 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Word Embeddings by Disentangling Contextual n-Gram Information
Apr 10, 2019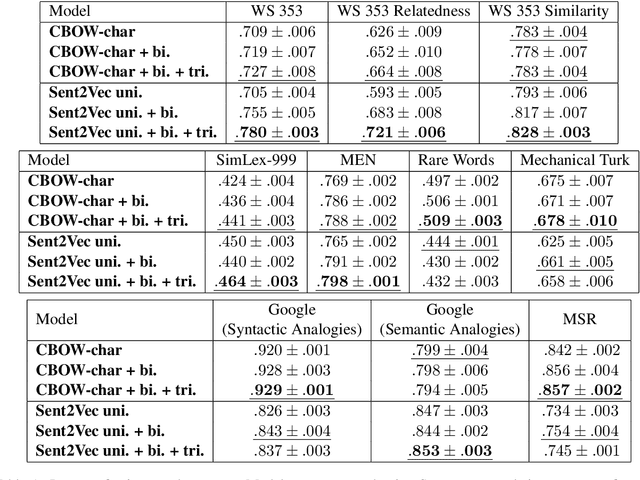
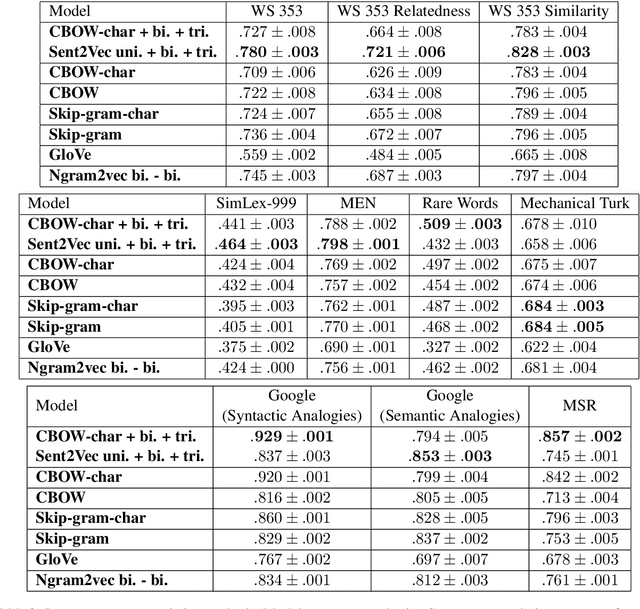
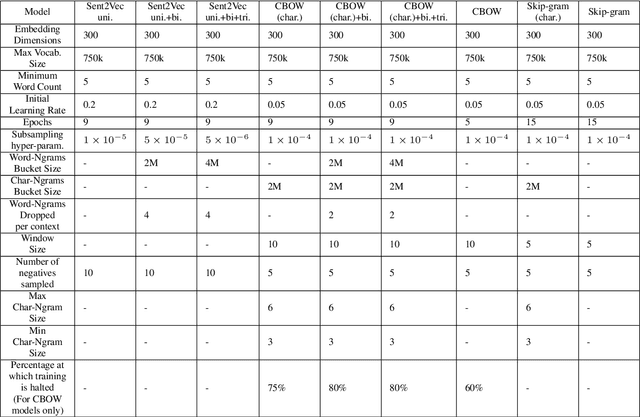
Pre-trained word vectors are ubiquitous in Natural Language Processing applications. In this paper, we show how training word embeddings jointly with bigram and even trigram embeddings, results in improved unigram embeddings. We claim that training word embeddings along with higher n-gram embeddings helps in the removal of the contextual information from the unigrams, resulting in better stand-alone word embeddings. We empirically show the validity of our hypothesis by outperforming other competing word representation models by a significant margin on a wide variety of tasks. We make our models publicly available.
