 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Convolutional Neural Networks with Self-Supervision
Jan 10, 2020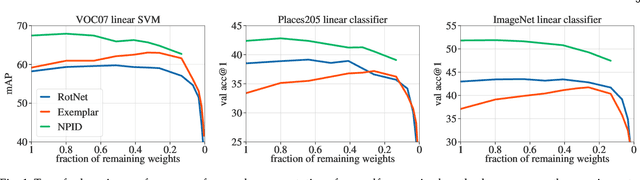
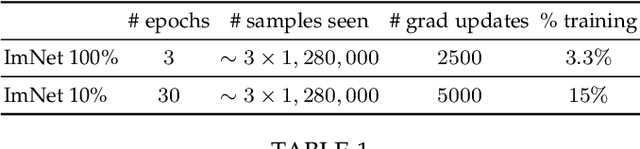
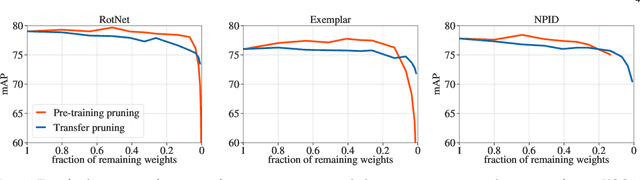
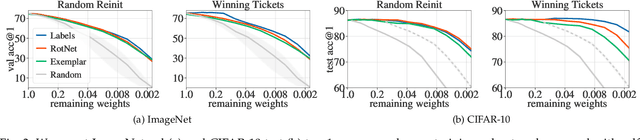
Convolutional neural networks trained without supervision come close to matching performance with supervised pre-training, but sometimes at the cost of an even higher number of parameters. Extracting subnetworks from these large unsupervised convnets with preserved performance is of particular interest to make them less computationally intensive. Typical pruning methods operate during training on a task while trying to maintain the performance of the pruned network on the same task. However, in self-supervised feature learning, the training objective is agnostic on the representation transferability to downstream tasks. Thus, preserving performance for this objective does not ensure that the pruned subnetwork remains effective for solving downstream tasks. In this work, we investigate the use of standard pruning methods, developed primarily for supervised learning, for networks trained without labels (i.e. on self-supervised tasks). We show that pruned masks obtained with or without labels reach comparable performance when re-trained on labels, suggesting that pruning operates similarly for self-supervised and supervised learning. Interestingly, we also find that pruning preserves the transfer performance of self-supervised subnetwork representations.
Updating Pre-trained Word Vectors and Text Classifiers using Monolingual Alignment
Oct 15, 2019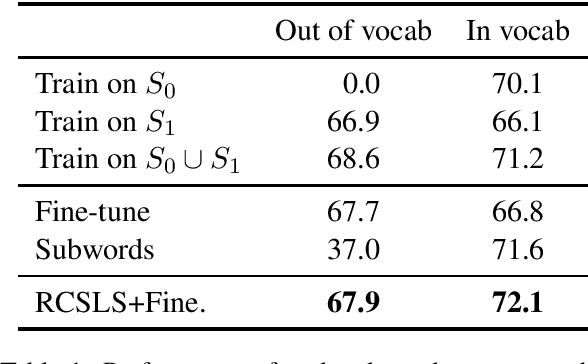
