 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Audio Prototype EXplanations for Classification Tasks
May 11, 2026Explainable AI (XAI) has achieved remarkable success in image classification, yet the audio domain lacks equally mature solutions. Current methods apply vision-based attribution techniques to spectrograms, overlooking fundamental differences between visual and acoustic signals. While prototype reasoning is promising, acoustic similarity remains multidimensional. We introduce APEX (Audio Prototype EXplanations), a post-hoc framework for interpreting pre-trained audio classifiers. Crucially, APEX requires no fine-tuning of the original backbone and strictly preserves output invariance. APEX disentangles explanations into four perspectives: Square-based prototypes to localize transient events, Time-based for temporal patterns, Frequency-based highlighting spectral bands, and Time-Frequency-based integrating both. This yields intuitive, example-based explanations that respect acoustic properties, providing greater semantic clarity than standard gradient-based methods.
SMAL-pets: SMAL Based Avatars of Pets from Single Image
Mar 17, 2026Creating high-fidelity, animatable 3D dog avatars remains a formidable challenge in computer vision. Unlike human digital doubles, animal reconstruction faces a critical shortage of large-scale, annotated datasets for specialized applications. Furthermore, the immense morphological diversity across species, breeds, and crosses, which varies significantly in size, proportions, and features, complicates the generalization of existing models. Current reconstruction methods often struggle to capture realistic fur textures. Additionally, ensuring these avatars are fully editable and capable of performing complex, naturalistic movements typically necessitates labor-intensive manual mesh manipulation and expert rigging. This paper introduces SMAL-pets, a comprehensive framework that generates high-quality, editable animal avatars from a single input image. Our approach bridges the gap between reconstruction and generative modeling by leveraging a hybrid architecture. Our method integrates 3D Gaussian Splatting with the SMAL parametric model to provide a representation that is both visually high-fidelity and anatomically grounded. We introduce a multimodal editing suite that enables users to refine the avatar's appearance and execute complex animations through direct textual prompts. By allowing users to control both the aesthetic and behavioral aspects of the model via natural language, SMAL-pets provides a flexible, robust tool for animation and virtual reality.
XSPLAIN: XAI-enabling Splat-based Prototype Learning for Attribute-aware INterpretability
Feb 10, 20263D Gaussian Splatting (3DGS) has rapidly become a standard for high-fidelity 3D reconstruction, yet its adoption in multiple critical domains is hindered by the lack of interpretability of the generation models as well as classification of the Splats. While explainability methods exist for other 3D representations, like point clouds, they typically rely on ambiguous saliency maps that fail to capture the volumetric coherence of Gaussian primitives. We introduce XSPLAIN, the first ante-hoc, prototype-based interpretability framework designed specifically for 3DGS classification. Our approach leverages a voxel-aggregated PointNet backbone and a novel, invertible orthogonal transformation that disentangles feature channels for interpretability while strictly preserving the original decision boundaries. Explanations are grounded in representative training examples, enabling intuitive ``this looks like that'' reasoning without any degradation in classification performance. A rigorous user study (N=51) demonstrates a decisive preference for our approach: participants selected XSPLAIN explanations 48.4\% of the time as the best, significantly outperforming baselines $(p<0.001)$, showing that XSPLAIN provides transparency and user trust. The source code for this work is available at: https://github.com/Solvro/ml-splat-xai
DIAMOND: Directed Inference for Artifact Mitigation in Flow Matching Models
Jan 31, 2026Despite impressive results from recent text-to-image models like FLUX, visual and anatomical artifacts remain a significant hurdle for practical and professional use. Existing methods for artifact reduction, typically work in a post-hoc manner, consequently failing to intervene effectively during the core image formation process. Notably, current techniques require problematic and invasive modifications to the model weights, or depend on a computationally expensive and time-consuming process of regional refinement. To address these limitations, we propose DIAMOND, a training-free method that applies trajectory correction to mitigate artifacts during inference. By reconstructing an estimate of the clean sample at every step of the generative trajectory, DIAMOND actively steers the generation process away from latent states that lead to artifacts. Furthermore, we extend the proposed method to standard Diffusion Models, demonstrating that DIAMOND provides a robust, zero-shot path to high-fidelity, artifact-free image synthesis without the need for additional training or weight modifications in modern generative architectures. Code is available at https://gmum.github.io/DIAMOND/
HuSc3D: Human Sculpture dataset for 3D object reconstruction
Jun 09, 2025