Online Diverse Learning to Rank from Partial-Click Feedback
Nov 01, 2018
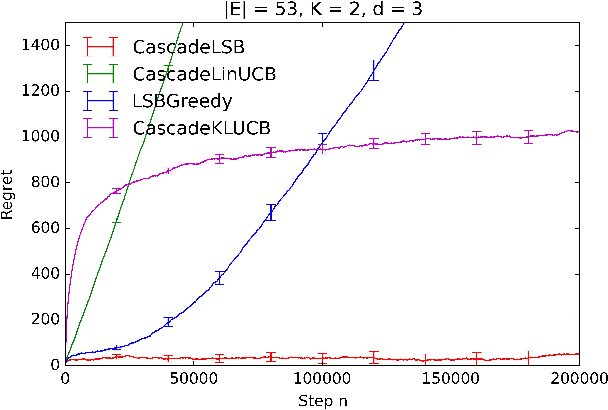

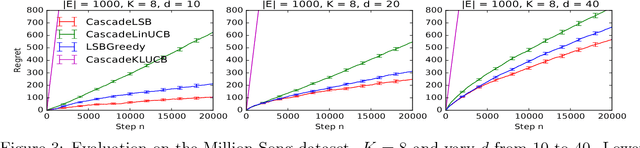
Learning to rank is an important problem in machine learning and recommender systems. In a recommender system, a user is typically recommended a list of items. Since the user is unlikely to examine the entire recommended list, partial feedback arises naturally. At the same time, diverse recommendations are important because it is challenging to model all tastes of the user in practice. In this paper, we propose the first algorithm for online learning to rank diverse items from partial-click feedback. We assume that the user examines the list of recommended items until the user is attracted by an item, which is clicked, and does not examine the rest of the items. This model of user behavior is known as the cascade model. We propose an online learning algorithm, cascadelsb, for solving our problem. The algorithm actively explores the tastes of the user with the objective of learning to recommend the optimal diverse list. We analyze the algorithm and prove a gap-free upper bound on its n-step regret. We evaluate cascadelsb on both synthetic and real-world datasets, compare it to various baselines, and show that it learns even when our modeling assumptions do not hold exactly.
Learning Word Vectors for 157 Languages
Mar 28, 2018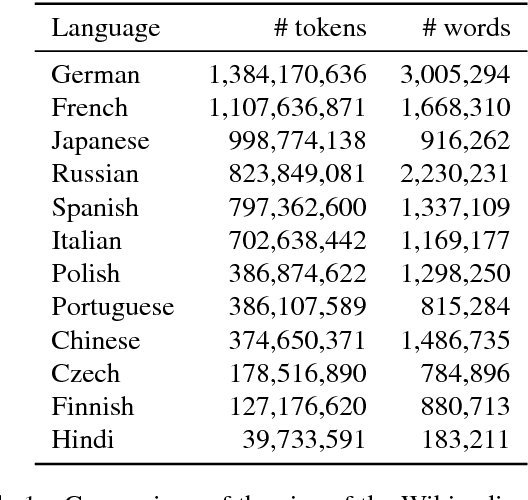
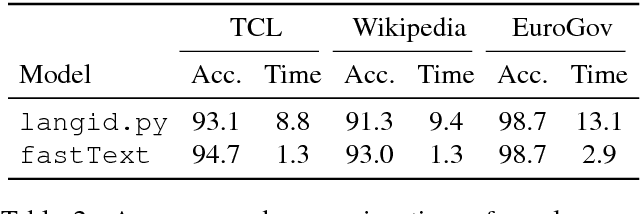
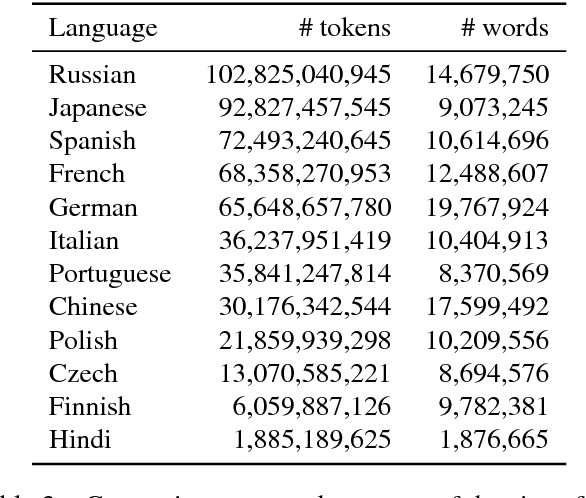
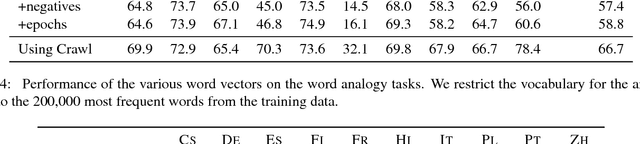
Distributed word representations, or word vectors, have recently been applied to many tasks in natural language processing, leading to state-of-the-art performance. A key ingredient to the successful application of these representations is to train them on very large corpora, and use these pre-trained models in downstream tasks. In this paper, we describe how we trained such high quality word representations for 157 languages. We used two sources of data to train these models: the free online encyclopedia Wikipedia and data from the common crawl project. We also introduce three new word analogy datasets to evaluate these word vectors, for French, Hindi and Polish. Finally, we evaluate our pre-trained word vectors on 10 languages for which evaluation datasets exists, showing very strong performance compared to previous models.
