent deep learning networks, generate these properties through a hierarchy of alternating selectivity-increasing filtering and tolerance-increasing pooling operations, similar to simple-complex cells operations. While simulations of these models recapitulate the ventral stream's progression from early view-specific to late view-tolerant representations, they fail to generate the most salient property of the intermediate representation for faces found in the brain: mirror-symmetric tuning of the neural population to head orientation. Here we prove that a class of hierarchical architectures and a broad set of biologically plausible learning rules can provide approximate invariance at the top level of the network. While most of the learning rules do not yield mirror-symmetry in the mid-level representations, we characterize a specific biologically-plausible Hebb-type learning rule that is guaranteed to generate mirror-symmetric tuning to faces tuning at intermediate levels of the architecture.
Learning Functions: When Is Deep Better Than Shallow
May 29, 2016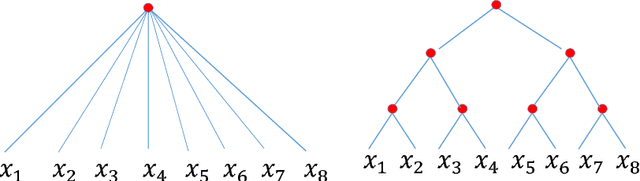

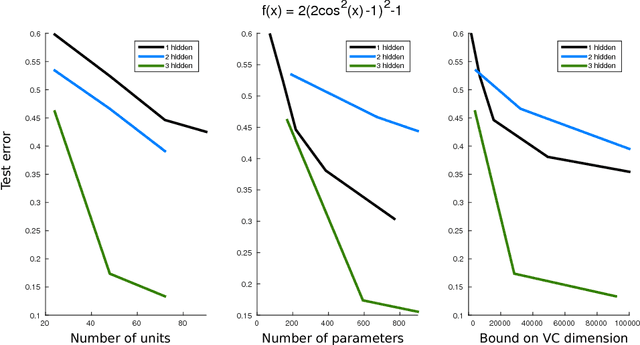
While the universal approximation property holds both for hierarchical and shallow networks, we prove that deep (hierarchical) networks can approximate the class of compositional functions with the same accuracy as shallow networks but with exponentially lower number of training parameters as well as VC-dimension. This theorem settles an old conjecture by Bengio on the role of depth in networks. We then define a general class of scalable, shift-invariant algorithms to show a simple and natural set of requirements that justify deep convolutional networks.
Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex
Apr 13, 2016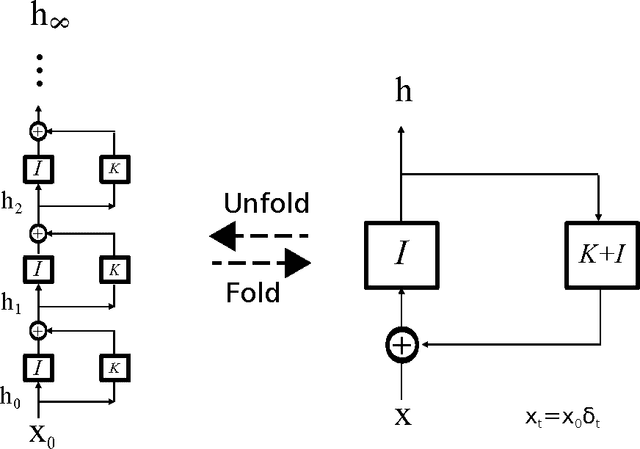
