 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnytime PSRO for Two-Player Zero-Sum Games
Jan 28, 2022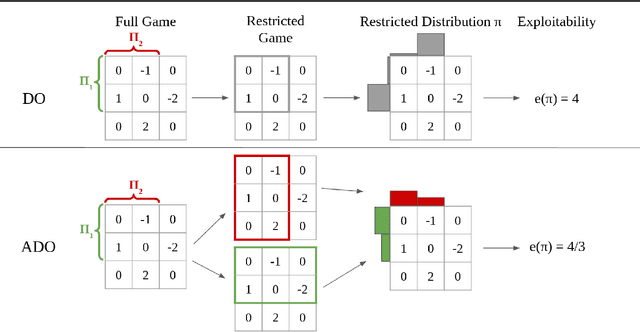

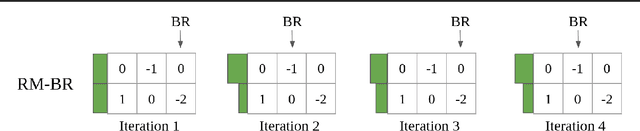

Policy space response oracles (PSRO) is a multi-agent reinforcement learning algorithm that has achieved state-of-the-art performance in very large two-player zero-sum games. PSRO is based on the tabular double oracle (DO) method, an algorithm that is guaranteed to converge to a Nash equilibrium, but may increase exploitability from one iteration to the next. We propose anytime double oracle (ADO), a tabular double oracle algorithm for 2-player zero-sum games that is guaranteed to converge to a Nash equilibrium while decreasing exploitability from one iteration to the next. Unlike DO, in which the restricted distribution is based on the restricted game formed by each player's strategy sets, ADO finds the restricted distribution for each player that minimizes its exploitability against any policy in the full, unrestricted game. We also propose a method of finding this restricted distribution via a no-regret algorithm updated against best responses, called RM-BR DO. Finally, we propose anytime PSRO (APSRO), a version of ADO that calculates best responses via reinforcement learning. In experiments on Leduc poker and random normal form games, we show that our methods achieve far lower exploitability than DO and PSRO and decrease exploitability monotonically.
Rxn Hypergraph: a Hypergraph Attention Model for Chemical Reaction Representation