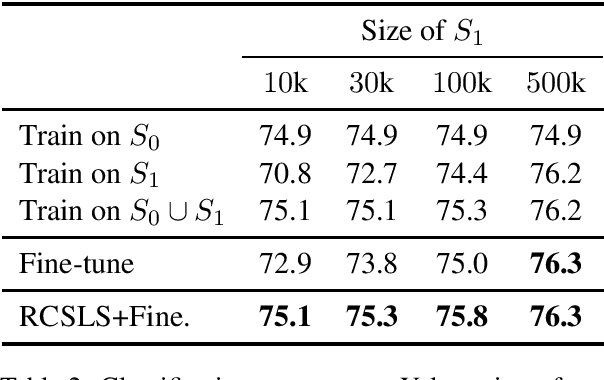
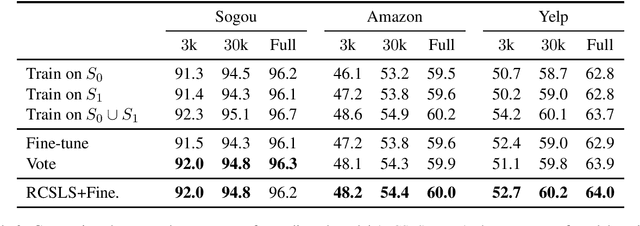
In this paper, we focus on the problem of adapting word vector-based models to new textual data. Given a model pre-trained on large reference data, how can we adapt it to a smaller piece of data with a slightly different language distribution? We frame the adaptation problem as a monolingual word vector alignment problem, and simply average models after alignment. We align vectors using the RCSLS criterion. Our formulation results in a simple and efficient algorithm that allows adapting general-purpose models to changing word distributions. In our evaluation, we consider applications to word embedding and text classification models. We show that the proposed approach yields good performance in all setups and outperforms a baseline consisting in fine-tuning the model on new data.
Misspelling Oblivious Word Embeddings
May 23, 2019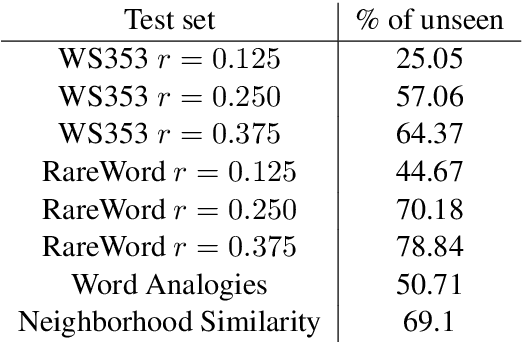
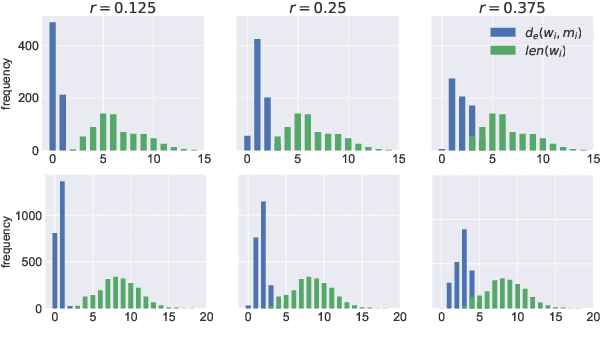
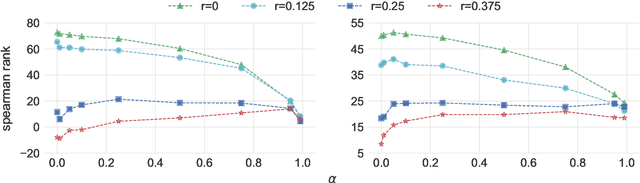
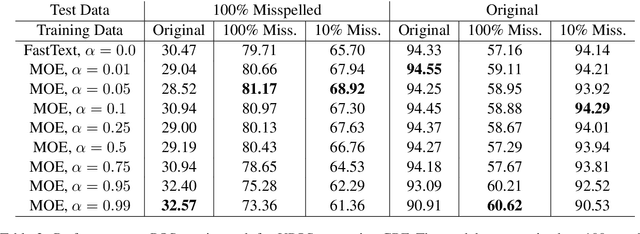
In this paper we present a method to learn word embeddings that are resilient to misspellings. Existing word embeddings have limited applicability to malformed texts, which contain a non-negligible amount of out-of-vocabulary words. We propose a method combining FastText with subwords and a supervised task of learning misspelling patterns. In our method, misspellings of each word are embedded close to their correct variants. We train these embeddings on a new dataset we are releasing publicly. Finally, we experimentally show the advantages of this approach on both intrinsic and extrinsic NLP tasks using public test sets.