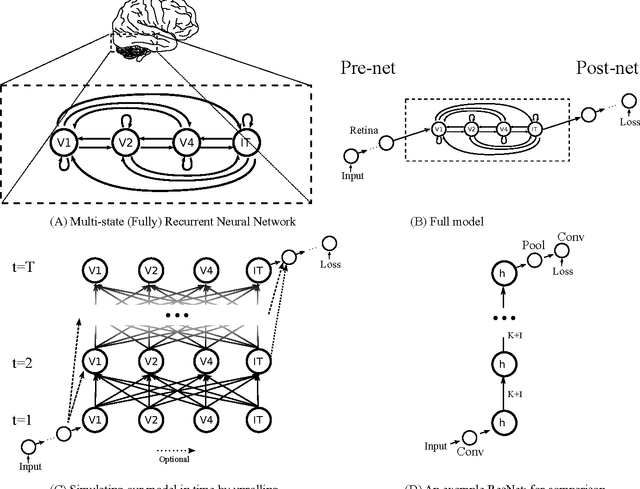
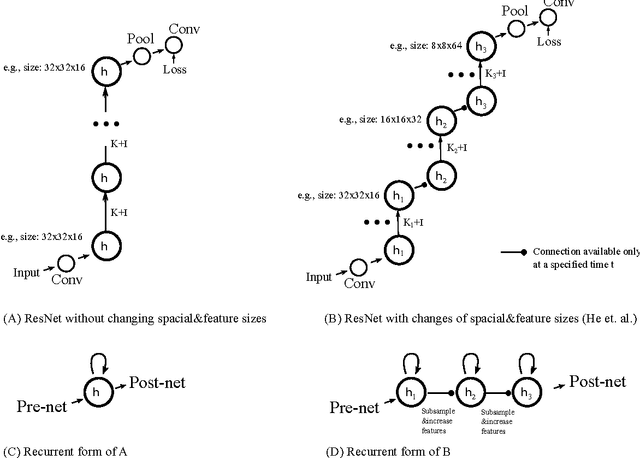
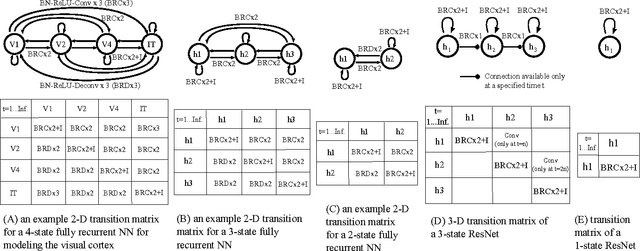
We discuss relations between Residual Networks (ResNet), Recurrent Neural Networks (RNNs) and the primate visual cortex. We begin with the observation that a shallow RNN is exactly equivalent to a very deep ResNet with weight sharing among the layers. A direct implementation of such a RNN, although having orders of magnitude fewer parameters, leads to a performance similar to the corresponding ResNet. We propose 1) a generalization of both RNN and ResNet architectures and 2) the conjecture that a class of moderately deep RNNs is a biologically-plausible model of the ventral stream in visual cortex. We demonstrate the effectiveness of the architectures by testing them on the CIFAR-10 dataset.
How Important is Weight Symmetry in Backpropagation?
Feb 04, 2016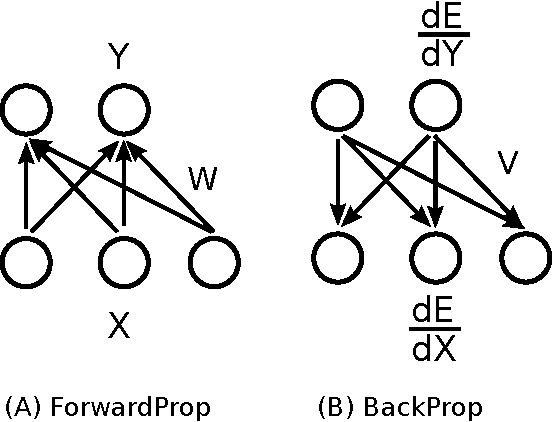
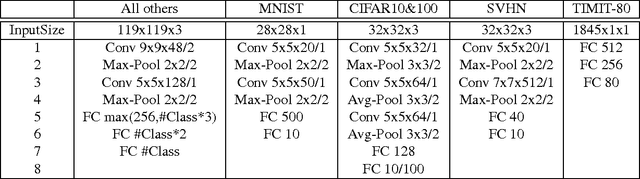
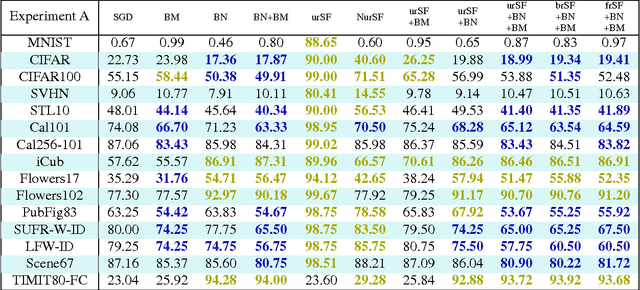
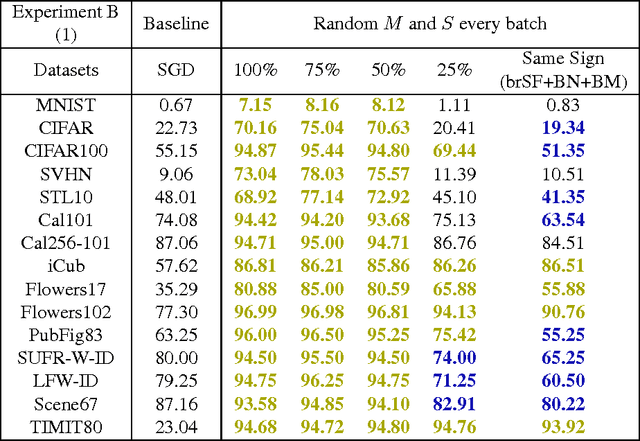
Gradient backpropagation (BP) requires symmetric feedforward and feedback connections -- the same weights must be used for forward and backward passes. This "weight transport problem" (Grossberg 1987) is thought to be one of the main reasons to doubt BP's biologically plausibility. Using 15 different classification datasets, we systematically investigate to what extent BP really depends on weight symmetry. In a study that turned out to be surprisingly similar in spirit to Lillicrap et al.'s demonstration (Lillicrap et al. 2014) but orthogonal in its results, our experiments indicate that: (1) the magnitudes of feedback weights do not matter to performance (2) the signs of feedback weights do matter -- the more concordant signs between feedforward and their corresponding feedback