3D scene reconstruction from 2D images is one of the most important tasks in computer graphics. Unfortunately, existing datasets and benchmarks concentrate on idealized synthetic or meticulously captured realistic data. Such benchmarks fail to convey the inherent complexities encountered in newly acquired real-world scenes. In such scenes especially those acquired outside, the background is often dynamic, and by popular usage of cell phone cameras, there might be discrepancies in, e.g., white balance. To address this gap, we present HuSc3D, a novel dataset specifically designed for rigorous benchmarking of 3D reconstruction models under realistic acquisition challenges. Our dataset uniquely features six highly detailed, fully white sculptures characterized by intricate perforations and minimal textural and color variation. Furthermore, the number of images per scene varies significantly, introducing the additional challenge of limited training data for some instances alongside scenes with a standard number of views. By evaluating popular 3D reconstruction methods on this diverse dataset, we demonstrate the distinctiveness of HuSc3D in effectively differentiating model performance, particularly highlighting the sensitivity of methods to fine geometric details, color ambiguity, and varying data availability--limitations often masked by more conventional datasets.
CLIPGaussian: Universal and Multimodal Style Transfer Based on Gaussian Splatting
May 28, 2025
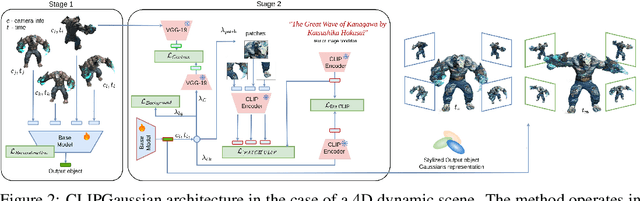


Gaussian Splatting (GS) has recently emerged as an efficient representation for rendering 3D scenes from 2D images and has been extended to images, videos, and dynamic 4D content. However, applying style transfer to GS-based representations, especially beyond simple color changes, remains challenging. In this work, we introduce CLIPGaussians, the first unified style transfer framework that supports text- and image-guided stylization across multiple modalities: 2D images, videos, 3D objects, and 4D scenes. Our method operates directly on Gaussian primitives and integrates into existing GS pipelines as a plug-in module, without requiring large generative models or retraining from scratch. CLIPGaussians approach enables joint optimization of color and geometry in 3D and 4D settings, and achieves temporal coherence in videos, while preserving a model size. We demonstrate superior style fidelity and consistency across all tasks, validating CLIPGaussians as a universal and efficient solution for multimodal style transfer.
EPIC: Explanation of Pretrained Image Classification Networks via Prototype
May 19, 2025



Explainable AI (XAI) methods generally fall into two categories. Post-hoc approaches generate explanations for pre-trained models and are compatible with various neural network architectures. These methods often use feature importance visualizations, such as saliency maps, to indicate which input regions influenced the model's prediction. Unfortunately, they typically offer a coarse understanding of the model's decision-making process. In contrast, ante-hoc (inherently explainable) methods rely on specially designed model architectures trained from scratch. A notable subclass of these methods provides explanations through prototypes, representative patches extracted from the training data. However, prototype-based approaches have limitations: they require dedicated architectures, involve specialized training procedures, and perform well only on specific datasets. In this work, we propose EPIC (Explanation of Pretrained Image Classification), a novel approach that bridges the gap between these two paradigms. Like post-hoc methods, EPIC operates on pre-trained models without architectural modifications. Simultaneously, it delivers intuitive, prototype-based explanations inspired by ante-hoc techniques. To the best of our knowledge, EPIC is the first post-hoc method capable of fully replicating the core explanatory power of inherently interpretable models. We evaluate EPIC on benchmark datasets commonly used in prototype-based explanations, such as CUB-200-2011 and Stanford Cars, alongside large-scale datasets like ImageNet, typically employed by post-hoc methods. EPIC uses prototypes to explain model decisions, providing a flexible and easy-to-understand tool for creating clear, high-quality explanations.
REdiSplats: Ray Tracing for Editable Gaussian Splatting
Mar 15, 2025



