 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUOCA: Budget-Optimized Crowd Worker Allocation
Jan 11, 2019
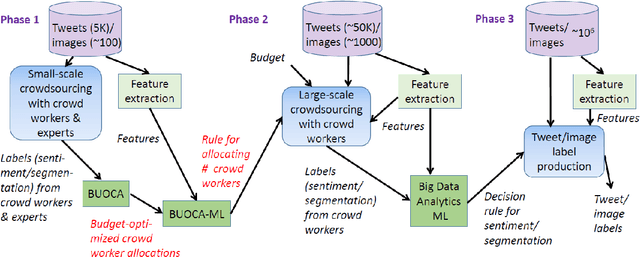
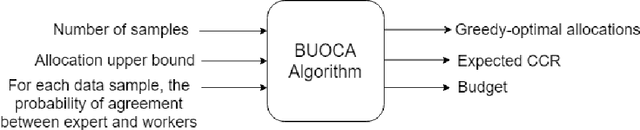

Due to concerns about human error in crowdsourcing, it is standard practice to collect labels for the same data point from multiple internet workers. We here show that the resulting budget can be used more effectively with a flexible worker assignment strategy that asks fewer workers to analyze easy-to-label data and more workers to analyze data that requires extra scrutiny. Our main contribution is to show how the allocations of the number of workers to a task can be computed optimally based on task features alone, without using worker profiles. Our target tasks are delineating cells in microscopy images and analyzing the sentiment toward the 2016 U.S. presidential candidates in tweets. We first propose an algorithm that computes budget-optimized crowd worker allocation (BUOCA). We next train a machine learning system (BUOCA-ML) that predicts an optimal number of crowd workers needed to maximize the accuracy of the labeling. We show that the computed allocation can yield large savings in the crowdsourcing budget (up to 49 percent points) while maintaining labeling accuracy. Finally, we envisage a human-machine system for performing budget-optimized data analysis at a scale beyond the feasibility of crowdsourcing.
Semi-Coupled Two-Stream Fusion ConvNets for Action Recognition at Extremely Low Resolutions
Oct 05, 2018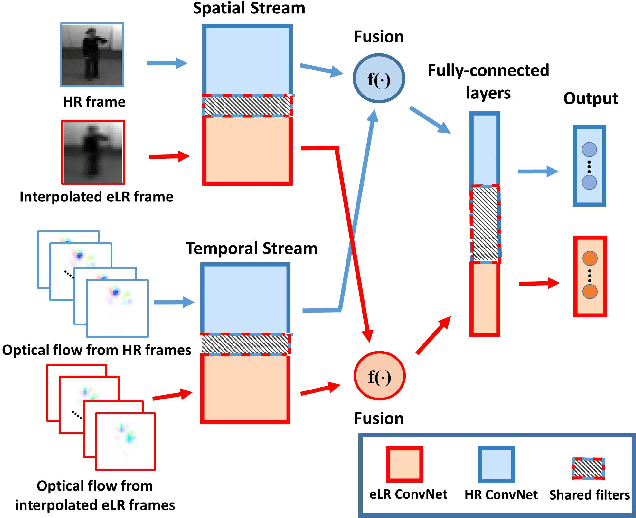
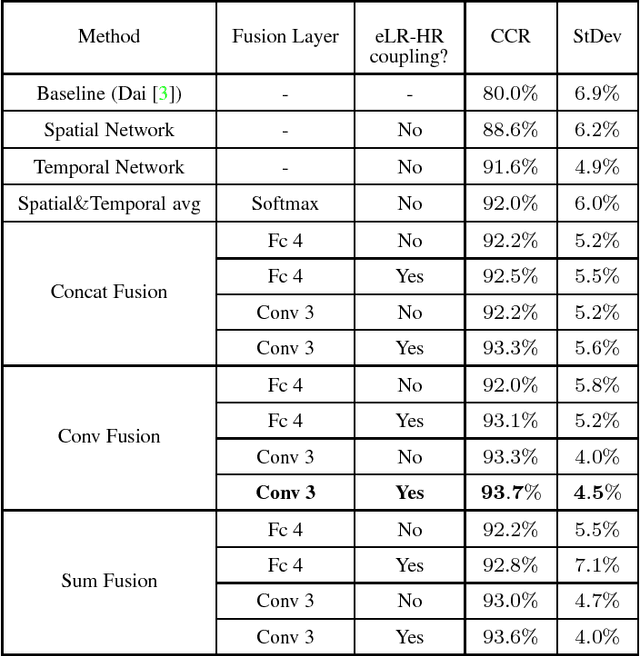
