 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrakhar Gupta
Synthesizing Adversarial Negative Responses for Robust Response Ranking and Evaluation
Jun 10, 2021
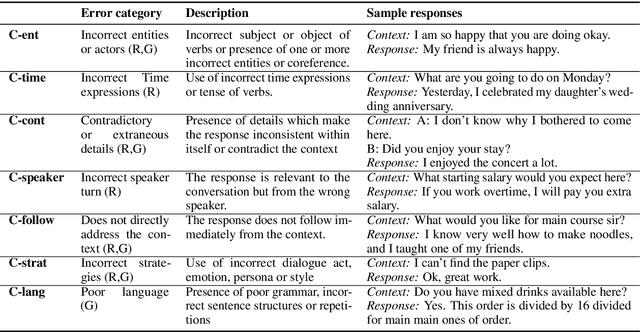
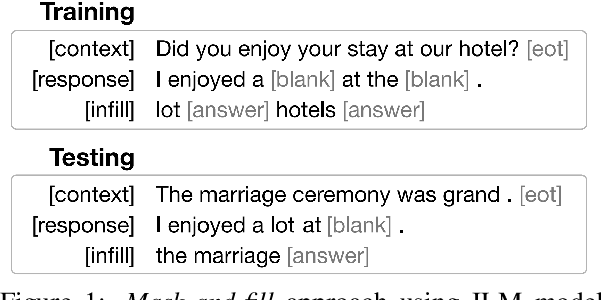

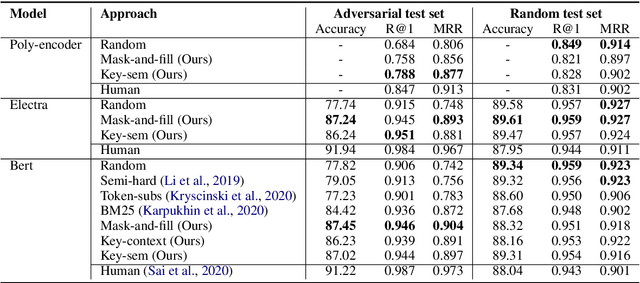
Open-domain neural dialogue models have achieved high performance in response ranking and evaluation tasks. These tasks are formulated as a binary classification of responses given in a dialogue context, and models generally learn to make predictions based on context-response content similarity. However, over-reliance on content similarity makes the models less sensitive to the presence of inconsistencies, incorrect time expressions and other factors important for response appropriateness and coherence. We propose approaches for automatically creating adversarial negative training data to help ranking and evaluation models learn features beyond content similarity. We propose mask-and-fill and keyword-guided approaches that generate negative examples for training more robust dialogue systems. These generated adversarial responses have high content similarity with the contexts but are either incoherent, inappropriate or not fluent. Our approaches are fully data-driven and can be easily incorporated in existing models and datasets. Experiments on classification, ranking and evaluation tasks across multiple datasets demonstrate that our approaches outperform strong baselines in providing informative negative examples for training dialogue systems.
