 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Truncated Poisson Tensor Factorization for Massive Binary Tensors
Aug 18, 2015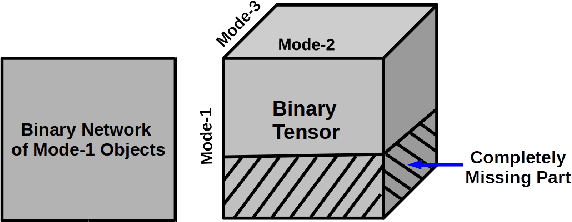

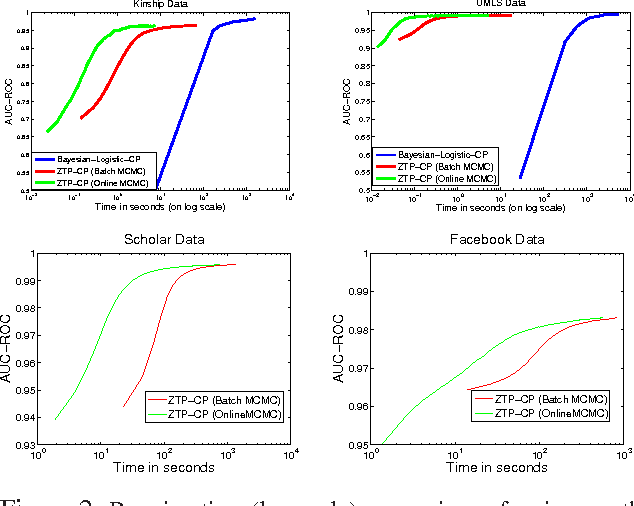
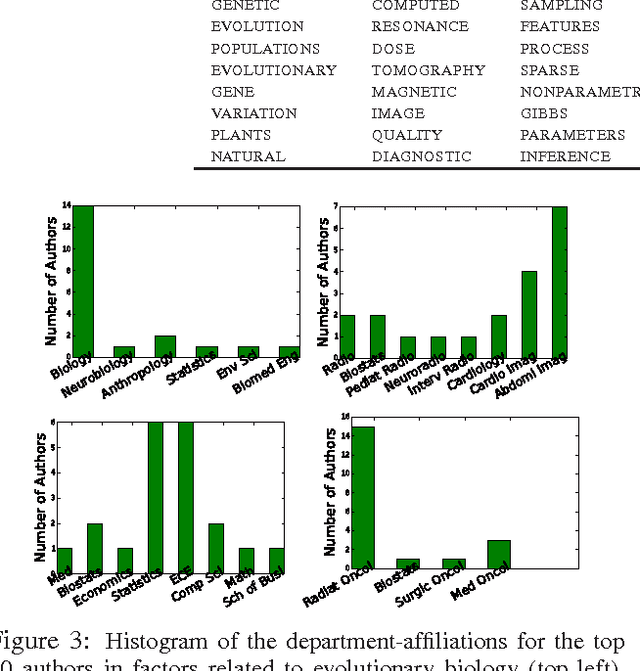
We present a scalable Bayesian model for low-rank factorization of massive tensors with binary observations. The proposed model has the following key properties: (1) in contrast to the models based on the logistic or probit likelihood, using a zero-truncated Poisson likelihood for binary data allows our model to scale up in the number of \emph{ones} in the tensor, which is especially appealing for massive but sparse binary tensors; (2) side-information in form of binary pairwise relationships (e.g., an adjacency network) between objects in any tensor mode can also be leveraged, which can be especially useful in "cold-start" settings; and (3) the model admits simple Bayesian inference via batch, as well as \emph{online} MCMC; the latter allows scaling up even for \emph{dense} binary data (i.e., when the number of ones in the tensor/network is also massive). In addition, non-negative factor matrices in our model provide easy interpretability, and the tensor rank can be inferred from the data. We evaluate our model on several large-scale real-world binary tensors, achieving excellent computational scalability, and also demonstrate its usefulness in leveraging side-information provided in form of mode-network(s).
