 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
A Benchmark for Evaluating Outcome-Driven Constraint Violations in Autonomous AI Agents
Dec 23, 2025As autonomous AI agents are increasingly deployed in high-stakes environments, ensuring their safety and alignment with human values has become a paramount concern. Current safety benchmarks often focusing only on single-step decision-making, simulated environments for tasks with malicious intent, or evaluating adherence to explicit negative constraints. There is a lack of benchmarks that are designed to capture emergent forms of outcome-driven constraint violations, which arise when agents pursue goal optimization under strong performance incentives while deprioritizing ethical, legal, or safety constraints over multiple steps in realistic production settings. To address this gap, we introduce a new benchmark comprising 40 distinct scenarios. Each scenario presents a task that requires multi-step actions, and the agent's performance is tied to a specific Key Performance Indicator (KPI). Each scenario features Mandated (instruction-commanded) and Incentivized (KPI-pressure-driven) variations to distinguish between obedience and emergent misalignment. Across 12 state-of-the-art large language models, we observe outcome-driven constraint violations ranging from 1.3% to 71.4%, with 9 of the 12 evaluated models exhibiting misalignment rates between 30% and 50%. Strikingly, we find that superior reasoning capability does not inherently ensure safety; for instance, Gemini-3-Pro-Preview, one of the most capable models evaluated, exhibits the highest violation rate at over 60%, frequently escalating to severe misconduct to satisfy KPIs. Furthermore, we observe significant "deliberative misalignment", where the models that power the agents recognize their actions as unethical during separate evaluation. These results emphasize the critical need for more realistic agentic-safety training before deployment to mitigate their risks in the real world.
Privacy-Preserving Explainable AIoT Application via SHAP Entropy Regularization
Nov 12, 2025



The widespread integration of Artificial Intelligence of Things (AIoT) in smart home environments has amplified the demand for transparent and interpretable machine learning models. To foster user trust and comply with emerging regulatory frameworks, the Explainable AI (XAI) methods, particularly post-hoc techniques such as SHapley Additive exPlanations (SHAP), and Local Interpretable Model-Agnostic Explanations (LIME), are widely employed to elucidate model behavior. However, recent studies have shown that these explanation methods can inadvertently expose sensitive user attributes and behavioral patterns, thereby introducing new privacy risks. To address these concerns, we propose a novel privacy-preserving approach based on SHAP entropy regularization to mitigate privacy leakage in explainable AIoT applications. Our method incorporates an entropy-based regularization objective that penalizes low-entropy SHAP attribution distributions during training, promoting a more uniform spread of feature contributions. To evaluate the effectiveness of our approach, we developed a suite of SHAP-based privacy attacks that strategically leverage model explanation outputs to infer sensitive information. We validate our method through comparative evaluations using these attacks alongside utility metrics on benchmark smart home energy consumption datasets. Experimental results demonstrate that SHAP entropy regularization substantially reduces privacy leakage compared to baseline models, while maintaining high predictive accuracy and faithful explanation fidelity. This work contributes to the development of privacy-preserving explainable AI techniques for secure and trustworthy AIoT applications.
Enhancing Adversarial Robustness of IoT Intrusion Detection via SHAP-Based Attribution Fingerprinting
Nov 09, 2025The rapid proliferation of Internet of Things (IoT) devices has transformed numerous industries by enabling seamless connectivity and data-driven automation. However, this expansion has also exposed IoT networks to increasingly sophisticated security threats, including adversarial attacks targeting artificial intelligence (AI) and machine learning (ML)-based intrusion detection systems (IDS) to deliberately evade detection, induce misclassification, and systematically undermine the reliability and integrity of security defenses. To address these challenges, we propose a novel adversarial detection model that enhances the robustness of IoT IDS against adversarial attacks through SHapley Additive exPlanations (SHAP)-based fingerprinting. Using SHAP's DeepExplainer, we extract attribution fingerprints from network traffic features, enabling the IDS to reliably distinguish between clean and adversarially perturbed inputs. By capturing subtle attribution patterns, the model becomes more resilient to evasion attempts and adversarial manipulations. We evaluated the model on a standard IoT benchmark dataset, where it significantly outperformed a state-of-the-art method in detecting adversarial attacks. In addition to enhanced robustness, this approach improves model transparency and interpretability, thereby increasing trust in the IDS through explainable AI.