Obtaining Better Static Word Embeddings Using Contextual Embedding Models
Jun 08, 2021
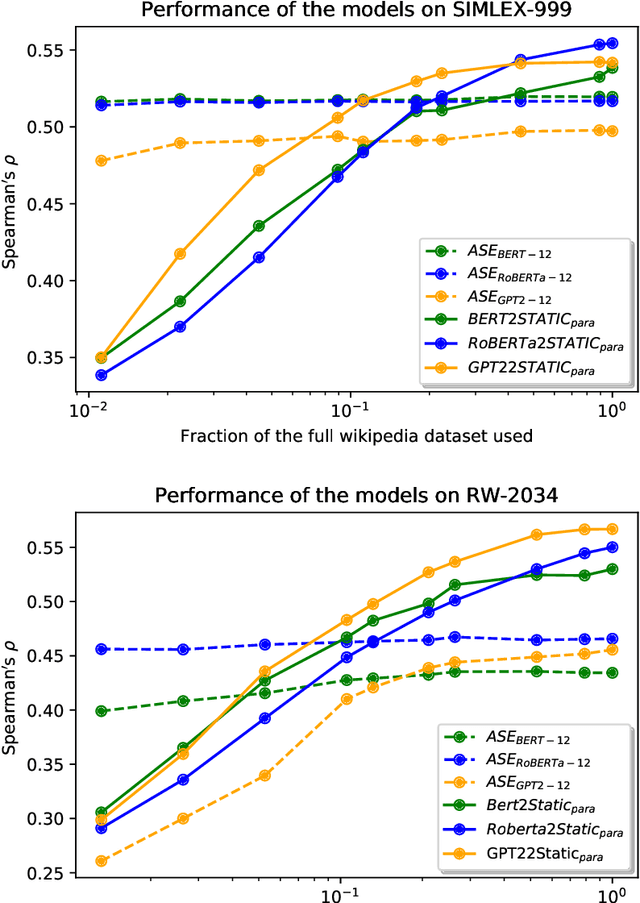

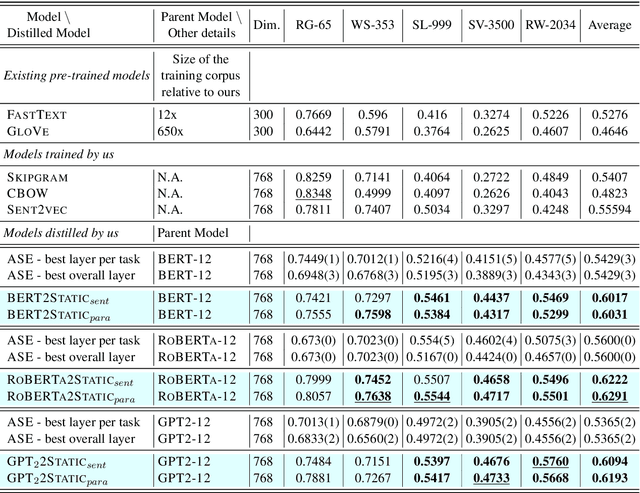
The advent of contextual word embeddings -- representations of words which incorporate semantic and syntactic information from their context -- has led to tremendous improvements on a wide variety of NLP tasks. However, recent contextual models have prohibitively high computational cost in many use-cases and are often hard to interpret. In this work, we demonstrate that our proposed distillation method, which is a simple extension of CBOW-based training, allows to significantly improve computational efficiency of NLP applications, while outperforming the quality of existing static embeddings trained from scratch as well as those distilled from previously proposed methods. As a side-effect, our approach also allows a fair comparison of both contextual and static embeddings via standard lexical evaluation tasks.
Lightweight Cross-Lingual Sentence Representation Learning
May 28, 2021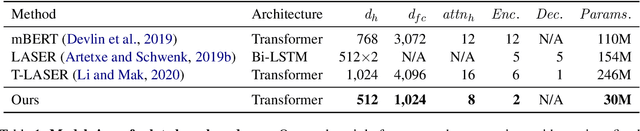
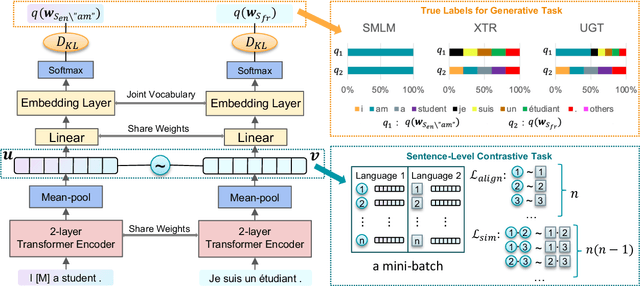
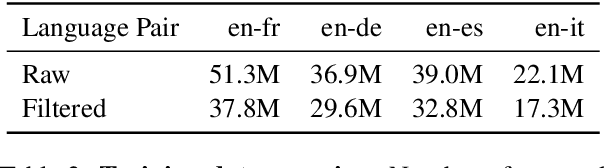
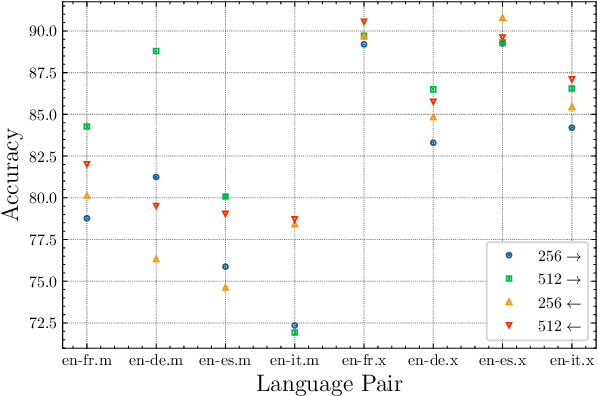
Large-scale models for learning fixed-dimensional cross-lingual sentence representations like Large-scale models for learning fixed-dimensional cross-lingual sentence representations like LASER (Artetxe and Schwenk, 2019b) lead to significant improvement in performance on downstream tasks. However, further increases and modifications based on such large-scale models are usually impractical due to memory limitations. In this work, we introduce a lightweight dual-transformer