 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Global AI-Driven Cervical Cancer Screening
Jun 12, 2026The global elimination of cervical cancer is a key public health goal set by the World Health Organization (WHO), with screening programs reducing mortality by up to 80%. However, access to experts and biopsy services is limited in low- to middle-income countries (LMICs). Deep learning (DL)-based algorithms offer promising support for screening, but most existing approaches have been developed and validated on private datasets from single countries. We present the first DL-based approach to cervical cancer screening validated on data from multiple countries. Technically, we phrase the problem of detecting and classifying lesions in colposcopy images as a multi-task learning problem, in which we simultaneously perform image-level classification and lesion segmentation. Our model was trained on a private data set of acid stain colposcopy images with manually generated lesion segmentation masks and corresponding histopathological results, employing extensive data augmentation to address image variability. In an in-distribution validation with pathology results serving as ground truth, our algorithm outperformed medical experts (Balanced Accuracy: 0.68 vs 0.64) in CIN1- (Cervical intraepithelial neoplasia grade 1 or lower) versus CIN2+ (grade 2 or higher) classification. External validation on four colposcopy data sets from four countries featuring radical differences in prevalence and patient characteristics yielded superior performance of our method compared to baseline methods. Performance variability across countries was high with AUC values ranging from 0.54 - 0.80. Overall, algorithm performance varied with age, transformation zone (cervical area most prone to lesion development), presence of comorbidities and pathognomonic signs, with comorbidities having by far the largest negative effect. Future work should focus on improving model robustness and generalizability.
False Promises in Medical Imaging AI? Assessing Validity of Outperformance Claims
May 07, 2025Performance comparisons are fundamental in medical imaging Artificial Intelligence (AI) research, often driving claims of superiority based on relative improvements in common performance metrics. However, such claims frequently rely solely on empirical mean performance. In this paper, we investigate whether newly proposed methods genuinely outperform the state of the art by analyzing a representative cohort of medical imaging papers. We quantify the probability of false claims based on a Bayesian approach that leverages reported results alongside empirically estimated model congruence to estimate whether the relative ranking of methods is likely to have occurred by chance. According to our results, the majority (>80%) of papers claims outperformance when introducing a new method. Our analysis further revealed a high probability (>5%) of false outperformance claims in 86% of classification papers and 53% of segmentation papers. These findings highlight a critical flaw in current benchmarking practices: claims of outperformance in medical imaging AI are frequently unsubstantiated, posing a risk of misdirecting future research efforts.
Confidence intervals uncovered: Are we ready for real-world medical imaging AI?
Sep 27, 2024



Medical imaging is spearheading the AI transformation of healthcare. Performance reporting is key to determine which methods should be translated into clinical practice. Frequently, broad conclusions are simply derived from mean performance values. In this paper, we argue that this common practice is often a misleading simplification as it ignores performance variability. Our contribution is threefold. (1) Analyzing all MICCAI segmentation papers (n = 221) published in 2023, we first observe that more than 50% of papers do not assess performance variability at all. Moreover, only one (0.5%) paper reported confidence intervals (CIs) for model performance. (2) To address the reporting bottleneck, we show that the unreported standard deviation (SD) in segmentation papers can be approximated by a second-order polynomial function of the mean Dice similarity coefficient (DSC). Based on external validation data from 56 previous MICCAI challenges, we demonstrate that this approximation can accurately reconstruct the CI of a method using information provided in publications. (3) Finally, we reconstructed 95% CIs around the mean DSC of MICCAI 2023 segmentation papers. The median CI width was 0.03 which is three times larger than the median performance gap between the first and second ranked method. For more than 60% of papers, the mean performance of the second-ranked method was within the CI of the first-ranked method. We conclude that current publications typically do not provide sufficient evidence to support which models could potentially be translated into clinical practice.