Deep convolutional neural networks (ConvNets) have been recently shown to attain state-of-the-art performance for action recognition on standard-resolution videos. However, less attention has been paid to recognition performance at extremely low resolutions (eLR) (e.g., 16 x 12 pixels). Reliable action recognition using eLR cameras would address privacy concerns in various application environments such as private homes, hospitals, nursing/rehabilitation facilities, etc. In this paper, we propose a semi-coupled filter-sharing network that leverages high resolution (HR) videos during training in order to assist an eLR ConvNet. We also study methods for fusing spatial and temporal ConvNets customized for eLR videos in order to take advantage of appearance and motion information. Our method outperforms state-of-the-art methods at extremely low resolutions on IXMAS (93.7%) and HMDB (29.2%) datasets.
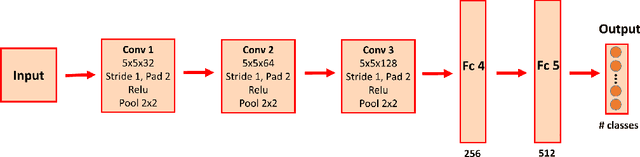
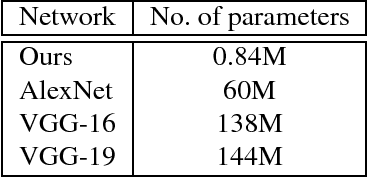
VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition
Sep 07, 2018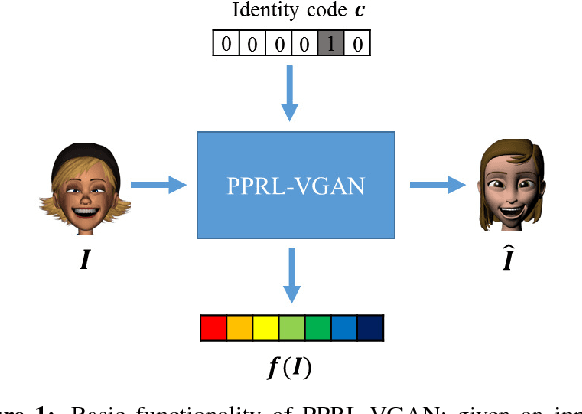

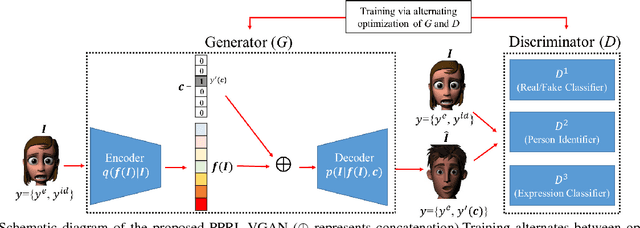
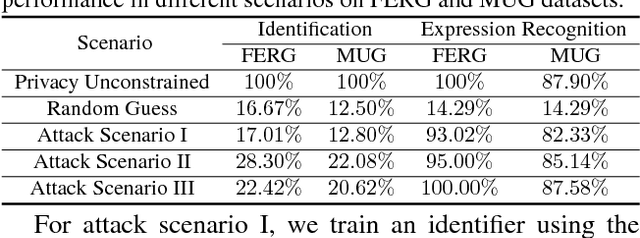
Reliable facial expression recognition plays a critical role in human-machine interactions. However, most of the facial expression analysis methodologies proposed to date pay little or no attention to the protection of a user's privacy. In this paper, we propose a Privacy-Preserving Representation-Learning Variational Generative Adversarial Network (PPRL-VGAN) to learn an image representation that is explicitly disentangled from the identity information. At the same time, this representation is discriminative from the standpoint of facial expression recognition and generative as it allows expression-equivalent face image synthesis. We evaluate the proposed model on two public datasets under various threat scenarios. Quantitative and qualitative results demonstrate that our approach strikes a balance between the preservation of privacy and data utility. We further demonstrate that our model can be effectively applied to other tasks such as expression morphing and image completion.