architecture with just 2 layers for generating memory-efficient cross-lingual sentence representations. We explore different training tasks and observe that current cross-lingual training tasks leave a lot to be desired for this shallow architecture. To ameliorate this, we propose a novel cross-lingual language model, which combines the existing single-word masked language model with the newly proposed cross-lingual token-level reconstruction task. We further augment the training task by the introduction of two computationally-lite sentence-level contrastive learning tasks to enhance the alignment of cross-lingual sentence representation space, which compensates for the learning bottleneck of the lightweight transformer for generative tasks. Our comparisons with competing models on cross-lingual sentence retrieval and multilingual document classification confirm the effectiveness of the newly proposed training tasks for a shallow model.
Controlling Dialogue Generation with Semantic Exemplars
Aug 20, 2020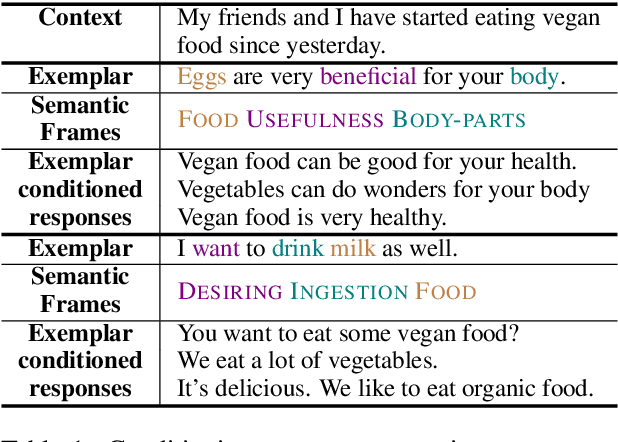
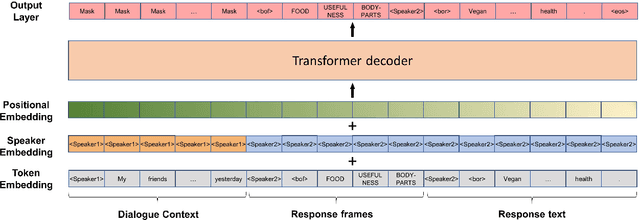
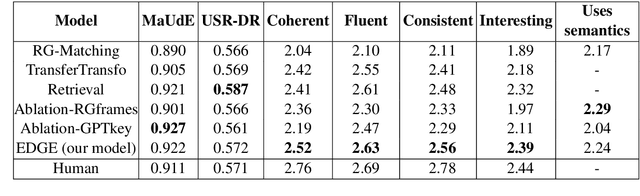
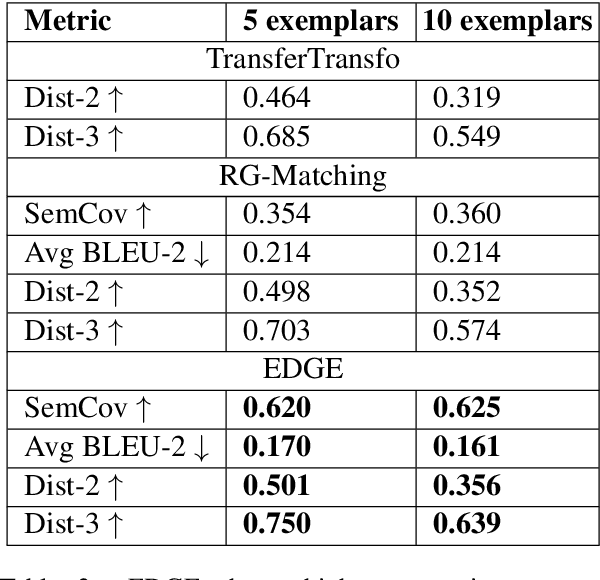
Dialogue systems pretrained with large language models generate locally coherent responses, but lack the fine-grained control over responses necessary to achieve specific goals. A promising method to control response generation is exemplar-based generation, in which models edit exemplar responses that are retrieved from training data, or hand-written to strategically address discourse-level goals, to fit new dialogue contexts. But, current exemplar-based approaches often excessively copy words from