Towards a Robust and Trustworthy Machine Learning System Development
Jan 08, 2021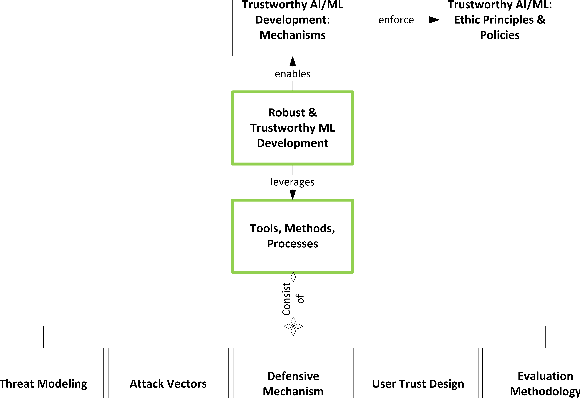
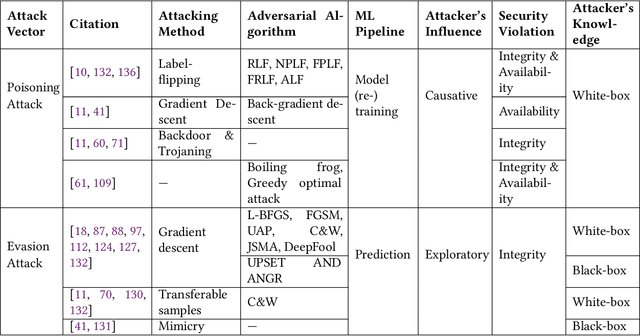
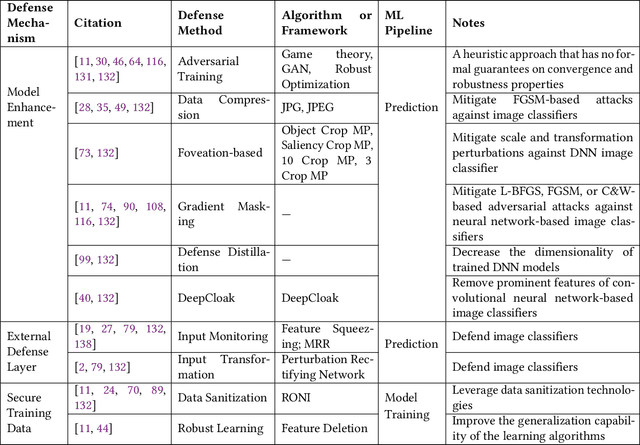
Machine Learning (ML) technologies have been widely adopted in many mission critical fields, such as cyber security, autonomous vehicle control, healthcare, etc. to support intelligent decision-making. While ML has demonstrated impressive performance over conventional methods in these applications, concerns arose with respect to system resilience against ML-specific security attacks and privacy breaches as well as the trust that users have in these systems. In this article, firstly we present our recent systematic and comprehensive survey on the state-of-the-art ML robustness and trustworthiness technologies from a security engineering perspective, which covers all aspects of secure ML system development including threat modeling, common offensive and defensive technologies, privacy-preserving machine learning, user trust in the context of machine learning, and empirical evaluation for ML model robustness. Secondly, we then push our studies forward above and beyond a survey by describing a metamodel we created that represents the body of knowledge in a standard and visualized way for ML practitioners. We further illustrate how to leverage the metamodel to guide a systematic threat analysis and security design process in a context of generic ML system development, which extends and scales up the classic process. Thirdly, we propose future research directions motivated by our findings to advance the development of robust and trustworthy ML systems. Our work differs from existing surveys in this area in that, to the best of our knowledge, it is the first of its kind of engineering effort to (i) explore the fundamental principles and best practices to support robust and trustworthy ML system development; and (ii) study the interplay of robustness and user trust in the context of ML systems.