Gaussian Splatting (GS) has become one of the most important neural rendering algorithms. GS represents 3D scenes using Gaussian components with trainable color and opacity. This representation achieves high-quality renderings with fast inference. Regrettably, it is challenging to integrate such a solution with varying light conditions, including shadows and light reflections, manual adjustments, and a physical engine. Recently, a few approaches have appeared that incorporate ray-tracing or mesh primitives into GS to address some of these caveats. However, no such solution can simultaneously solve all the existing limitations of the classical GS. Consequently, we introduce REdiSplats, which employs ray tracing and a mesh-based representation of flat 3D Gaussians. In practice, we model the scene using flat Gaussian distributions parameterized by the mesh. We can leverage fast ray tracing and control Gaussian modification by adjusting the mesh vertices. Moreover, REdiSplats allows modeling of light conditions, manual adjustments, and physical simulation. Furthermore, we can render our models using 3D tools such as Blender or Nvdiffrast, which opens the possibility of integrating them with all existing 3D graphics techniques dedicated to mesh representations.
MiraGe: Editable 2D Images using Gaussian Splatting
Oct 02, 2024



Implicit Neural Representations (INRs) approximate discrete data through continuous functions and are commonly used for encoding 2D images. Traditional image-based INRs employ neural networks to map pixel coordinates to RGB values, capturing shapes, colors, and textures within the network's weights. Recently, GaussianImage has been proposed as an alternative, using Gaussian functions instead of neural networks to achieve comparable quality and compression. Such a solution obtains a quality and compression ratio similar to classical INR models but does not allow image modification. In contrast, our work introduces a novel method, MiraGe, which uses mirror reflections to perceive 2D images in 3D space and employs flat-controlled Gaussians for precise 2D image editing. Our approach improves the rendering quality and allows realistic image modifications, including human-inspired perception of photos in the 3D world. Thanks to modeling images in 3D space, we obtain the illusion of 3D-based modification in 2D images. We also show that our Gaussian representation can be easily combined with a physics engine to produce physics-based modification of 2D images. Consequently, MiraGe allows for better quality than the standard approach and natural modification of 2D images.
GASP: Gaussian Splatting for Physic-Based Simulations
Sep 09, 2024Physics simulation is paramount for modeling and utilization of 3D scenes in various real-world applications. However, its integration with state-of-the-art 3D scene rendering techniques such as Gaussian Splatting (GS) remains challenging. Existing models use additional meshing mechanisms, including triangle or tetrahedron meshing, marching cubes, or cage meshes. As an alternative, we can modify the physics grounded Newtonian dynamics to align with 3D Gaussian components. Current models take the first-order approximation of a deformation map, which locally approximates the dynamics by linear transformations. In contrast, our Gaussian Splatting for Physics-Based Simulations (GASP) model uses such a map (without any modifications) and flat Gaussian distributions, which are parameterized by three points (mesh faces). Subsequently, each 3D point (mesh face node) is treated as a discrete entity within a 3D space. Consequently, the problem of modeling Gaussian components is reduced to working with 3D points. Additionally, the information on mesh faces can be used to incorporate further properties into the physics model, facilitating the use of triangles. Resulting solution can be integrated into any physics engine that can be treated as a black box. As demonstrated in our studies, the proposed model exhibits superior performance on a diverse range of benchmark datasets designed for 3D object rendering.