the exemplar responses, leading to incoherent replies. We present an Exemplar-based Dialogue Generation model, EDGE, that uses the semantic frames present in exemplar responses to guide generation. We show that controlling dialogue generation based on the semantic frames of exemplars, rather than words in the exemplar itself, improves the coherence of generated responses, while preserving semantic meaning and conversation goals present in exemplar responses.
Using Image Captions and Multitask Learning for Recommending Query Reformulations
Mar 02, 2020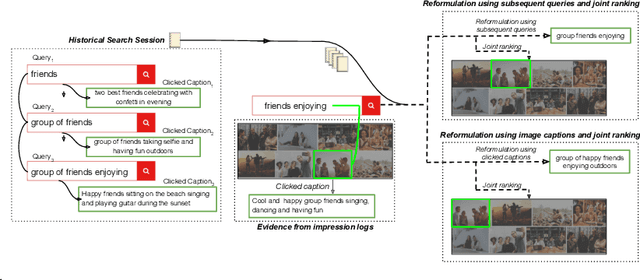
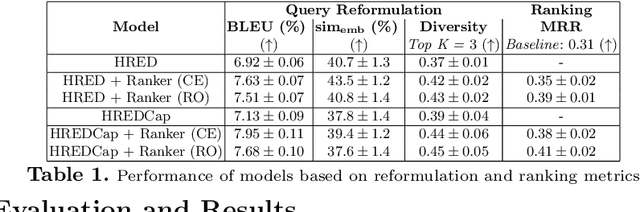
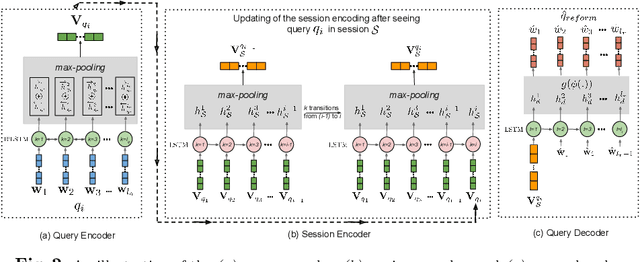
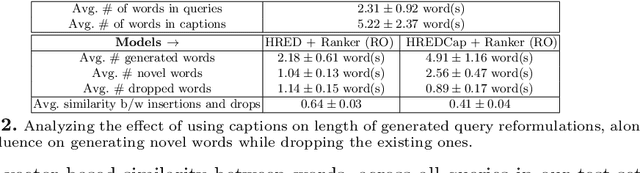
Interactive search sessions often contain multiple queries, where the user submits a reformulated version of the previous query in response to the original results. We aim to enhance the query recommendation experience for a commercial image search engine. Our proposed methodology incorporates current state-of-the-art practices from relevant literature -- the use of generation-based sequence-to-sequence models that capture session context, and a multitask architecture that simultaneously optimizes the ranking of results. We extend this setup by driving the learning of such a model with captions of clicked images as the target, instead of using the subsequent query within the session. Since these captions tend to be linguistically richer, the reformulation mechanism can be seen as assistance to construct more descriptive queries. In addition, via the use of a pairwise loss for the secondary ranking task, we show that the generated reformulations are more diverse.