Adaptive Attention Span in Transformers
May 19, 2019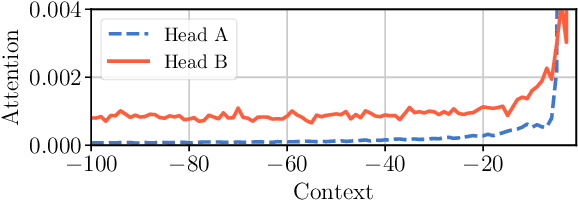
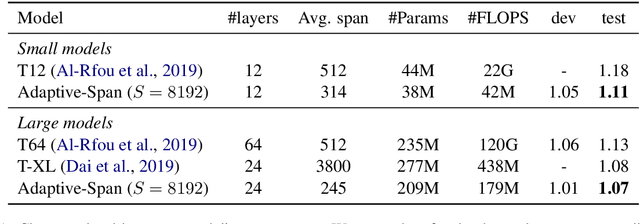
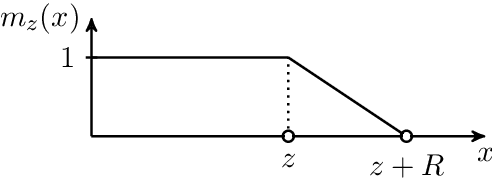
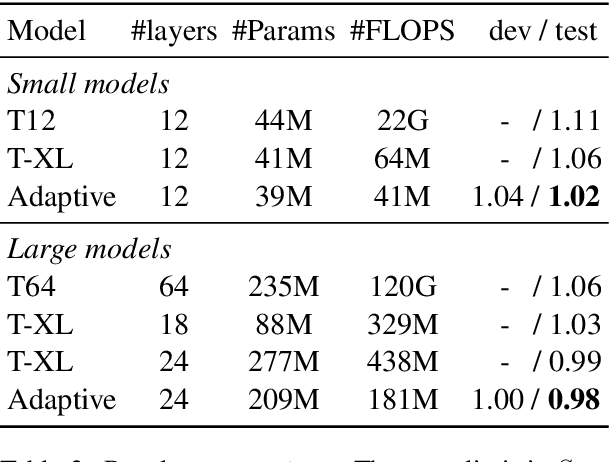
We propose a novel self-attention mechanism that can learn its optimal attention span. This allows us to extend significantly the maximum context size used in Transformer, while maintaining control over their memory footprint and computational time. We show the effectiveness of our approach on the task of character level language modeling, where we achieve state-of-the-art performances on text8 and enwiki8 by using a maximum context of 8k characters.