Privacy-Preserving Adversarial Networks
Dec 19, 2017
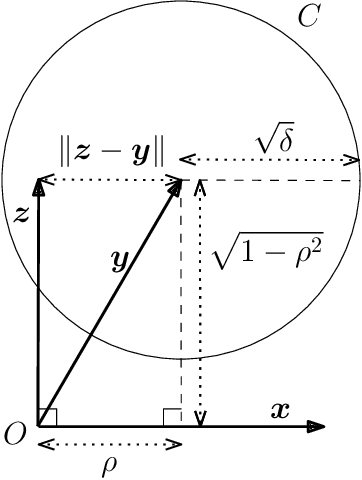
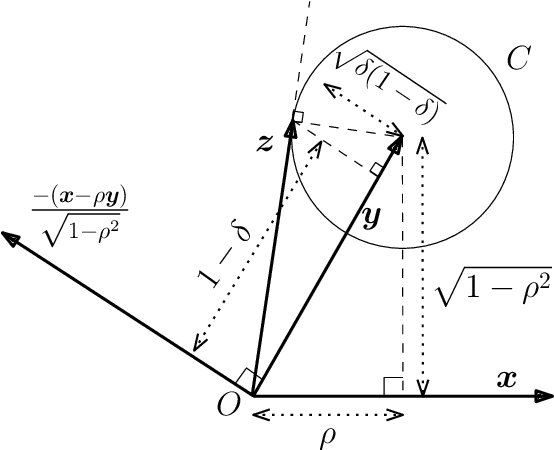
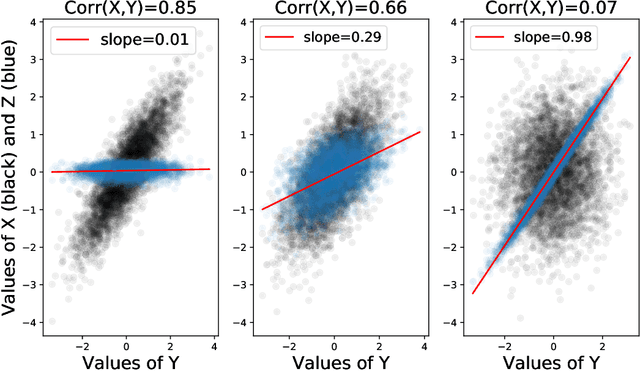
We propose a data-driven framework for optimizing privacy-preserving data release mechanisms toward the information-theoretically optimal tradeoff between minimizing distortion of useful data and concealing sensitive information. Our approach employs adversarially-trained neural networks to implement randomized mechanisms and to perform a variational approximation of mutual information privacy. We empirically validate our Privacy-Preserving Adversarial Networks (PPAN) framework with experiments conducted on discrete and continuous synthetic data, as well as the MNIST handwritten digits dataset. With the synthetic data, we find that our model-agnostic PPAN approach achieves tradeoff points very close to the optimal tradeoffs that are analytically-derived from model knowledge. In experiments with the MNIST data, we visually demonstrate a learned tradeoff between minimizing the pixel-level distortion versus concealing the written digit.