connections, the better (3) with feedback weights having random magnitudes and 100% concordant signs, we were able to achieve the same or even better performance than SGD. (4) some normalizations/stabilizations are indispensable for such asymmetric BP to work, namely Batch Normalization (BN) (Ioffe and Szegedy 2015) and/or a "Batch Manhattan" (BM) update rule.
Unsupervised learning of clutter-resistant visual representations from natural videos
Apr 24, 2015

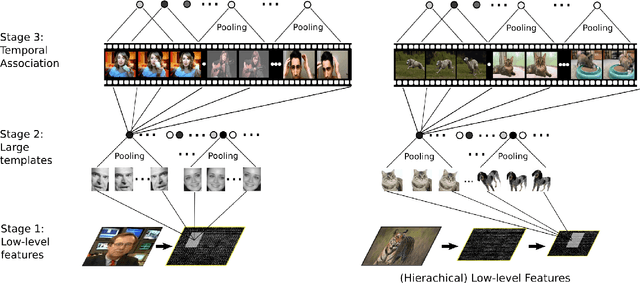

Populations of neurons in inferotemporal cortex (IT) maintain an explicit code for object identity that also tolerates transformations of object appearance e.g., position, scale, viewing angle [1, 2, 3]. Though the learning rules are not known, recent results [4, 5, 6] suggest the operation of an unsupervised temporal-association-based method e.g., Foldiak's trace rule [7]. Such methods exploit the temporal continuity of the visual world by assuming that visual experience over short timescales will tend to have invariant identity content. Thus, by associating representations of frames from nearby times, a representation that tolerates whatever transformations occurred in the video may be achieved. Many previous studies verified that such rules can work in simple situations without background clutter, but the presence of visual clutter has remained problematic for this approach. Here we show that temporal association based on large class-specific filters (templates) avoids the problem of clutter. Our system learns in an unsupervised way from natural videos gathered from the internet, and is able to perform a difficult unconstrained face recognition task on natural images: Labeled Faces in the Wild [8].
Can a biologically-plausible hierarchy effectively replace face detection, alignment, and recognition pipelines?