Robust Cross-lingual Embeddings from Parallel Sentences
Dec 28, 2019
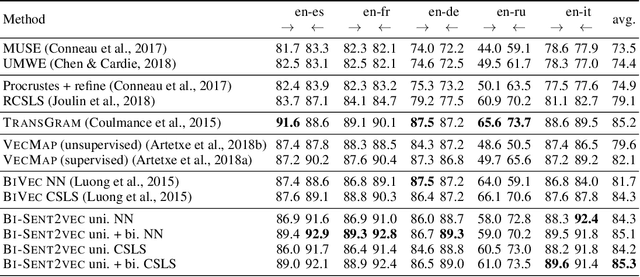
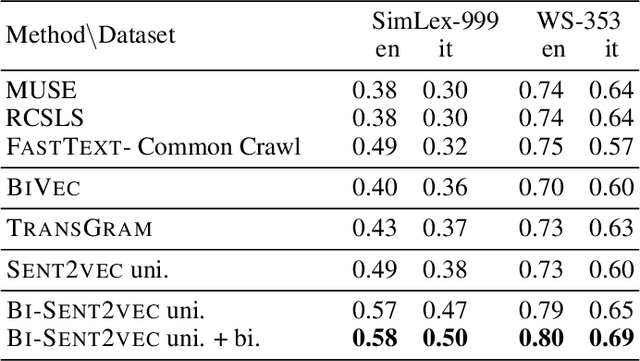
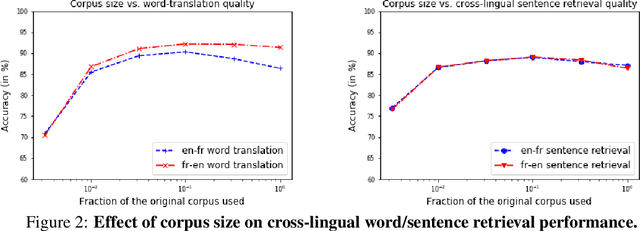
Recent advances in cross-lingual word embeddings have primarily relied on mapping-based methods, which project pretrained word embeddings from different languages into a shared space through a linear transformation. However, these approaches assume word embedding spaces are isomorphic between different languages, which has been shown not to hold in practice (S{\o}gaard et al., 2018), and fundamentally limits their performance. This motivates investigating joint learning methods which can overcome this impediment, by simultaneously learning embeddings across languages via a cross-lingual term in the training objective. Given the abundance of parallel data available (Tiedemann, 2012), we propose a bilingual extension of the CBOW method which leverages sentence-aligned corpora to obtain robust cross-lingual word and sentence representations. Our approach significantly improves cross-lingual sentence retrieval performance over all other approaches, as well as convincingly outscores mapping methods while maintaining parity with jointly trained methods on word-translation. It also achieves parity with a deep RNN method on a zero-shot cross-lingual document classification task, requiring far fewer computational resources for training and inference. As an additional advantage, our bilingual method also improves the quality of monolingual word vectors despite training on much smaller datasets. We make our code and models publicly available.
