 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery
Jul 16, 2025In this paper, we address the problem of novel class discovery (NCD), which aims to cluster novel classes by leveraging knowledge from disjoint known classes. While recent advances have made significant progress in this area, existing NCD methods face two major limitations. First, they primarily focus on single-view data (e.g., images), overlooking the increasingly common multi-view data, such as multi-omics datasets used in disease diagnosis. Second, their reliance on pseudo-labels to supervise novel class clustering often results in unstable performance, as pseudo-label quality is highly sensitive to factors such as data noise and feature dimensionality. To address these challenges, we propose a novel framework named Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery (IICMVNCD), which is the first attempt to explore NCD in multi-view setting so far. Specifically, at the intra-view level, leveraging the distributional similarity between known and novel classes, we employ matrix factorization to decompose features into view-specific shared base matrices and factor matrices. The base matrices capture distributional consistency among the two datasets, while the factor matrices model pairwise relationships between samples. At the inter-view level, we utilize view relationships among known classes to guide the clustering of novel classes. This includes generating predicted labels through the weighted fusion of factor matrices and dynamically adjusting view weights of known classes based on the supervision loss, which are then transferred to novel class learning. Experimental results validate the effectiveness of our proposed approach.
Draft, Command, and Edit: Controllable Text Editing in E-Commerce
Aug 11, 2022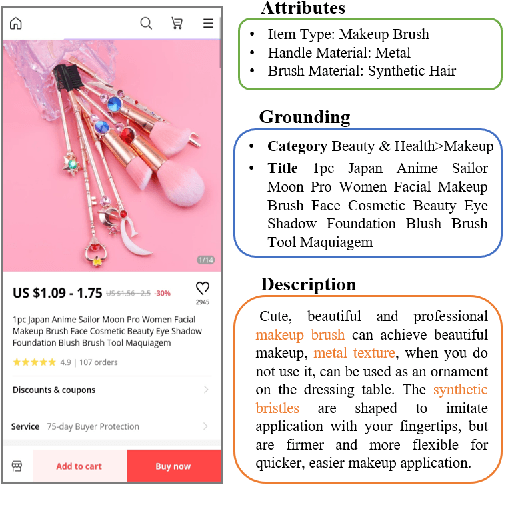
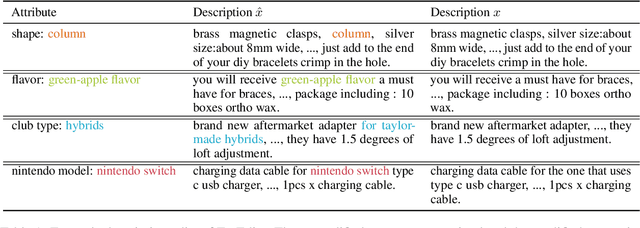
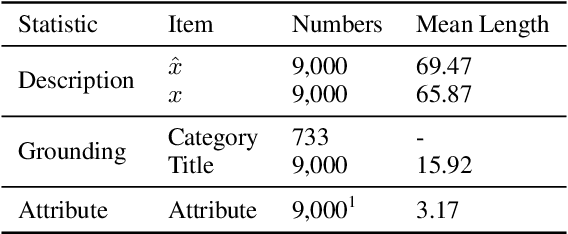
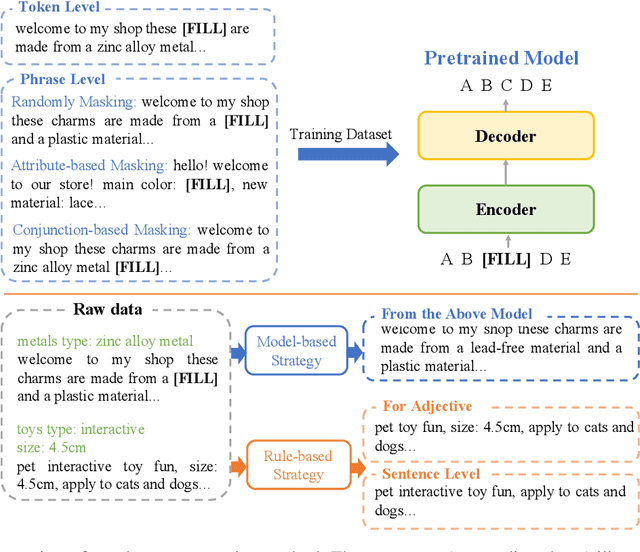
Product description generation is a challenging and under-explored task. Most such work takes a set of product attributes as inputs then generates a description from scratch in a single pass. However, this widespread paradigm might be limited when facing the dynamic wishes of users on constraining the description, such as deleting or adding the content of a user-specified attribute based on the previous version. To address this challenge, we explore a new draft-command-edit manner in description generation, leading to the proposed new task-controllable text editing in E-commerce. More specifically, we allow systems to receive a command (deleting or adding) from the user and then generate a description by flexibly modifying the content based on the previous version. It is easier and more practical to meet the new needs by modifying previous versions than generating from scratch. Furthermore, we design a data augmentation method to remedy the low resource challenge in this task, which contains a model-based and a rule-based strategy to imitate the edit by humans. To accompany this new task, we present a human-written draft-command-edit dataset called E-cEdits and a new metric "Attribute Edit". Our experimental results show that using the new data augmentation method outperforms baselines to a greater extent in both automatic and human evaluations.