Mar 26, 2014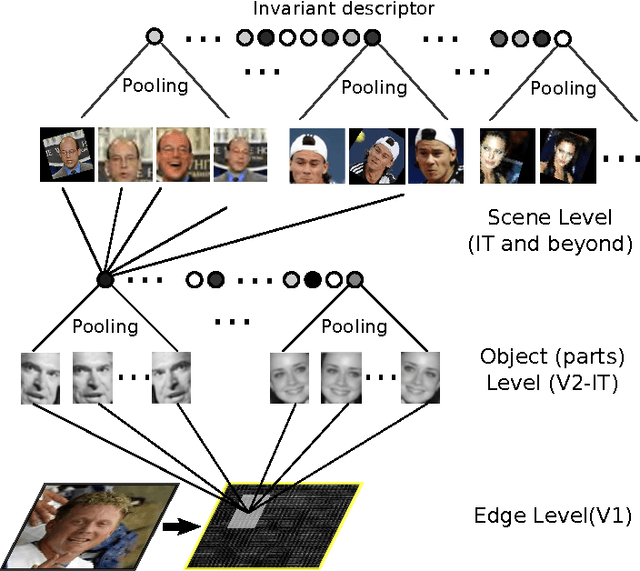
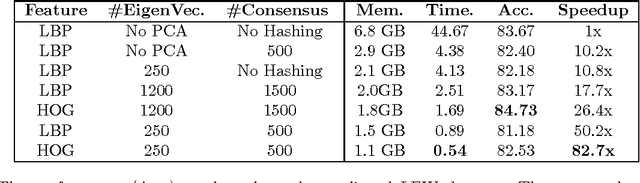
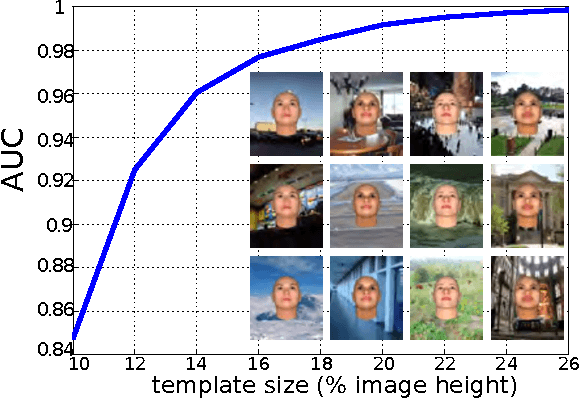
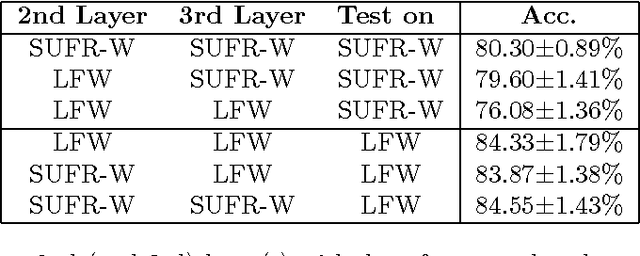
The standard approach to unconstrained face recognition in natural photographs is via a detection, alignment, recognition pipeline. While that approach has achieved impressive results, there are several reasons to be dissatisfied with it, among them is its lack of biological plausibility. A recent theory of invariant recognition by feedforward hierarchical networks, like HMAX, other convolutional networks, or possibly the ventral stream, implies an alternative approach to unconstrained face recognition. This approach accomplishes detection and alignment implicitly by storing transformations of training images (called templates) rather than explicitly detecting and aligning faces at test time. Here we propose a particular locality-sensitive hashing based voting scheme which we call "consensus of collisions" and show that it can be used to approximate the full 3-layer hierarchy implied by the theory. The resulting end-to-end system for unconstrained face recognition operates on photographs of faces taken under natural conditions, e.g., Labeled Faces in the Wild (LFW), without aligning or cropping them, as is normally done. It achieves a drastic improvement in the state of the art on this end-to-end task, reaching the same level of performance as the best systems operating on aligned, closely cropped images (no outside training data). It also performs well on two newer datasets, similar to LFW, but more difficult: LFW-jittered (new here) and SUFR-W.