Flexible Modeling of Latent Task Structures in Multitask Learning
Jun 27, 2012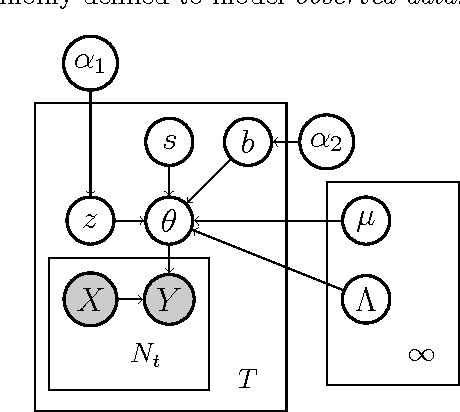
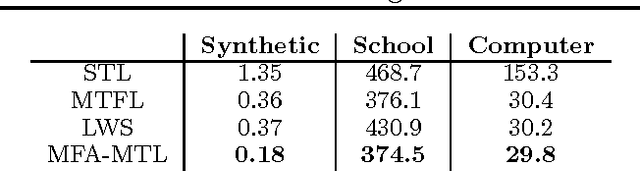
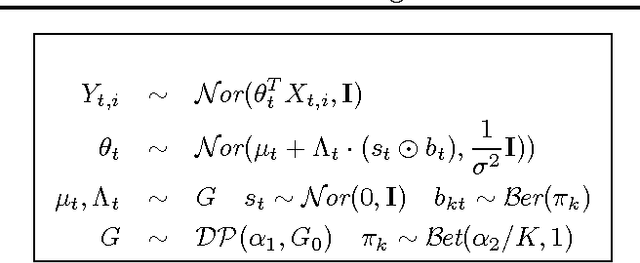
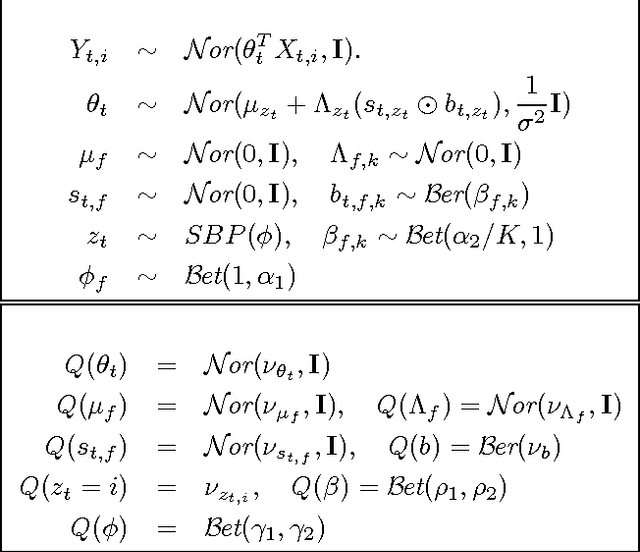
Multitask learning algorithms are typically designed assuming some fixed, a priori known latent structure shared by all the tasks. However, it is usually unclear what type of latent task structure is the most appropriate for a given multitask learning problem. Ideally, the "right" latent task structure should be learned in a data-driven manner. We present a flexible, nonparametric Bayesian model that posits a mixture of factor analyzers structure on the tasks. The nonparametric aspect makes the model expressive enough to subsume many existing models of latent task structures (e.g, mean-regularized tasks, clustered tasks, low-rank or linear/non-linear subspace assumption on tasks, etc.). Moreover, it can also learn more general task structures, addressing the shortcomings of such models. We present a variational inference algorithm for our model. Experimental results on synthetic and real-world datasets, on both regression and classification problems, demonstrate the effectiveness of the proposed method.
