 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFT: Rationale adaptor for few-shot abusive language detection
Nov 30, 2022



Abusive language is a concerning problem in online social media. Past research on detecting abusive language covers different platforms, languages, demographies, etc. However, models trained using these datasets do not perform well in cross-domain evaluation settings. To overcome this, a common strategy is to use a few samples from the target domain to train models to get better performance in that domain (cross-domain few-shot training). However, this might cause the models to overfit the artefacts of those samples. A compelling solution could be to guide the models toward rationales, i.e., spans of text that justify the text's label. This method has been found to improve model performance in the in-domain setting across various NLP tasks. In this paper, we propose RAFT (Rationale Adaptor for Few-shoT classification) for abusive language detection. We first build a multitask learning setup to jointly learn rationales, targets, and labels, and find a significant improvement of 6% macro F1 on the rationale detection task over training solely rationale classifiers. We introduce two rationale-integrated BERT-based architectures (the RAFT models) and evaluate our systems over five different abusive language datasets, finding that in the few-shot classification setting, RAFT-based models outperform baseline models by about 7% in macro F1 scores and perform competitively to models finetuned on other source domains. Furthermore, RAFT-based models outperform LIME/SHAP-based approaches in terms of plausibility and are close in performance in terms of faithfulness.
Hate Speech and Offensive Language Detection in Bengali
Oct 07, 2022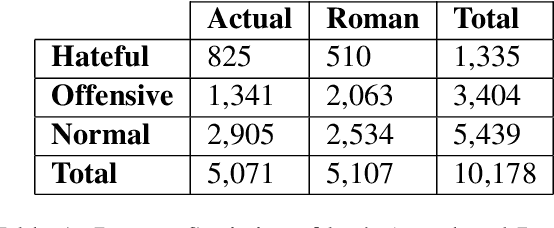
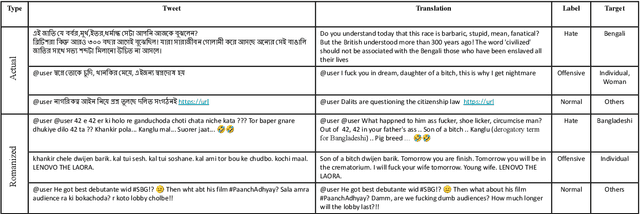
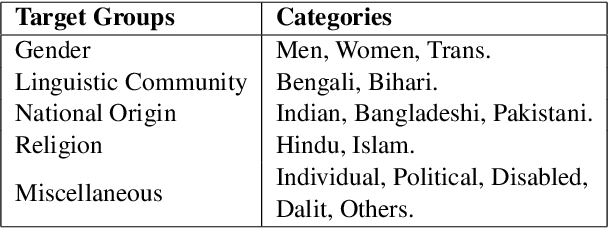

Social media often serves as a breeding ground for various hateful and offensive content. Identifying such content on social media is crucial due to its impact on the race, gender, or religion in an unprejudiced society. However, while there is extensive research in hate speech detection in English, there is a gap in hateful content detection in low-resource languages like Bengali. Besides, a current trend on social media is the use of Romanized Bengali for regular interactions. To overcome the existing research's limitations, in this study, we develop an annotated dataset of 10K Bengali posts consisting of 5K actual and 5K Romanized Bengali tweets. We implement several baseline models for the classification of such hateful posts. We further explore the interlingual transfer mechanism to boost classification performance. Finally, we perform an in-depth error analysis by looking into the misclassified posts by the models. While training actual and Romanized datasets separately, we observe that XLM-Roberta performs the best. Further, we witness that on joint training and few-shot training, MuRIL outperforms other models by interpreting the semantic expressions better. We make our code and dataset public for others.
