 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Audio Prototype EXplanations for Classification Tasks
May 11, 2026Explainable AI (XAI) has achieved remarkable success in image classification, yet the audio domain lacks equally mature solutions. Current methods apply vision-based attribution techniques to spectrograms, overlooking fundamental differences between visual and acoustic signals. While prototype reasoning is promising, acoustic similarity remains multidimensional. We introduce APEX (Audio Prototype EXplanations), a post-hoc framework for interpreting pre-trained audio classifiers. Crucially, APEX requires no fine-tuning of the original backbone and strictly preserves output invariance. APEX disentangles explanations into four perspectives: Square-based prototypes to localize transient events, Time-based for temporal patterns, Frequency-based highlighting spectral bands, and Time-Frequency-based integrating both. This yields intuitive, example-based explanations that respect acoustic properties, providing greater semantic clarity than standard gradient-based methods.
CLIPGaussian: Universal and Multimodal Style Transfer Based on Gaussian Splatting
May 28, 2025
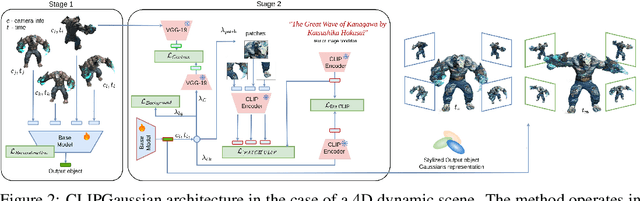


Gaussian Splatting (GS) has recently emerged as an efficient representation for rendering 3D scenes from 2D images and has been extended to images, videos, and dynamic 4D content. However, applying style transfer to GS-based representations, especially beyond simple color changes, remains challenging. In this work, we introduce CLIPGaussians, the first unified style transfer framework that supports text- and image-guided stylization across multiple modalities: 2D images, videos, 3D objects, and 4D scenes. Our method operates directly on Gaussian primitives and integrates into existing GS pipelines as a plug-in module, without requiring large generative models or retraining from scratch. CLIPGaussians approach enables joint optimization of color and geometry in 3D and 4D settings, and achieves temporal coherence in videos, while preserving a model size. We demonstrate superior style fidelity and consistency across all tasks, validating CLIPGaussians as a universal and efficient solution for multimodal style transfer.
VeGaS: Video Gaussian Splatting
Nov 17, 2024Implicit Neural Representations (INRs) employ neural networks to approximate discrete data as continuous functions. In the context of video data, such models can be utilized to transform the coordinates of pixel locations along with frame occurrence times (or indices) into RGB color values. Although INRs facilitate effective compression, they are unsuitable for editing purposes. One potential solution is to use a 3D Gaussian Splatting (3DGS) based model, such as the Video Gaussian Representation (VGR), which is capable of encoding video as a multitude of 3D Gaussians and is applicable for numerous video processing operations, including editing. Nevertheless, in this case, the capacity for modification is constrained to a limited set of basic transformations. To address this issue, we introduce the Video Gaussian Splatting (VeGaS) model, which enables realistic modifications of video data. To construct VeGaS, we propose a novel family of Folded-Gaussian distributions designed to capture nonlinear dynamics in a video stream and model consecutive frames by 2D Gaussians obtained as respective conditional distributions. Our experiments demonstrate that VeGaS outperforms state-of-the-art solutions in frame reconstruction tasks and allows realistic modifications of video data. The code is available at: https://github.com/gmum/VeGaS.