Leveraging Large-Scale Uncurated Data for Unsupervised Pre-training of Visual Features
May 03, 2019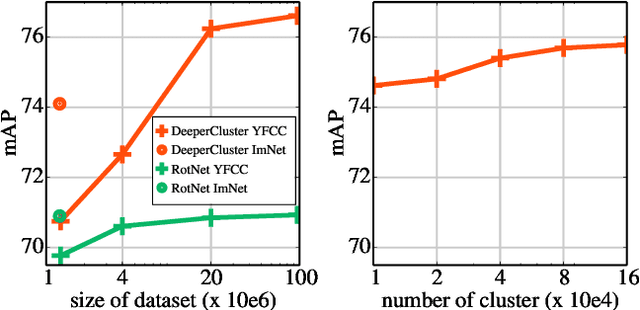

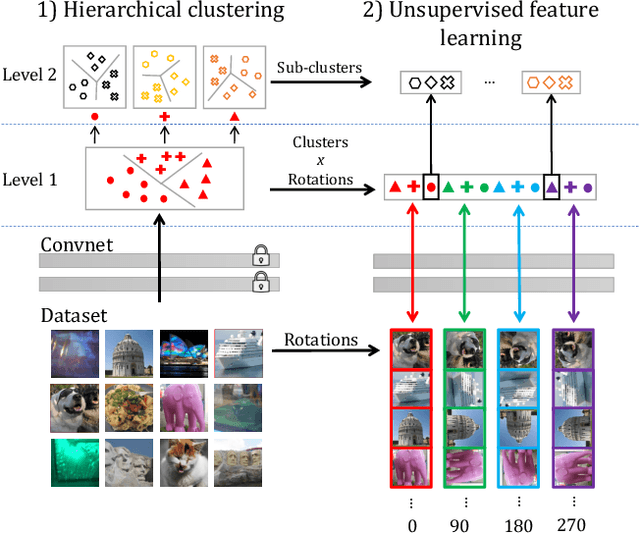
Pre-training general-purpose visual features with convolutional neural networks without relying on annotations is a challenging and important task. Most recent efforts in unsupervised feature learning have focused on either small or highly curated datasets like ImageNet, whereas using uncurated raw datasets was found to decrease the feature quality when evaluated on a transfer task. Our goal is to bridge the performance gap between unsupervised methods trained on curated data, which are costly to obtain, and massive raw datasets that are easily available. To that effect, we propose a new unsupervised approach which leverages self-supervision and clustering to capture complementary statistics from large-scale data. We validate our approach on 96 million images from YFCC100M, achieving state-of-the-art results among unsupervised methods on standard benchmarks, which confirms the potential of unsupervised learning when only uncurated data are available. We also show that pre-training a supervised VGG-16 with our method achieves 74.6% top-1 accuracy on the validation set of ImageNet classification, which is an improvement of +0.7% over the same network trained from scratch.
Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion
Sep 05, 2018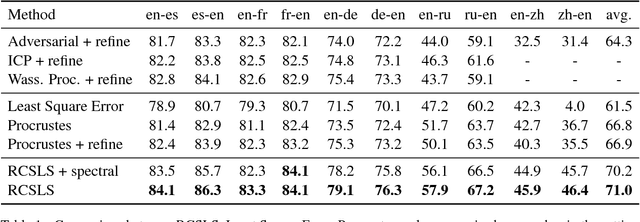
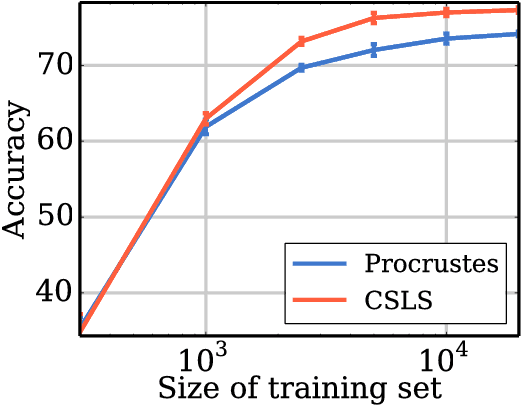
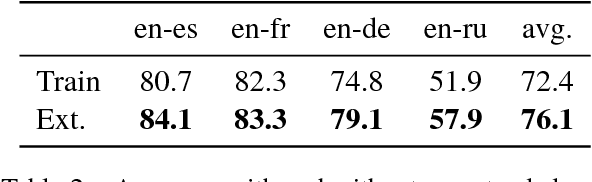
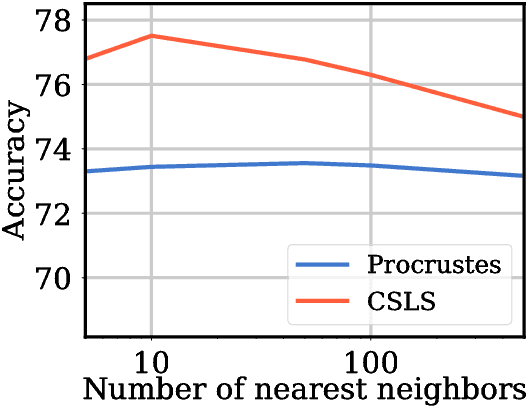
Continuous word representations learned separately on distinct languages can be aligned so that their words become comparable in a common space. Existing works typically solve a least-square regression problem to learn a rotation aligning a small bilingual lexicon, and use a retrieval criterion for inference. In this paper, we propose an unified formulation that directly optimizes a retrieval criterion in an end-to-end fashion. Our experiments on standard benchmarks show that our approach outperforms the state of the art on word translation, with the biggest improvements observed for distant language pairs such as English-Chinese.
