 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Temporal Framing in the News
May 29, 2026Temporal language does more than place events on a timeline. In news discourse, references to the past, present, and future can function as rhetorical devices that shape interpretation and persuasion. Here, we study temporal framing, defined as the persuasive use of time-related language to structure meaning rather than to report chronology. We propose a taxonomy of eight temporal frames grounded in prior work on temporality and framing, and we realize it through expert annotation of a multilingual news corpus. The resulting dataset includes 458 English and German news articles, with over 2K temporally framed sentences and approximately 3K temporal framing annotations identified from a corpus of more than 20K sentences. We analyze frame prevalence, co-occurrence patterns, and lexical cues, and evaluate temporal framing detection using supervised fine-tuning and zero-shot classification. Our experiments show that temporal framing is learnable at the sentence level, with supervised models substantially outperforming zero-shot approaches. We publicly release the corpus to support future research on temporal framing: https://mbzuai-nlp.github.io/temporal-framing/.
Fine-tuning with Hierarchical Prompting for Robust Propaganda Classification Across Annotation Schemas
May 13, 2026Propaganda detection in social media is challenging due to noisy, short texts and low annotation agreements. We introduce a new intent-focused taxonomy of propaganda techniques and compare it against an established, higher-agreement schema. Along three dimensions (model portfolio, schema effects, and prompting strategy) we evaluate the taxonomies as a classification task with the help of four language models (GPT-4.1-nano, Phi-4 14B, Qwen2.5-14B, Qwen3-14B). Our results show that fine-tuning is essential, since it transforms weak zero-shot baselines into competitive systems and reveals methodological differences that are hidden using base models. Across schemas, the Qwen models achieve the strongest overall performance, and Phi-4 14B consistently outperforms GPT-4.1-nano. Our hierarchical prompting method (HiPP), which predicts fine-grained techniques before aggregating them, is especially beneficial after fine-tuning and on the more ambiguous, low-agreement taxonomy, while remaining competitive on the simpler schema. The HQP dataset, annotated with the new intent-based labels, provides a richer lens on propaganda's strategic goals and a challenging benchmark for future work on robust, real-world detection.
From Articles to Premises: Building PrimeFacts, an Extraction Methodology and Resource for Fact-Checking Evidence
May 07, 2026Fact-checking articles encode rich supporting evidence and reasoning, yet this evidence remains largely inaccessible to automated verification systems due to unstructured presentation. We introduce PrimeFacts, a methodology and resource for extracting fine-grained evidence from full fact-checking articles. We compile 13,106 PolitiFact articles with claims, verdicts, and all referenced sources, and we identify 49,718 in-article hyperlinks as natural anchors to pinpoint key evidence. Our framework leverages large language models (LLMs) to rewrite these anchor sentences into stand-alone, context-independent premises and investigates the extraction of additional implicit evidence. In evaluations on cross-article evidence retrieval and claim verification, the extracted premises substantially improve performance. Decontextualized evidence yields higher retrievability, achieving up to a 30 percent relative gain in Mean Reciprocal Rank over verbatim sentences, and using the evidence for verdict prediction raises Macro-F1 by 10-20 points over the baseline. These gains are consistent across different verdict granularities (2-class vs. 5-class) and model architectures. A qualitative analysis indicates that the decontextualized premises remain faithful to the original sources. Our work highlights the promise of reusing fact-checkers' evidence for automation and provides a large-scale resource of structured evidence from real-world fact-checks.