Investigating Evaluation of Open-Domain Dialogue Systems With Human Generated Multiple References
Sep 08, 2019
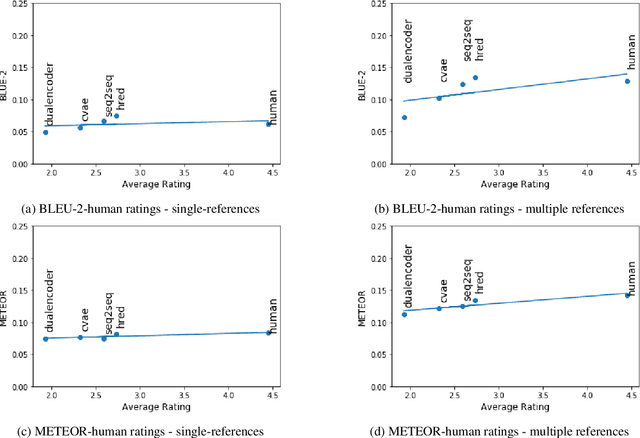
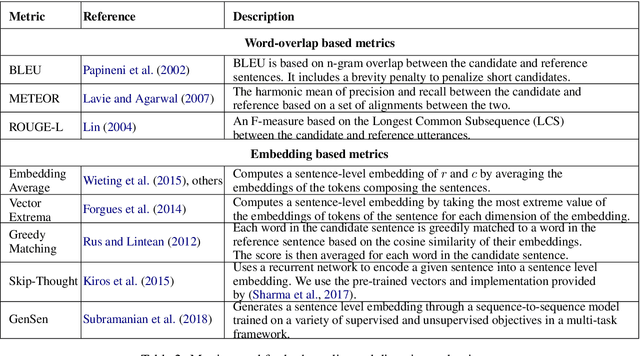
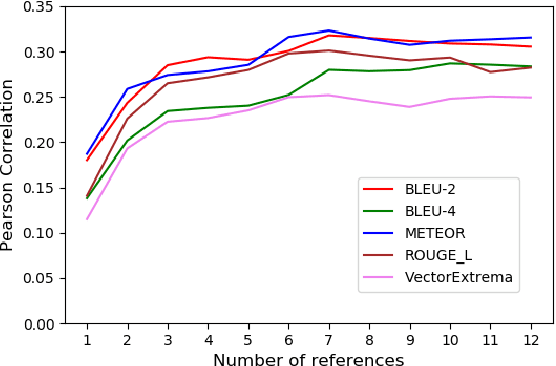
The aim of this paper is to mitigate the shortcomings of automatic evaluation of open-domain dialog systems through multi-reference evaluation. Existing metrics have been shown to correlate poorly with human judgement, particularly in open-domain dialog. One alternative is to collect human annotations for evaluation, which can be expensive and time consuming. To demonstrate the effectiveness of multi-reference evaluation, we augment the test set of DailyDialog with multiple references. A series of experiments show that the use of multiple references results in improved correlation between several automatic metrics and human judgement for both the quality and the diversity of system output.
WriterForcing: Generating more interesting story endings
Jul 18, 2019

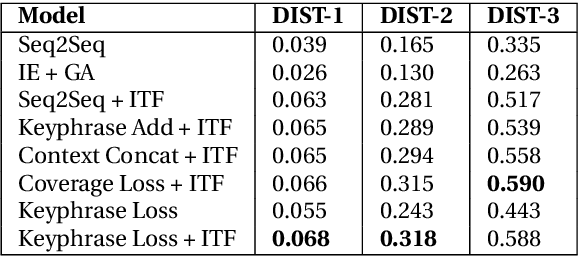
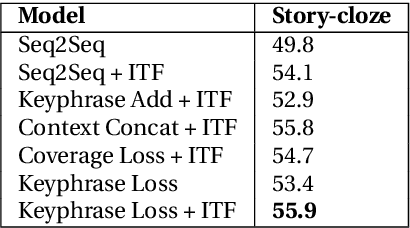
We study the problem of generating interesting endings for stories. Neural generative models have shown promising results for various text generation problems. Sequence to Sequence (Seq2Seq) models are typically trained to generate a single output sequence for a given input sequence. However, in the context of a story, multiple endings are possible. Seq2Seq models tend to ignore the context and generate generic and dull responses. Very few works have studied generating diverse and interesting story endings for a given story context. In this paper, we propose models which generate more diverse and interesting outputs by 1) training models to focus attention on important keyphrases of the story, and 2) promoting generation of non-generic words. We show that the combination of the two leads to more diverse and interesting endings.