Deep Clustering for Unsupervised Learning of Visual Features
Jul 15, 2018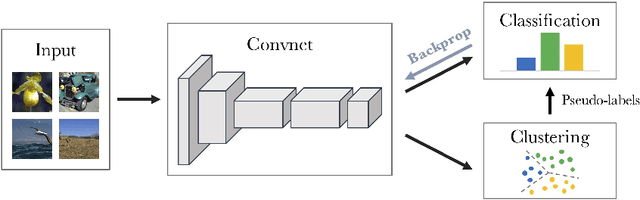
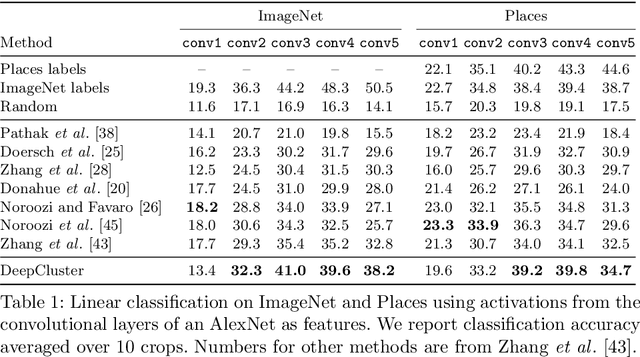
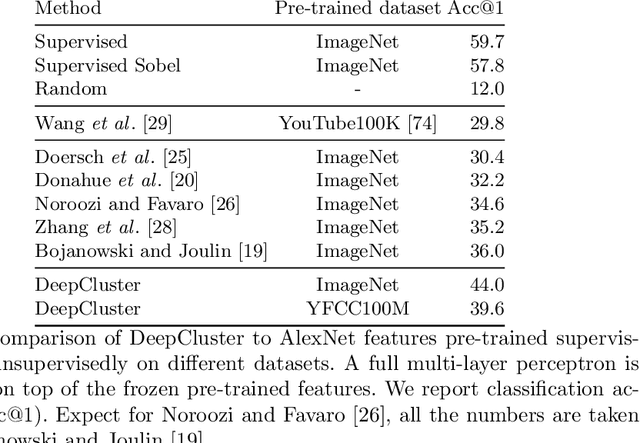
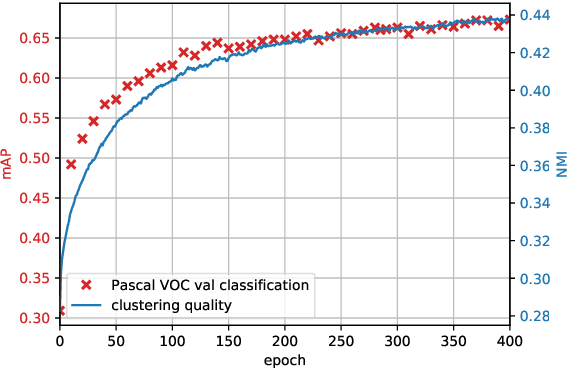
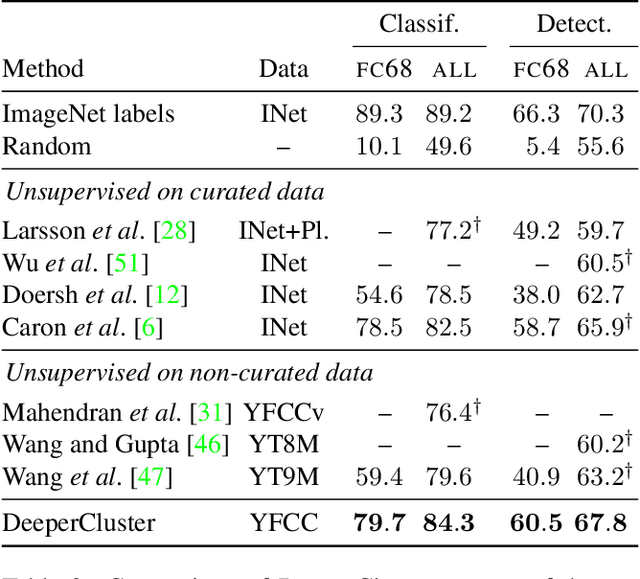
Clustering is a class of unsupervised learning methods that has been extensively applied and studied in computer vision. Little work has been done to adapt it to the end-to-end training of visual features on large scale datasets. In this work, we present DeepCluster, a clustering method that jointly learns the parameters of a neural network and the cluster assignments of the resulting features. DeepCluster iteratively groups the features with a standard clustering algorithm, k-means, and uses