Which one is more toxic? Findings from Jigsaw Rate Severity of Toxic Comments
Jun 27, 2022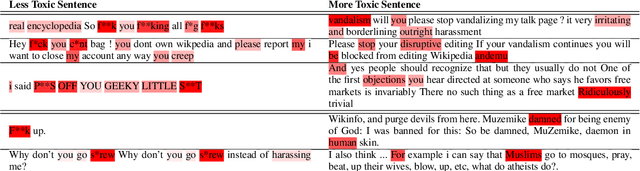
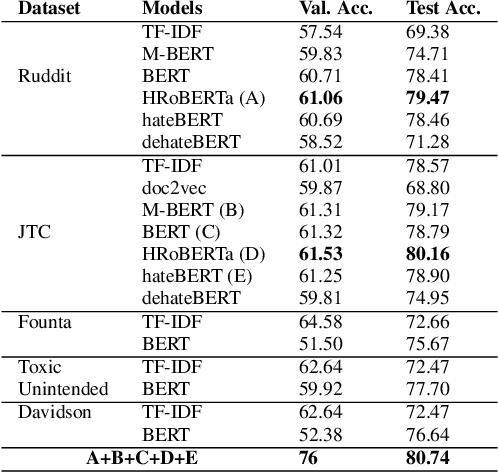
The proliferation of online hate speech has necessitated the creation of algorithms which can detect toxicity. Most of the past research focuses on this detection as a classification task, but assigning an absolute toxicity label is often tricky. Hence, few of the past works transform the same task into a regression. This paper shows the comparative evaluation of different transformers and traditional machine learning models on a recently released toxicity severity measurement dataset by Jigsaw. We further demonstrate the issues with the model predictions using explainability analysis.
CounterGeDi: A controllable approach to generate polite, detoxified and emotional counterspeech
May 09, 2022
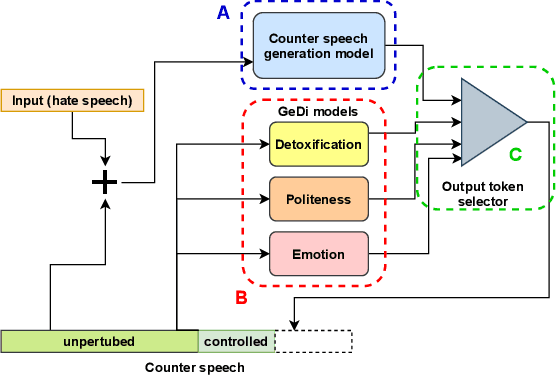


Recently, many studies have tried to create generation models to assist counter speakers by providing counterspeech suggestions for combating the explosive proliferation of online hate. However, since these suggestions are from a vanilla generation model, they might not include the appropriate properties required to counter a particular hate speech instance. In this paper, we propose CounterGeDi - an ensemble of generative discriminators (GeDi) to guide the generation of a DialoGPT model toward more polite, detoxified, and emotionally laden counterspeech. We generate counterspeech using three datasets and observe significant improvement across different attribute scores. The politeness and detoxification scores increased by around 15% and 6% respectively, while the emotion in the counterspeech increased by at least 10% across all the datasets. We also experiment with triple-attribute control and observe significant improvement over single attribute results when combining complementing attributes, e.g., politeness, joyfulness and detoxification. In all these experiments, the relevancy of the generated text does not deteriorate due to the application of these controls
HateCheckHIn: Evaluating Hindi Hate Speech Detection Models
Apr 30, 2022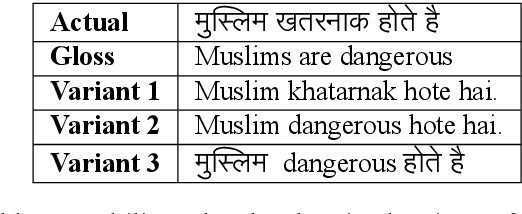
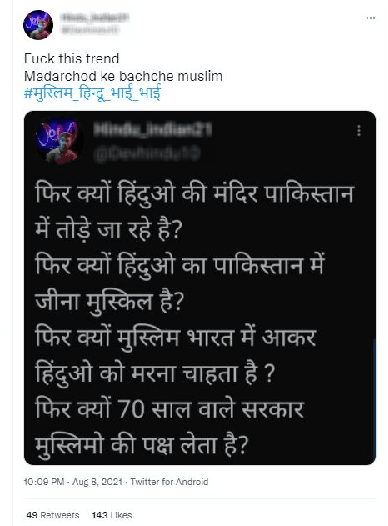

Due to the sheer volume of online hate, the AI and NLP communities have started building models to detect such hateful content. Recently, multilingual hate is a major emerging challenge for automated detection where code-mixing or more than one language have been used for conversation in social media. Typically, hate speech detection models are evaluated by measuring their performance on the held-out test data using metrics such as accuracy and F1-score. While these metrics are useful, it becomes difficult to identify using them where the model is failing, and how to resolve it. To enable more targeted diagnostic insights of such multilingual hate speech models, we introduce a set of functionalities for the purpose of evaluation. We have been inspired to design this kind of functionalities based on real-world conversation on social media. Considering Hindi as a base language, we craft test cases for each functionality. We name our evaluation dataset HateCheckHIn. To illustrate the utility of these functionalities , we test state-of-the-art transformer based m-BERT model and the Perspective API.