Deployment of Image Analysis Algorithms under Prevalence Shifts
Mar 22, 2023



Domain gaps are among the most relevant roadblocks in the clinical translation of machine learning (ML)-based solutions for medical image analysis. While current research focuses on new training paradigms and network architectures, little attention is given to the specific effect of prevalence shifts on an algorithm deployed in practice. Such discrepancies between class frequencies in the data used for a method's development/validation and that in its deployment environment(s) are of great importance, for example in the context of artificial intelligence (AI) democratization, as disease prevalences may vary widely across time and location. Our contribution is twofold. First, we empirically demonstrate the potentially severe consequences of missing prevalence handling by analyzing (i) the extent of miscalibration, (ii) the deviation of the decision threshold from the optimum, and (iii) the ability of validation metrics to reflect neural network performance on the deployment population as a function of the discrepancy between development and deployment prevalence. Second, we propose a workflow for prevalence-aware image classification that uses estimated deployment prevalences to adjust a trained classifier to a new environment, without requiring additional annotated deployment data. Comprehensive experiments based on a diverse set of 30 medical classification tasks showcase the benefit of the proposed workflow in generating better classifier decisions and more reliable performance estimates compared to current practice.
Adversarial attacks on deep learning models for fatty liver disease classification by modification of ultrasound image reconstruction method
Sep 07, 2020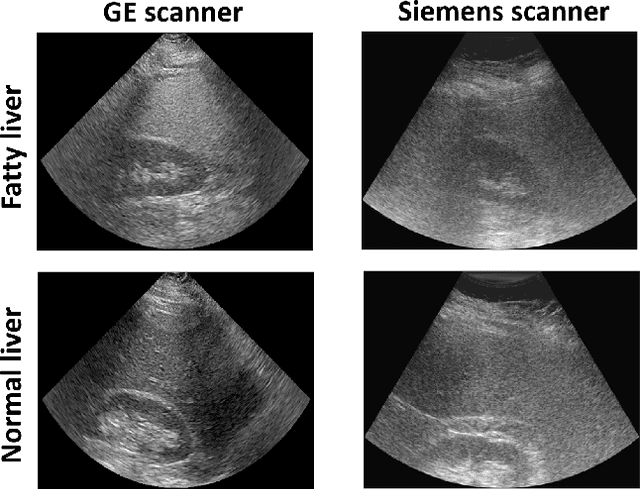
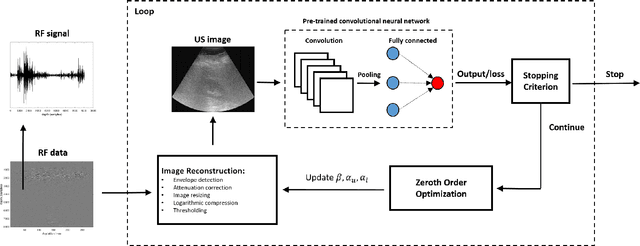
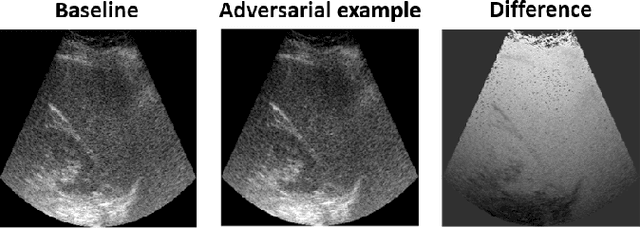
Convolutional neural networks (CNNs) have achieved remarkable success in medical image analysis tasks. In ultrasound (US) imaging, CNNs have been applied to object classification, image reconstruction and tissue characterization. However, CNNs can be vulnerable to adversarial attacks, even small perturbations applied to input data may significantly affect model performance and result in wrong output. In this work, we devise a novel adversarial attack, specific to ultrasound (US) imaging. US images are reconstructed based on radio-frequency signals. Since the appearance of US images depends on the applied image reconstruction method, we explore the possibility of fooling deep learning model by perturbing US B-mode image reconstruction method. We apply zeroth order optimization to find small perturbations of image reconstruction parameters, related to attenuation compensation and amplitude compression, which can result in wrong output. We illustrate our approach using a deep learning model developed for fatty liver disease diagnosis, where the proposed adversarial attack achieved success rate of 48%.