Better Word Embeddings by Disentangling Contextual n-Gram Information
Apr 10, 2019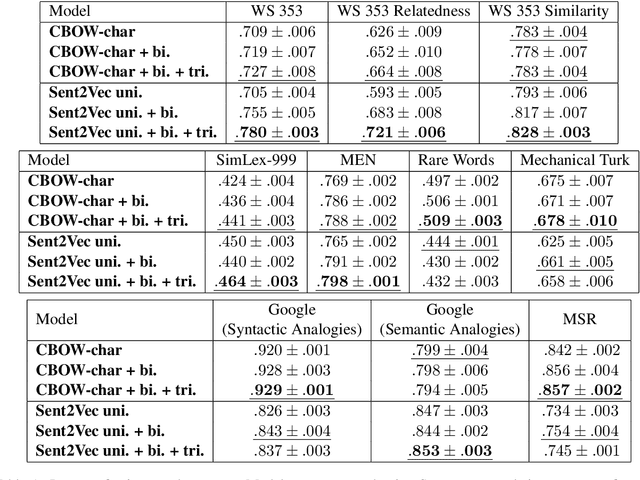
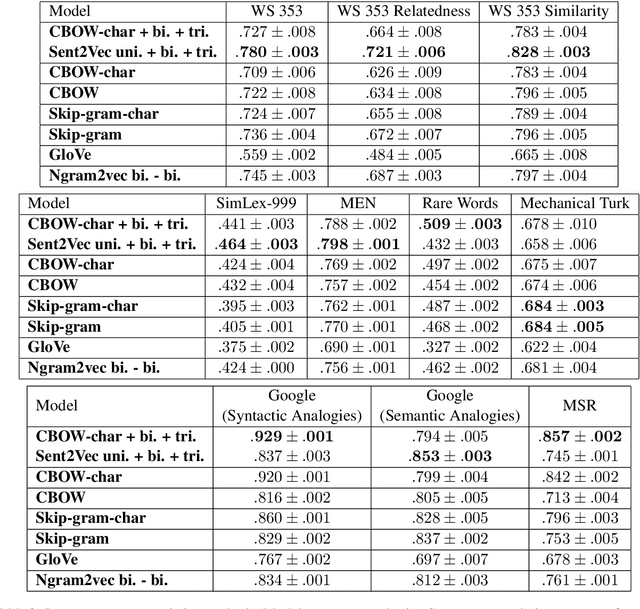
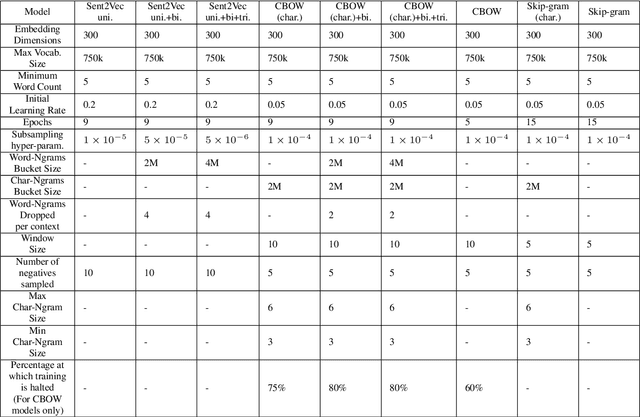
Pre-trained word vectors are ubiquitous in Natural Language Processing applications. In this paper, we show how training word embeddings jointly with bigram and even trigram embeddings, results in improved unigram embeddings. We claim that training word embeddings along with higher n-gram embeddings helps in the removal of the contextual information from the unigrams, resulting in better stand-alone word embeddings. We empirically show the validity of our hypothesis by outperforming other competing word representation models by a significant margin on a wide variety of tasks. We make our models publicly available.