Abusive and Threatening Language Detection in Urdu using Boosting based and BERT based models: A Comparative Approach
Nov 27, 2021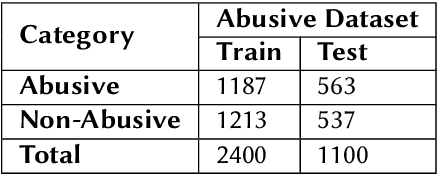
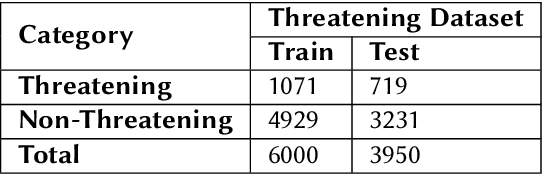
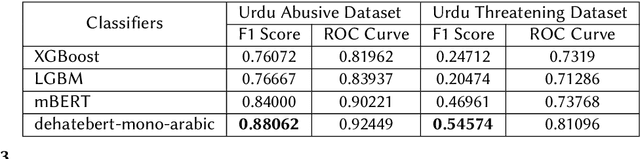
Online hatred is a growing concern on many social media platforms. To address this issue, different social media platforms have introduced moderation policies for such content. They also employ moderators who can check the posts violating moderation policies and take appropriate action. Academicians in the abusive language research domain also perform various studies to detect such content better. Although there is extensive research in abusive language detection in English, there is a lacuna in abusive language detection in low resource languages like Hindi, Urdu etc. In this FIRE 2021 shared task - "HASOC- Abusive and Threatening language detection in Urdu" the organizers propose an abusive language detection dataset in Urdu along with threatening language detection. In this paper, we explored several machine learning models such as XGboost, LGBM, m-BERT based models for abusive and threatening content detection in Urdu based on the shared task. We observed the Transformer model specifically trained on abusive language dataset in Arabic helps in getting the best performance. Our model came First for both abusive and threatening content detection with an F1scoreof 0.88 and 0.54, respectively.
Exploring Transformer Based Models to Identify Hate Speech and Offensive Content in English and Indo-Aryan Languages
Nov 27, 2021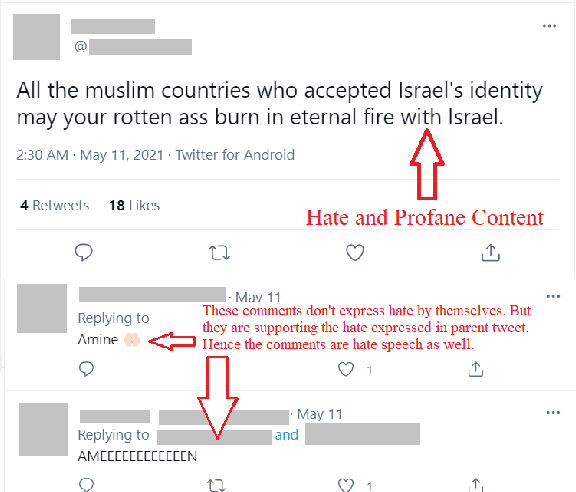
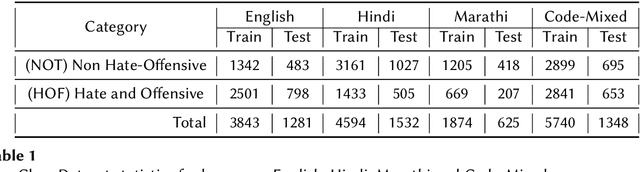
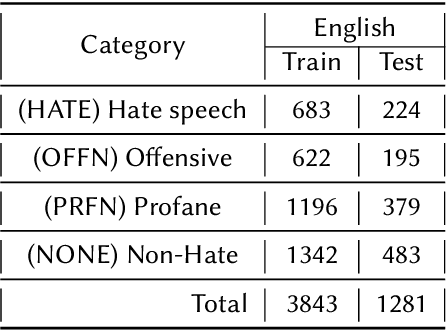
Hate speech is considered to be one of the major issues currently plaguing online social media. Repeated and repetitive exposure to hate speech has been shown to create physiological effects on the target users. Thus, hate speech, in all its forms, should be addressed on these platforms in order to maintain good health. In this paper, we explored several Transformer based machine learning models for the