the subsequent assignments as supervision to update the weights of the network. We apply DeepCluster to the unsupervised training of convolutional neural networks on large datasets like ImageNet and YFCC100M. The resulting model outperforms the current state of the art by a significant margin on all the standard benchmarks.
Colorless green recurrent networks dream hierarchically
Mar 29, 2018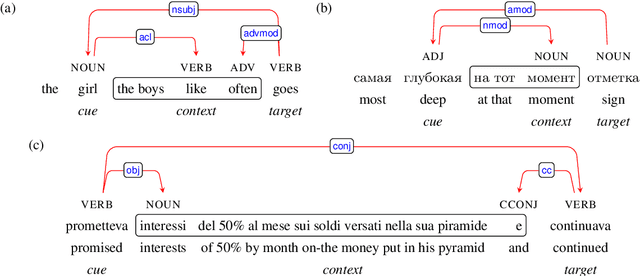
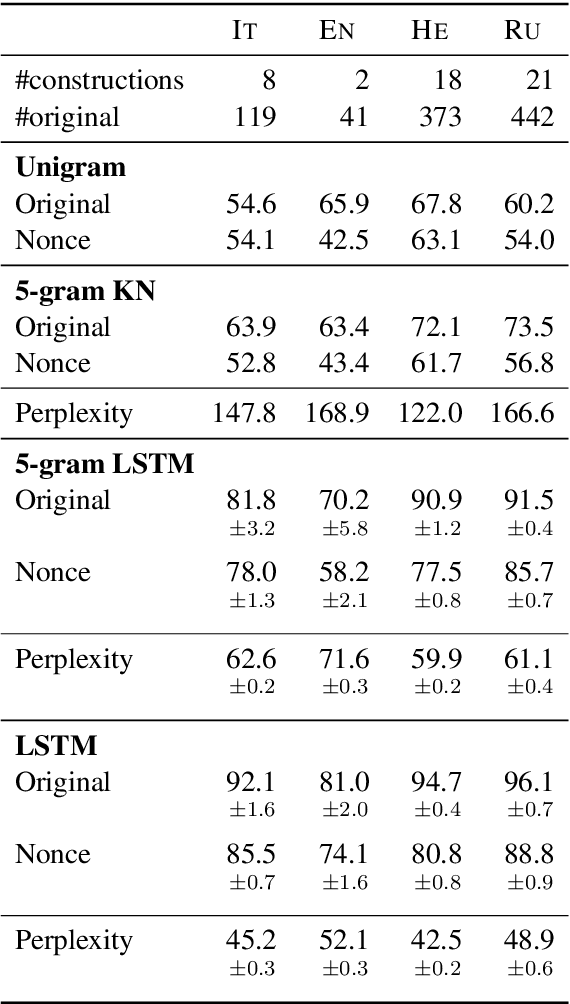
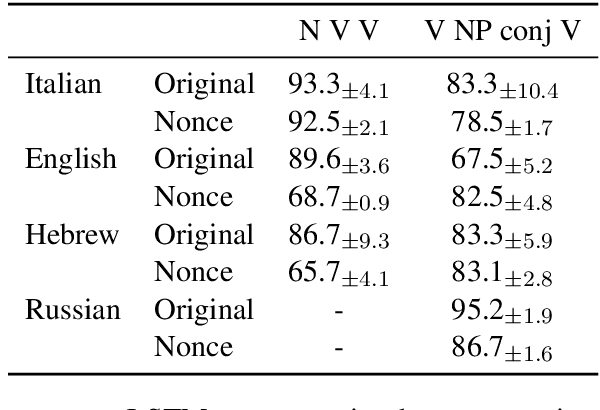
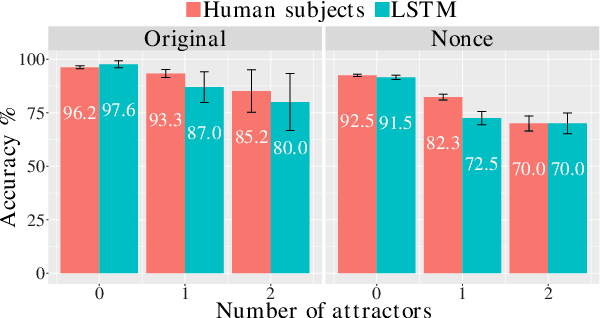
Recurrent neural networks (RNNs) have achieved impressive results in a variety of linguistic processing tasks, suggesting that they can induce non-trivial properties of language. We investigate here to what extent RNNs learn to track abstract hierarchical syntactic structure. We test whether RNNs trained with a generic language modeling objective in four languages (Italian, English, Hebrew, Russian) can predict long-distance number agreement in various constructions. We include in our evaluation nonsensical sentences where RNNs cannot rely on semantic or lexical cues ("The colorless green ideas I ate with the chair sleep furiously"), and, for Italian, we compare model performance to human intuitions. Our language-model-trained RNNs make reliable predictions about long-distance agreement, and do not lag much behind human performance. We thus bring support to the hypothesis that RNNs are not just shallow-pattern extractors, but they also acquire deeper grammatical competence.