The Infinite Hierarchical Factor Regression Model
Aug 05, 2009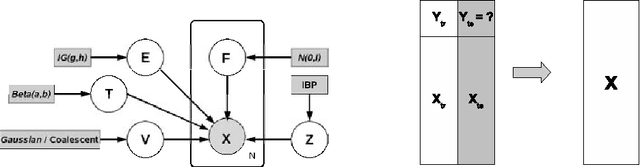
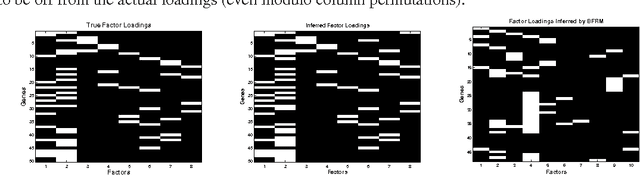
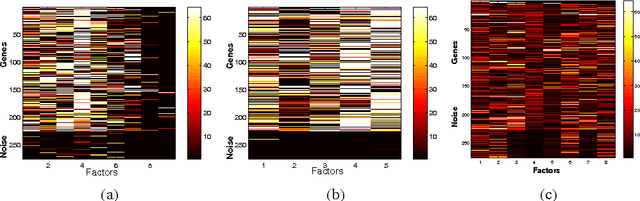
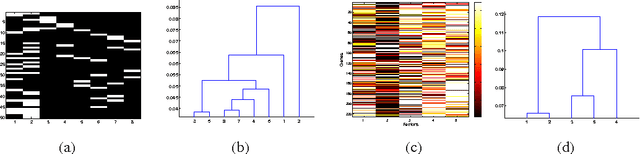
We propose a nonparametric Bayesian factor regression model that accounts for uncertainty in the number of factors, and the relationship between factors. To accomplish this, we propose a sparse variant of the Indian Buffet Process and couple this with a hierarchical model over factors, based on Kingman's coalescent. We apply this model to two problems (factor analysis and factor regression) in gene-expression data analysis.
Streamed Learning: One-Pass SVMs
Aug 05, 2009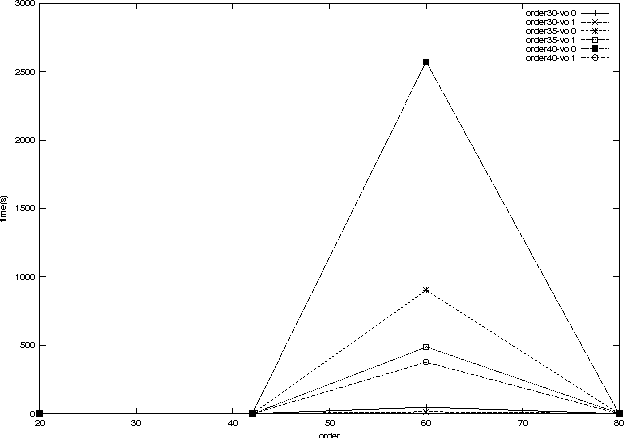
We present a streaming model for large-scale classification (in the context of $\ell_2$-SVM) by leveraging connections between learning and computational geometry. The streaming model imposes the constraint that only a single pass over the data is allowed. The $\ell_2$-SVM is known to have an equivalent formulation in terms of the minimum enclosing ball (MEB) problem, and an efficient algorithm based on the idea of \emph{core sets} exists (Core Vector Machine, CVM). CVM learns a $(1+\varepsilon)$-approximate MEB for a set of points and yields an approximate solution to corresponding SVM instance. However CVM works in batch mode requiring multiple passes over the data. This paper presents a single-pass SVM which is based on the minimum enclosing ball of streaming data. We show that the MEB updates for the streaming case can be easily adapted to learn the SVM weight vector in a way similar to using online stochastic gradient updates. Our algorithm performs polylogarithmic computation at each example, and requires very small and constant storage. Experimental results show that, even in such restrictive settings, we can learn efficiently in just one pass and get accuracies comparable to other state-of-the-art SVM solvers (batch and online). We also give an analysis of the algorithm, and discuss some open issues and possible extensions.