detection of hate speech and offensive content in English and Indo-Aryan languages at FIRE 2021. We explore several models such as mBERT, XLMR-large, XLMR-base by team name "Super Mario". Our models came 2nd position in Code-Mixed Data set (Macro F1: 0.7107), 2nd position in Hindi two-class classification(Macro F1: 0.7797), 4th in English four-class category (Macro F1: 0.8006) and 12th in English two-class category (Macro F1: 0.6447).
You too Brutus! Trapping Hateful Users in Social Media: Challenges, Solutions & Insights
Aug 01, 2021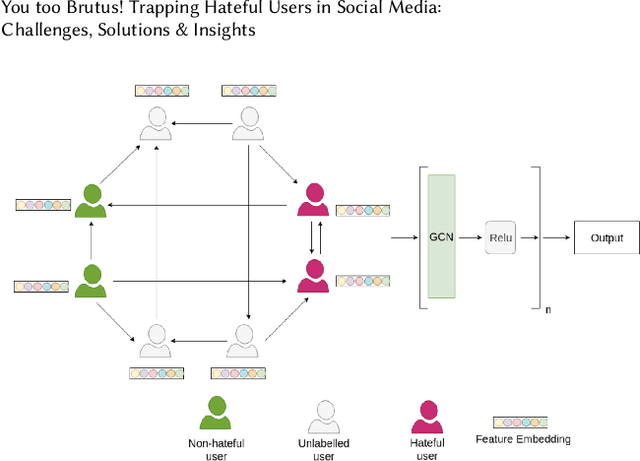
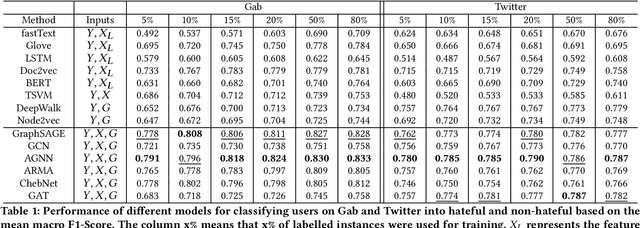
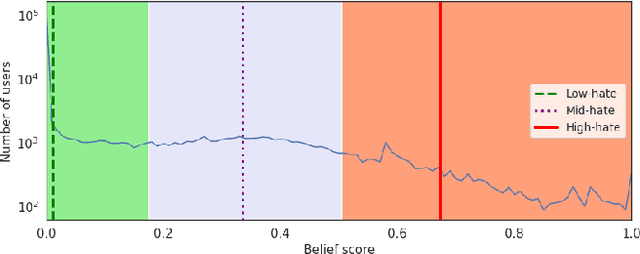
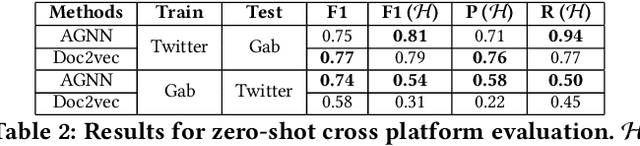
Hate speech is regarded as one of the crucial issues plaguing the online social media. The current literature on hate speech detection leverages primarily the textual content to find hateful posts and subsequently identify hateful users. However, this methodology disregards the social connections between users. In this paper, we run a detailed exploration of the problem space and investigate an array of models ranging from purely textual to graph based to finally semi-supervised techniques using Graph Neural Networks (GNN) that utilize both textual and graph-based features. We run exhaustive experiments on two datasets -- Gab, which is loosely moderated and Twitter, which is strictly moderated. Overall the AGNN model achieves 0.791 macro F1-score on the Gab dataset and 0.780 macro F1-score on the Twitter dataset using only 5% of the labeled instances, considerably outperforming all the other models including the fully supervised ones. We perform detailed error analysis on the best performing text and graph based models and observe that hateful users have unique network neighborhood signatures and the AGNN model benefits by paying attention to these signatures. This property, as we observe, also allows the model to generalize well across platforms in a zero-shot setting. Lastly, we utilize the best performing GNN model to analyze the evolution of hateful users and their targets over time in Gab.