Node Embedding via Word Embedding for Network Community Discovery
Jun 28, 2017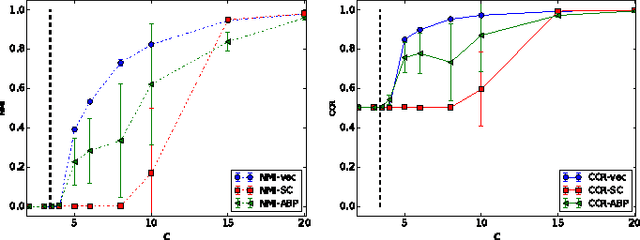
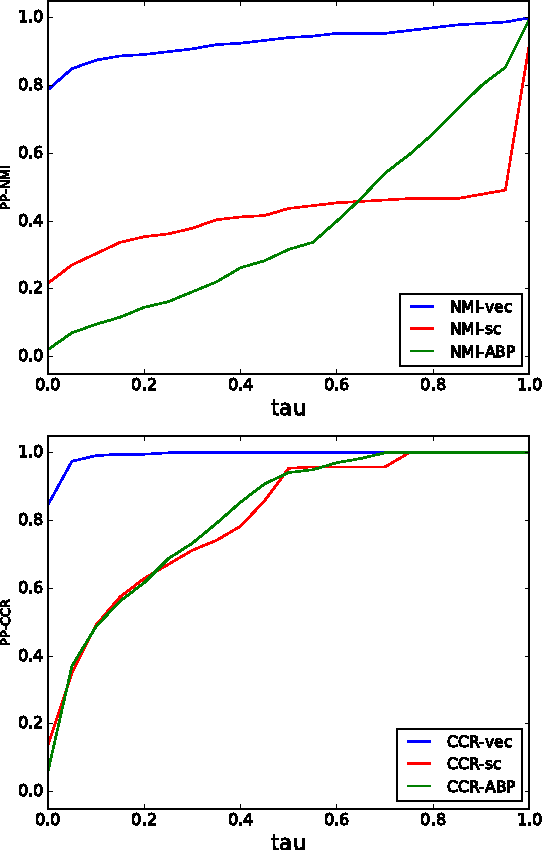
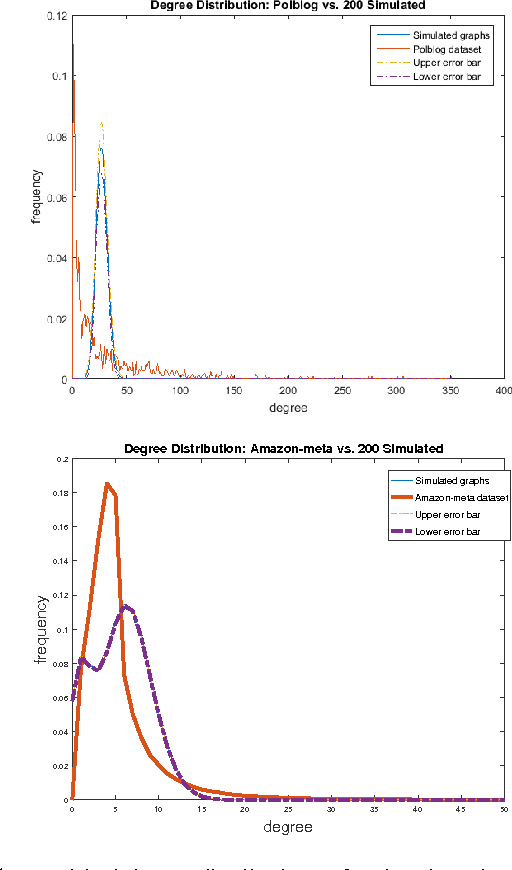
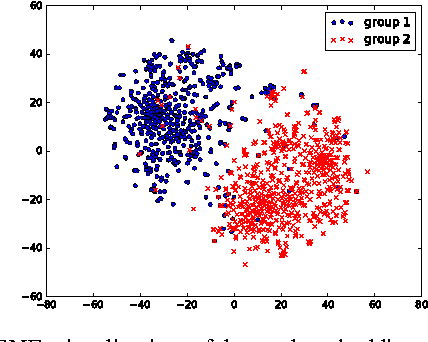
Neural node embeddings have recently emerged as a powerful representation for supervised learning tasks involving graph-structured data. We leverage this recent advance to develop a novel algorithm for unsupervised community discovery in graphs. Through extensive experimental studies on simulated and real-world data, we demonstrate that the proposed approach consistently improves over the current state-of-the-art. Specifically, our approach empirically attains the information-theoretic limits for community recovery under the benchmark Stochastic Block Models for graph generation and exhibits better stability and accuracy over both Spectral Clustering and Acyclic Belief Propagation in the community recovery limits.