Learning Word Vectors for 157 Languages
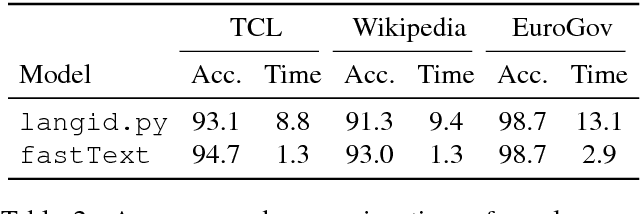
Mar 28, 2018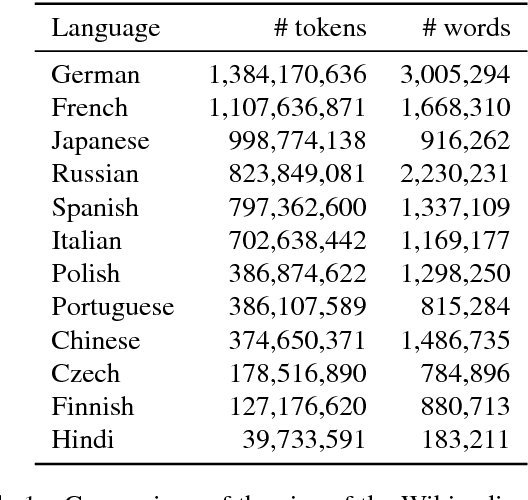
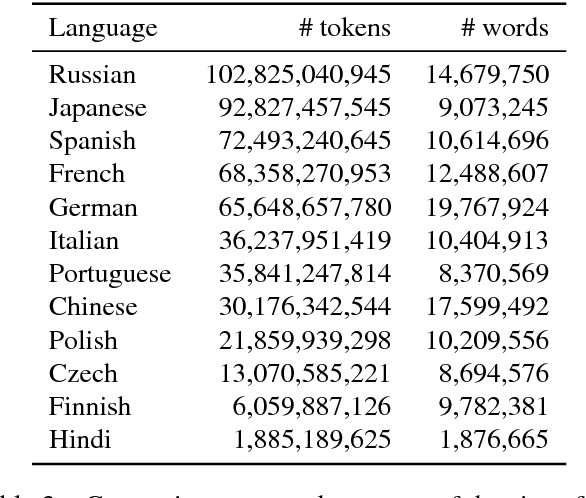
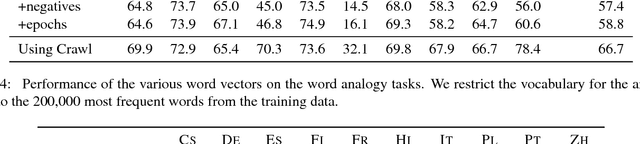
Distributed word representations, or word vectors, have recently been applied to many tasks in natural language processing, leading to state-of-the-art performance. A key ingredient to the successful application of these representations is to train them on very large corpora, and use these pre-trained models in downstream tasks. In this paper, we describe how we trained such high quality word representations for 157 languages. We used two sources of data to train these models: the free online encyclopedia Wikipedia and data from the common crawl project. We also introduce three new word analogy datasets to evaluate these word vectors, for French, Hindi and Polish. Finally, we evaluate our pre-trained word vectors on 10 languages for which evaluation datasets exists, showing very strong performance compared to previous models.
Advances in Pre-Training Distributed Word Representations
Dec 26, 2017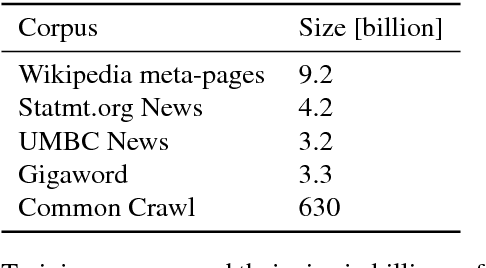

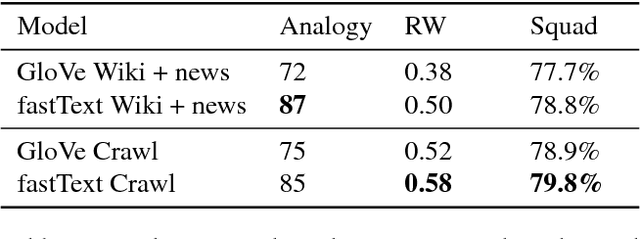
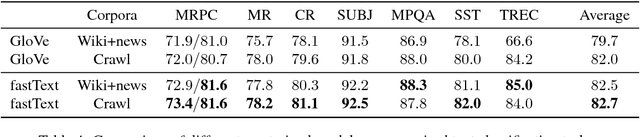
Many Natural Language Processing applications nowadays rely on pre-trained word representations estimated from large text corpora such as news collections, Wikipedia and Web Crawl. In this paper, we show how to train high-quality word vector representations by using a combination of known tricks that are however rarely used together. The main result of our work is the new set of publicly available pre-trained models that outperform the current state of the art by a large margin on a number of tasks.