Transparency as Architecture: Structural Compliance Gaps in EU AI Act Article 50 II
Mar 27, 2026Art. 50 II of the EU Artificial Intelligence Act mandates dual transparency for AI-generated content: outputs must be labeled in both human-understandable and machine-readable form for automated verification. This requirement, entering into force in August 2026, collides with fundamental constraints of current generative AI systems. Using synthetic data generation and automated fact-checking as diagnostic use cases, we show that compliance cannot be reduced to post-hoc labeling. In fact-checking pipelines, provenance tracking is not feasible under iterative editorial workflows and non-deterministic LLM outputs; moreover, the assistive-function exemption does not apply, as such systems actively assign truth values rather than supporting editorial presentation. In synthetic data generation, persistent dual-mode marking is paradoxical: watermarks surviving human inspection risk being learned as spurious features during training, while marks suited for machine verification are fragile under standard data processing. Across both domains, three structural gaps obstruct compliance: (a) absent cross-platform marking formats for interleaved human-AI outputs; (b) misalignment between the regulation's 'reliability' criterion and probabilistic model behavior; and (c) missing guidance for adapting disclosures to heterogeneous user expertise. Closing these gaps requires transparency to be treated as an architectural design requirement, demanding interdisciplinary research across legal semantics, AI engineering, and human-centered desi
Multiperspectivity as a Resource for Narrative Similarity Prediction
Mar 23, 2026Predicting narrative similarity can be understood as an inherently interpretive task: different, equally valid readings of the same text can produce divergent interpretations and thus different similarity judgments, posing a fundamental challenge for semantic evaluation benchmarks that encode a single ground truth. Rather than treating this multiperspectivity as a challenge to overcome, we propose to incorporate it in the decision making process of predictive systems. To explore this strategy, we created an ensemble of 31 LLM personas. These range from practitioners following interpretive frameworks to more intuitive, lay-style characters. Our experiments were conducted on the SemEval-2026 Task 4 dataset, where the system achieved an accuracy score of 0.705. Accuracy improves with ensemble size, consistent with Condorcet Jury Theorem-like dynamics under weakened independence. Practitioner personas perform worse individually but produce less correlated errors, yielding larger ensemble gains under majority voting. Our error analysis reveals a consistent negative association between gender-focused interpretive vocabulary and accuracy across all persona categories, suggesting either attention to dimensions not relevant for the benchmark or valid interpretations absent from the ground truth. This finding underscores the need for evaluation frameworks that account for interpretive plurality.
Retrieving Climate Change Disinformation by Narrative
Mar 23, 2026Detecting climate disinformation narratives typically relies on fixed taxonomies, which do not accommodate emerging narratives. Thus, we re-frame narrative detection as a retrieval task: given a narrative's core message as a query, rank texts from a corpus by alignment with that narrative. This formulation requires no predefined label set and can accommodate emerging narratives. We repurpose three climate disinformation datasets (CARDS, Climate Obstruction, climate change subset of PolyNarrative) for retrieval evaluation and propose SpecFi, a framework that generates hypothetical documents to bridge the gap between abstract narrative descriptions and their concrete textual instantiations. SpecFi uses community summaries from graph-based community detection as few-shot examples for generation, achieving a MAP of 0.505 on CARDS without access to narrative labels. We further introduce narrative variance, an embedding-based difficulty metric, and show via partial correlation analysis that standard retrieval degrades on high-variance narratives (BM25 loses 63.4% of MAP), while SpecFi-CS remains robust (32.7% loss). Our analysis also reveals that unsupervised community summaries converge on descriptions close to expert-crafted taxonomies, suggesting that graph-based methods can surface narrative structure from unlabeled text.
Towards Automated Fact-Checking of Real-World Claims: Exploring Task Formulation and Assessment with LLMs
Feb 13, 2025



Fact-checking is necessary to address the increasing volume of misinformation. Traditional fact-checking relies on manual analysis to verify claims, but it is slow and resource-intensive. This study establishes baseline comparisons for Automated Fact-Checking (AFC) using Large Language Models (LLMs) across multiple labeling schemes (binary, three-class, five-class) and extends traditional claim verification by incorporating analysis, verdict classification, and explanation in a structured setup to provide comprehensive justifications for real-world claims. We evaluate Llama-3 models of varying sizes (3B, 8B, 70B) on 17,856 claims collected from PolitiFact (2007-2024) using evidence retrieved via restricted web searches. We utilize TIGERScore as a reference-free evaluation metric to score the justifications. Our results show that larger LLMs consistently outperform smaller LLMs in classification accuracy and justification quality without fine-tuning. We find that smaller LLMs in a one-shot scenario provide comparable task performance to fine-tuned Small Language Models (SLMs) with large context sizes, while larger LLMs consistently surpass them. Evidence integration improves performance across all models, with larger LLMs benefiting most. Distinguishing between nuanced labels remains challenging, emphasizing the need for further exploration of labeling schemes and alignment with evidences. Our findings demonstrate the potential of retrieval-augmented AFC with LLMs.
Towards an Argument Mining Pipeline Transforming Texts to Argument Graphs
Jun 08, 2020


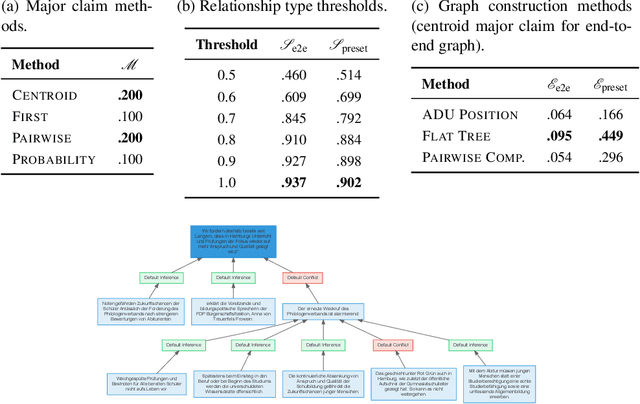
This paper targets the automated extraction of components of argumentative information and their relations from natural language text. Moreover, we address a current lack of systems to provide complete argumentative structure from arbitrary natural language text for general usage. We present an argument mining pipeline as a universally applicable approach for transforming German and English language texts to graph-based argument representations. We also introduce new methods for evaluating the results based on existing benchmark argument structures. Our results show that the generated argument graphs can be beneficial to detect new connections between different statements of an argumentative text. Our pipeline implementation is publicly available on GitHub.