Necessary and Sufficient Conditions and a Provably Efficient Algorithm for Separable Topic Discovery
Dec 04, 2015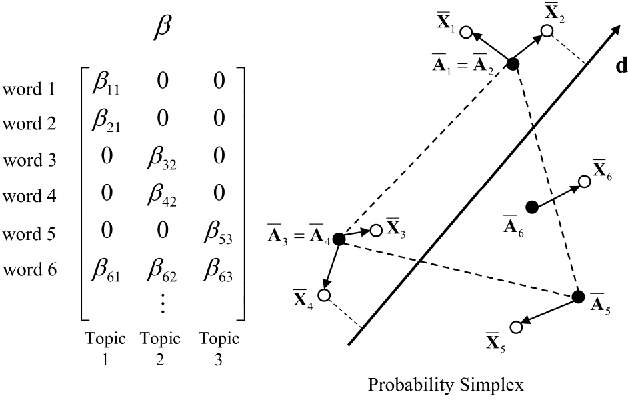
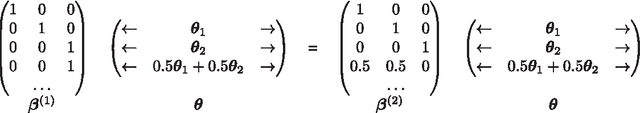
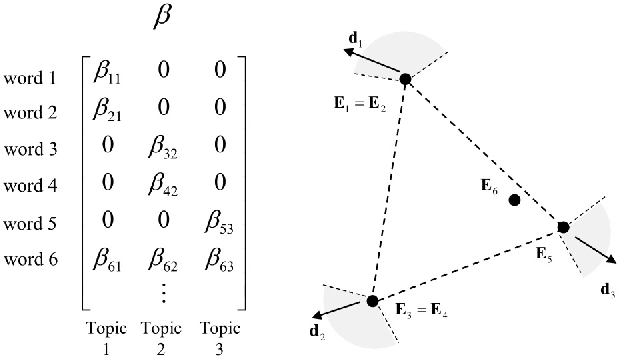
We develop necessary and sufficient conditions and a novel provably consistent and efficient algorithm for discovering topics (latent factors) from observations (documents) that are realized from a probabilistic mixture of shared latent factors that have certain properties. Our focus is on the class of topic models in which each shared latent factor contains a novel word that is unique to that factor, a property that has come to be known as separability. Our algorithm is based on the key insight that the novel words correspond to the extreme points of the convex hull formed by the row-vectors of a suitably normalized word co-occurrence matrix. We leverage this geometric insight to establish polynomial computation and sample complexity bounds based on a few isotropic random projections of the rows of the normalized word co-occurrence matrix. Our proposed random-projections-based algorithm is naturally amenable to an efficient distributed implementation and is attractive for modern web-scale distributed data mining applications.