BFGAN: Backward and Forward Generative Adversarial Networks for Lexically Constrained Sentence Generation
Sep 07, 2018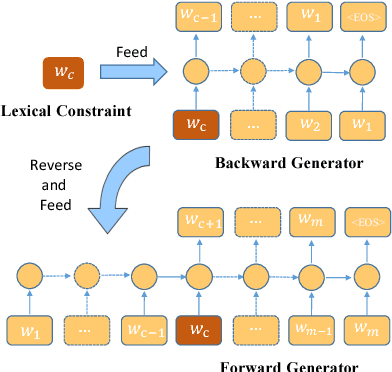

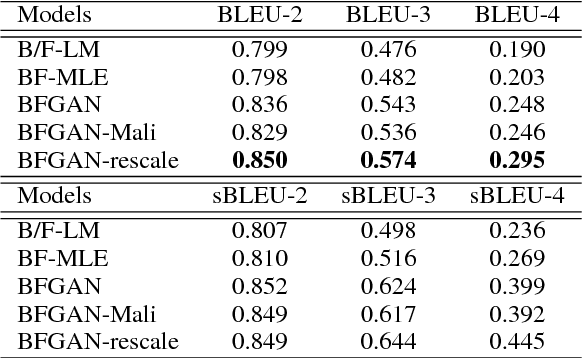
Incorporating prior knowledge like lexical constraints into the model's output to generate meaningful and coherent sentences has many applications in dialogue system, machine translation, image captioning, etc. However, existing RNN-based models incrementally generate sentences from left to right via beam search, which makes it difficult to directly introduce lexical constraints into the generated sentences. In this paper, we propose a new algorithmic framework, dubbed BFGAN, to address this challenge. Specifically, we employ a backward generator and a forward generator to generate lexically constrained sentences together, and use a discriminator to guide the joint training of two generators by assigning them reward signals. Due to the difficulty of BFGAN training, we propose several training techniques to make the training process more stable and efficient. Our extensive experiments on two large-scale datasets with human evaluation demonstrate that BFGAN has significant improvements over previous methods.
Ancient-Modern Chinese Translation with a Large Training Dataset
Aug 11, 2018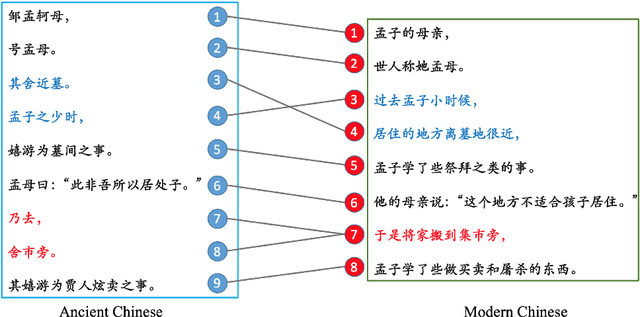
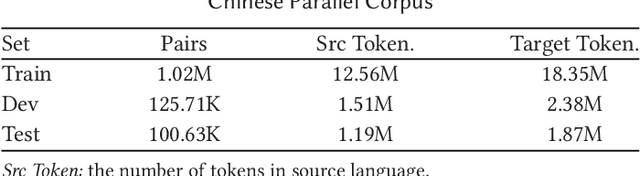
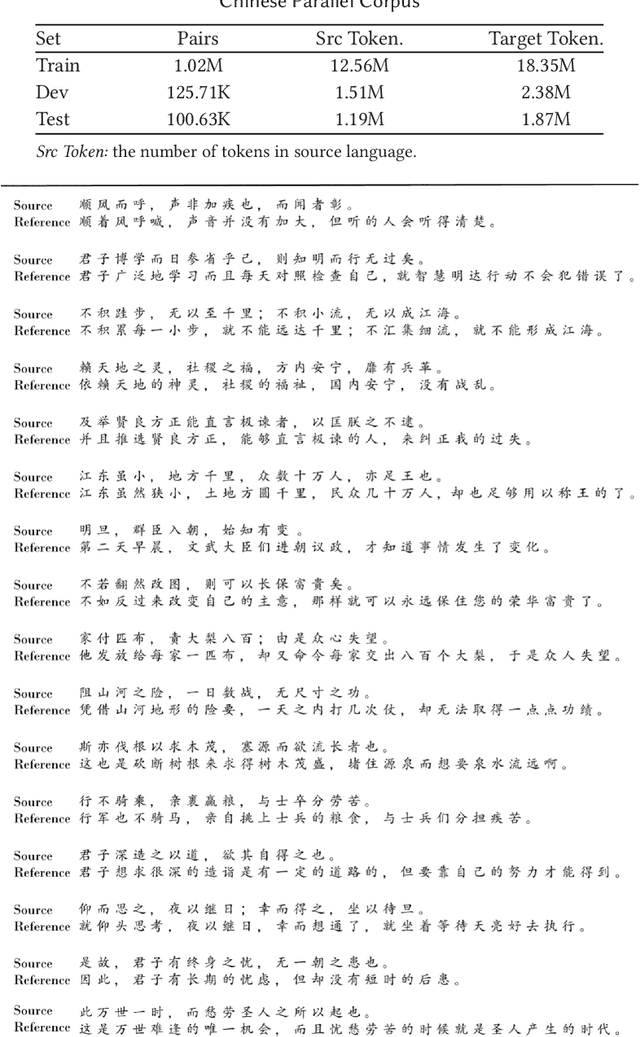

Ancient Chinese brings the wisdom and spirit culture of the Chinese nation. Automatically translation from ancient Chinese to modern Chinese helps to inherit and carry forward the quintessence of the ancients. In this paper, we propose an Ancient-Modern Chinese clause alignment approach and apply it to create a large scale Ancient-Modern Chinese parallel corpus which contains about 1.24M bilingual pairs. To our best knowledge, this is the first large high-quality Ancient-Modern Chinese dataset. Furthermore, we train the SMT and various NMT based models on this dataset and provide a strong baseline for this task