Hate-Alert@DravidianLangTech-EACL2021: Ensembling strategies for Transformer-based Offensive language Detection
Feb 19, 2021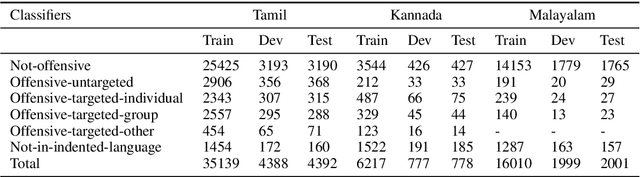
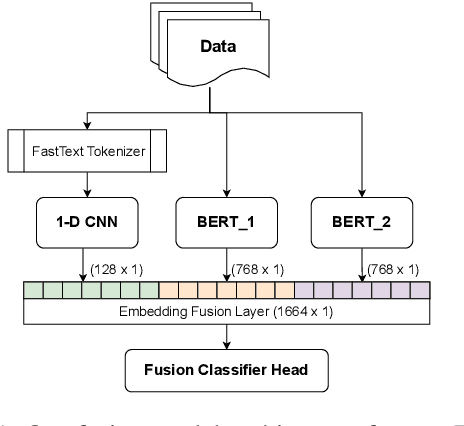
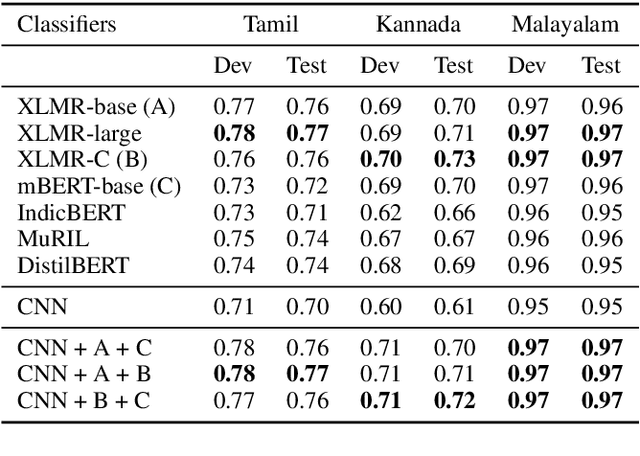
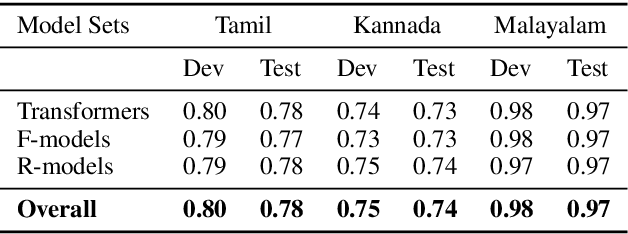
Social media often acts as breeding grounds for different forms of offensive content. For low resource languages like Tamil, the situation is more complex due to the poor performance of multilingual or language-specific models and lack of proper benchmark datasets. Based on this shared task, Offensive Language Identification in Dravidian Languages at EACL 2021, we present an exhaustive exploration of different transformer models, We also provide a genetic algorithm technique for ensembling different models. Our ensembled models trained separately for each language secured the first position in Tamil, the second position in Kannada, and the first position in Malayalam sub-tasks. The models and codes are provided.