Saliency Prediction for Mobile User Interfaces
Nov 28, 2017
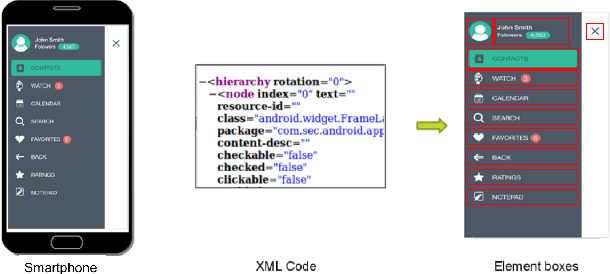

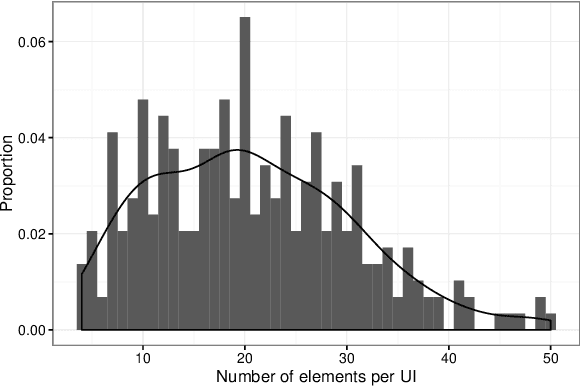
We introduce models for saliency prediction for mobile user interfaces. A mobile interface may include elements like buttons, text, etc. in addition to natural images which enable performing a variety of tasks. Saliency in natural images is a well studied area. However, given the difference in what constitutes a mobile interface, and the usage context of these devices, we postulate that saliency prediction for mobile interface images requires a fresh approach. Mobile interface design involves operating on elements, the building blocks of the interface. We first collected eye-gaze data from mobile devices for free viewing task. Using this data, we develop a novel autoencoder based multi-scale deep learning model that provides saliency prediction at the mobile interface element level. Compared to saliency prediction approaches developed for natural images, we show that our approach performs significantly better on a range of established metrics.
Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
Jul 10, 2017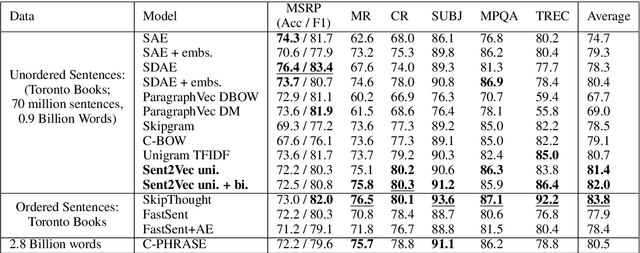
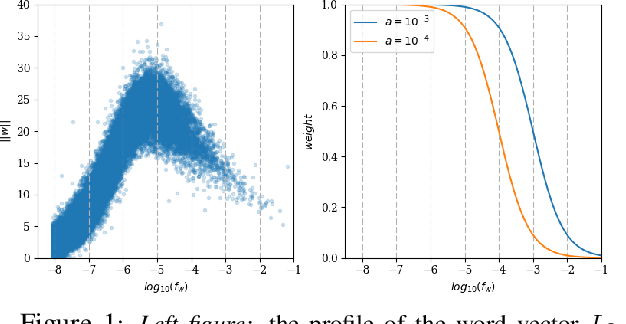
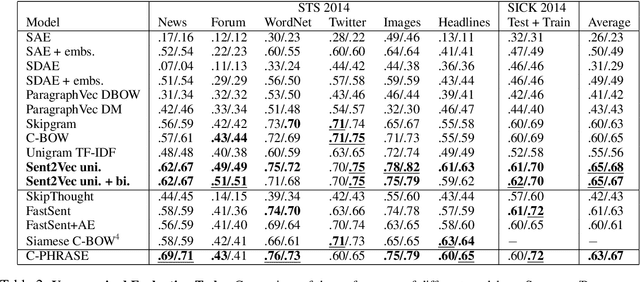
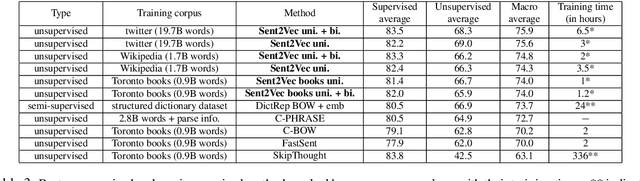
The recent tremendous success of unsupervised word embeddings in a multitude of applications raises the obvious question if similar methods could be derived to improve embeddings (i.e. semantic representations) of word sequences as well. We present a simple but efficient unsupervised objective to train distributed representations of sentences. Our method outperforms the state-of-the-art unsupervised models on most benchmark tasks, highlighting the robustness of the produced general-purpose sentence embeddings.