Learning Mixed Membership Mallows Models from Pairwise Comparisons
Apr 03, 2015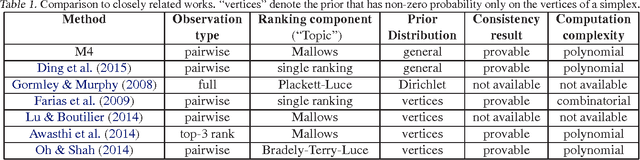
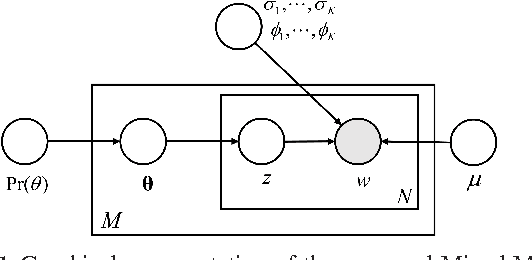
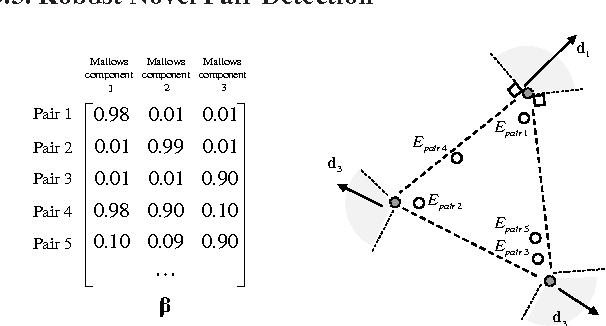
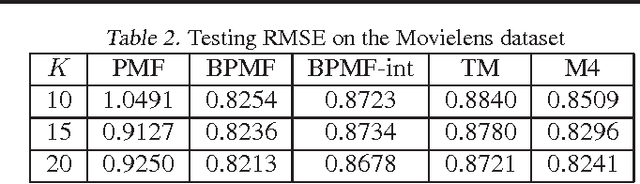
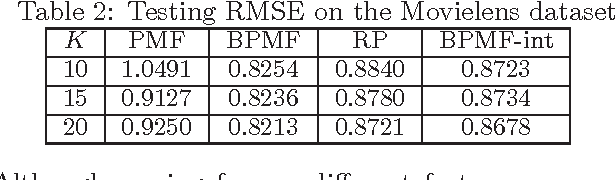
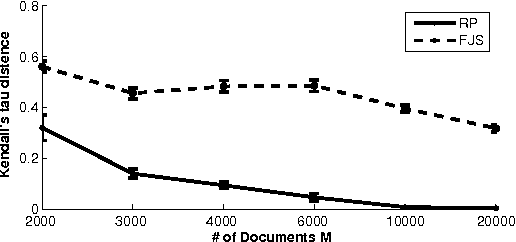
We propose a novel parameterized family of Mixed Membership Mallows Models (M4) to account for variability in pairwise comparisons generated by a heterogeneous population of noisy and inconsistent users. M4 models individual preferences as a user-specific probabilistic mixture of shared latent Mallows components. Our key algorithmic insight for estimation is to establish a statistical connection between M4 and topic models by viewing pairwise comparisons as words, and users as documents. This key insight leads us to explore Mallows components with a separable structure and leverage recent advances in separable topic discovery. While separability appears to be overly restrictive, we nevertheless show that it is an inevitable outcome of a relatively small number of latent Mallows components in a world of large number of items. We then develop an algorithm based on robust extreme-point identification of convex polygons to learn the reference rankings, and is provably consistent with polynomial sample complexity guarantees. We demonstrate that our new model is empirically competitive with the current state-of-the-art approaches in predicting real-world preferences.
A Topic Modeling Approach to Ranking
Jan 25, 2015
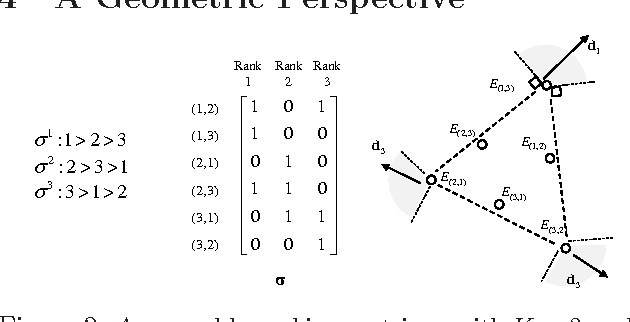
We propose a topic modeling approach to the prediction of preferences in pairwise comparisons. We develop a new generative model for pairwise comparisons that accounts for multiple shared latent rankings that are prevalent in a population of users. This new model also captures inconsistent user behavior in a natural way. We show how the estimation of latent rankings in the new generative model can be formally reduced to the estimation of topics in a statistically equivalent topic modeling problem. We leverage recent advances in the topic modeling literature to develop an algorithm that can learn shared latent rankings with provable consistency as well as sample and computational complexity guarantees. We demonstrate that the new approach is empirically competitive with the current state-of-the-art approaches in predicting preferences on some semi-synthetic and real world datasets.