"Short is the Road that Leads from Fear to Hate": Fear Speech in Indian WhatsApp Groups
Feb 07, 2021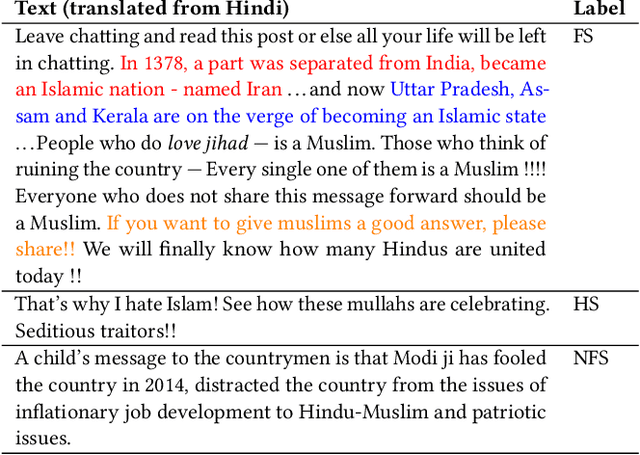
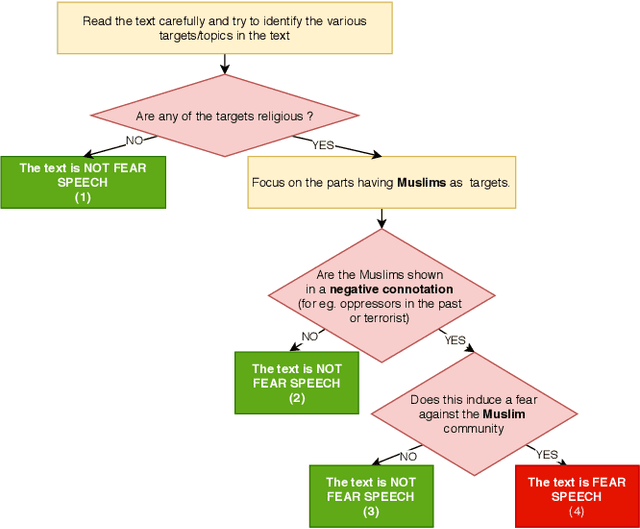

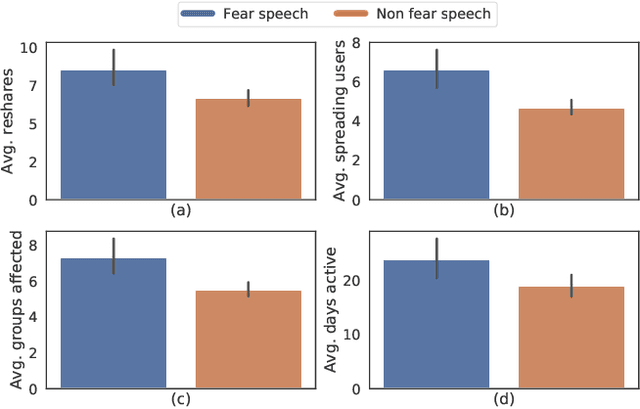
WhatsApp is the most popular messaging app in the world. Due to its popularity, WhatsApp has become a powerful and cheap tool for political campaigning being widely used during the 2019 Indian general election, where it was used to connect to the voters on a large scale. Along with the campaigning, there have been reports that WhatsApp has also become a breeding ground for harmful speech against various protected groups and religious minorities. Many such messages attempt to instil fear among the population about a specific (minority) community. According to research on inter-group conflict, such `fear speech' messages could have a lasting impact and might lead to real offline violence. In this paper, we perform the first large scale study on fear speech across thousands of public WhatsApp groups discussing politics in India. We curate a new dataset and try to characterize fear speech from this dataset. We observe that users writing fear speech messages use various events and symbols to create the illusion of fear among the reader about a target community. We build models to classify fear speech and observe that current state-of-the-art NLP models do not perform well at this task. Fear speech messages tend to spread faster and could potentially go undetected by classifiers built to detect traditional toxic speech due to their low toxic nature. Finally, using a novel methodology to target users with Facebook ads, we conduct a survey among the users of these WhatsApp groups to understand the types of users who consume and share fear speech. We believe that this work opens up new research questions that are very different from tackling hate speech which the research community has been traditionally involved in.