Same Side Stance Classification Task: Facilitating Argument Stance Classification by Fine-tuning a BERT Model
Apr 23, 2020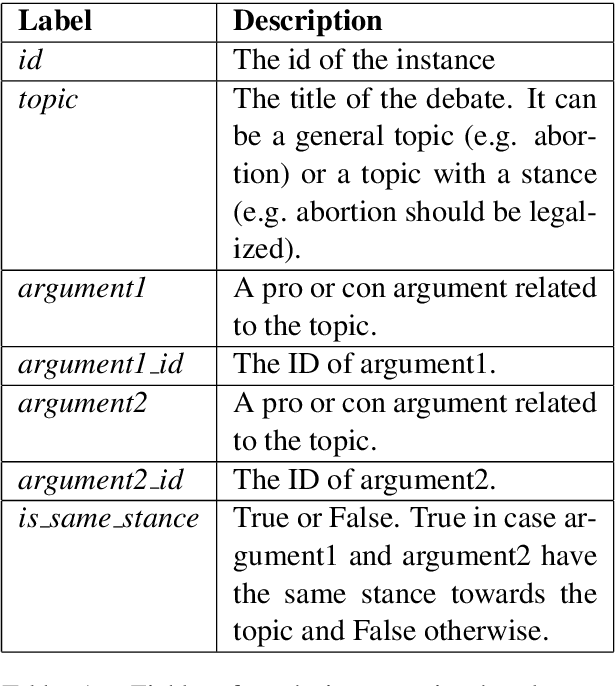
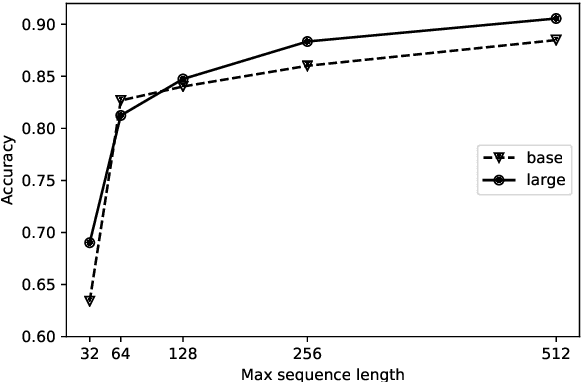
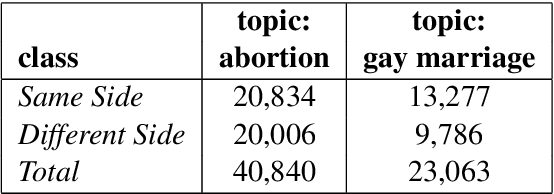
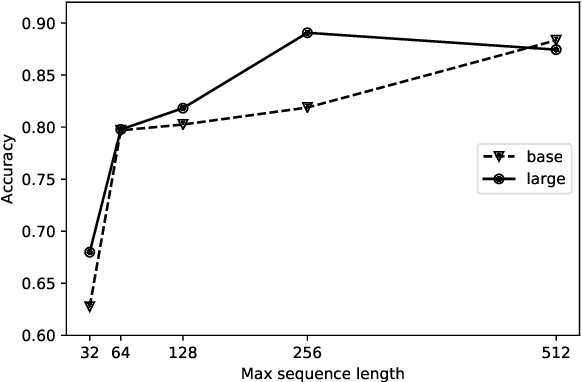
Research on computational argumentation is currently being intensively investigated. The goal of this community is to find the best pro and con arguments for a user given topic either to form an opinion for oneself, or to persuade others to adopt a certain standpoint. While existing argument mining methods can find appropriate arguments for a topic, a correct classification into pro and con is not yet reliable. The same side stance classification task provides a dataset of argument pairs classified by whether or not both arguments share the same stance and does not need to distinguish between topic-specific pro and con vocabulary but only the argument similarity within a stance needs to be assessed. The results of our contribution to the task are build on a setup based on the BERT architecture. We fine-tuned a pre-trained BERT model for three epochs and used the first 512 tokens of each argument to predict if two arguments share the same stance.