Sensing-Aware Kernel SVM
Mar 13, 2014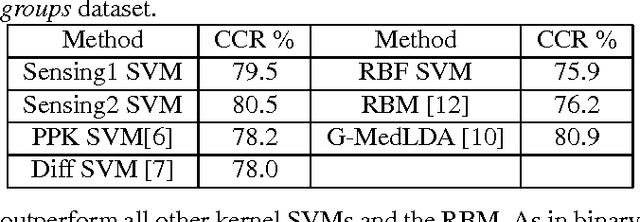
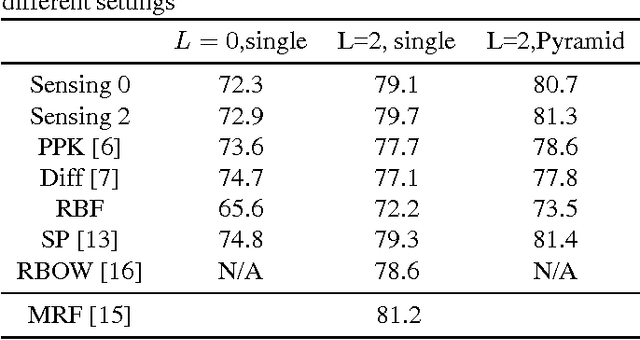
We propose a novel approach for designing kernels for support vector machines (SVMs) when the class label is linked to the observation through a latent state and the likelihood function of the observation given the state (the sensing model) is available. We show that the Bayes-optimum decision boundary is a hyperplane under a mapping defined by the likelihood function. Combining this with the maximum margin principle yields kernels for SVMs that leverage knowledge of the sensing model in an optimal way. We derive the optimum kernel for the bag-of-words (BoWs) sensing model and demonstrate its superior performance over other kernels in document and image classification tasks. These results indicate that such optimum sensing-aware kernel SVMs can match the performance of rather sophisticated state-of-the-art approaches.
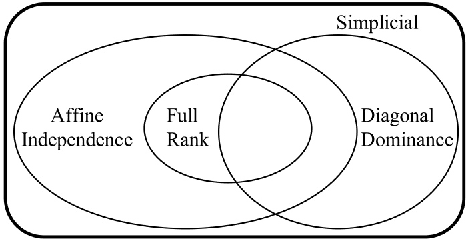
Necessary and Sufficient Conditions for Novel Word Detection in Separable Topic Models
Oct 30, 2013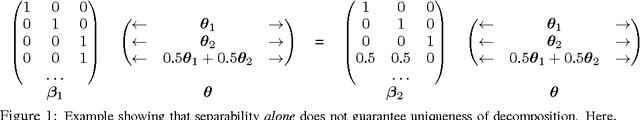

The simplicial condition and other stronger conditions that imply it have recently played a central role in developing polynomial time algorithms with provable asymptotic consistency and sample complexity guarantees for topic estimation in separable topic models. Of these algorithms, those that rely solely on the simplicial condition are impractical while the practical ones need stronger conditions. In this paper, we demonstrate, for the first time, that the simplicial condition is a fundamental, algorithm-independent, information-theoretic necessary condition for consistent separable topic estimation. Furthermore, under solely the simplicial condition, we present a practical quadratic-complexity algorithm based on random projections which consistently detects all novel words of all topics using only up to second-order empirical word moments. This algorithm is amenable to distributed implementation making it attractive for 'big-data' scenarios involving a network of large distributed databases.