Jan 02, 2022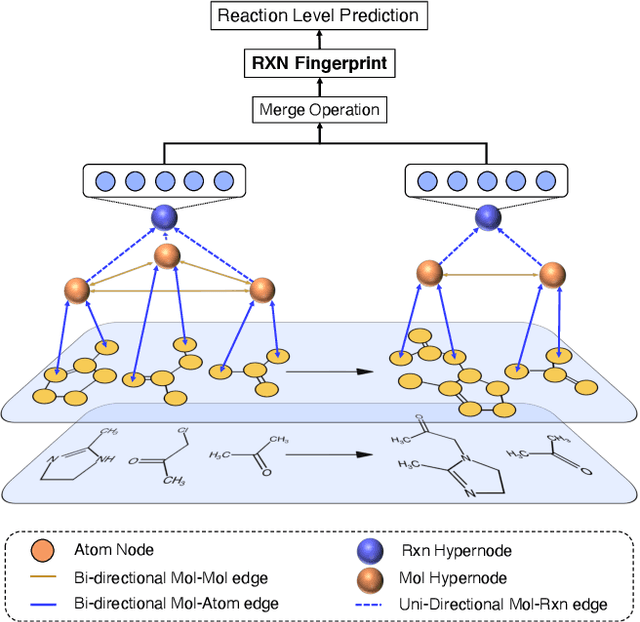
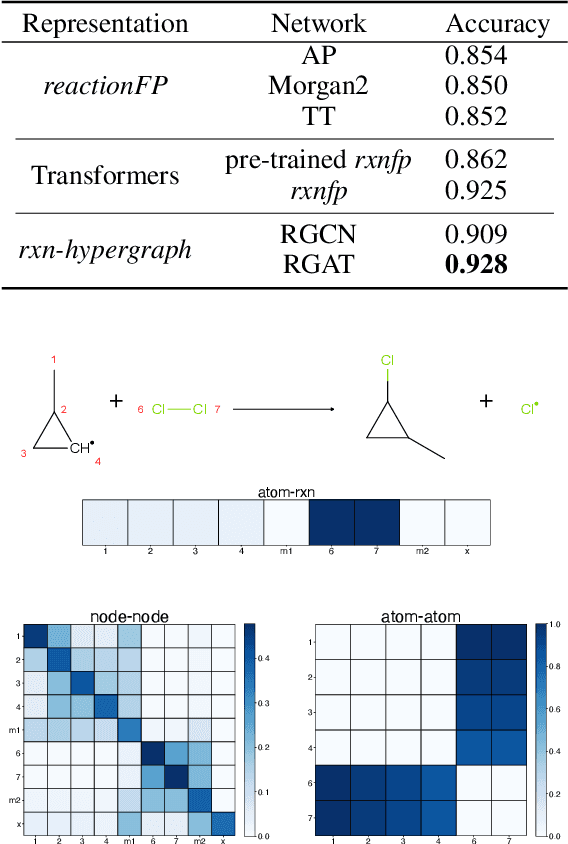
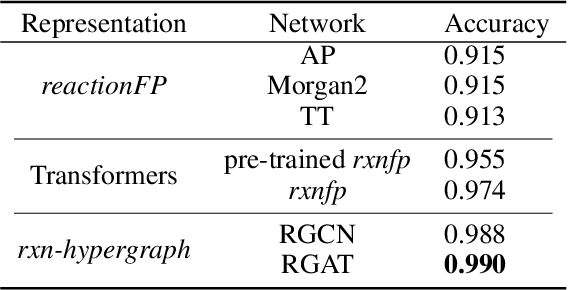
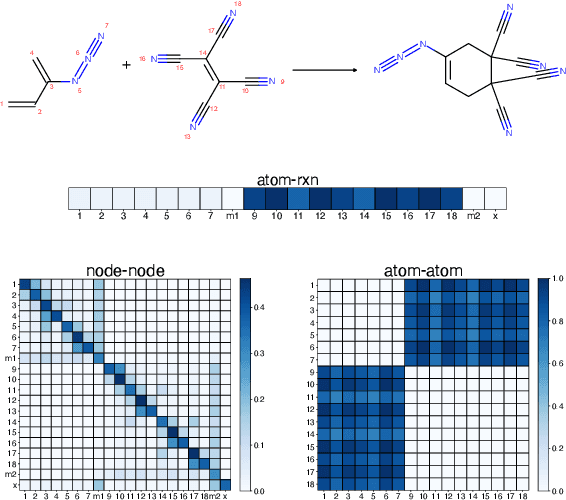
It is fundamental for science and technology to be able to predict chemical reactions and their properties. To achieve such skills, it is important to develop good representations of chemical reactions, or good deep learning architectures that can learn such representations automatically from the data. There is currently no universal and widely adopted method for robustly representing chemical reactions. Most existing methods suffer from one or more drawbacks, such as: (1) lacking universality; (2) lacking robustness; (3) lacking interpretability; or (4) requiring excessive manual pre-processing. Here we exploit graph-based representations of molecular structures to develop and test a hypergraph attention neural network approach to solve at once the reaction representation and property-prediction problems, alleviating the aforementioned drawbacks. We evaluate this hypergraph representation in three experiments using three independent data sets of chemical reactions. In all experiments, the hypergraph-based approach matches or outperforms other representations and their corresponding models of chemical reactions while yielding interpretable multi-level representations.
Tourbillon: a Physically Plausible Neural Architecture
Jul 22, 2021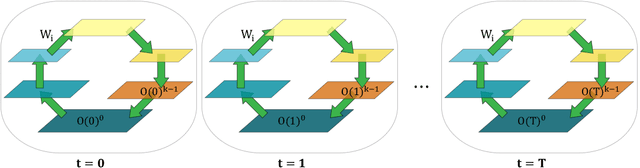
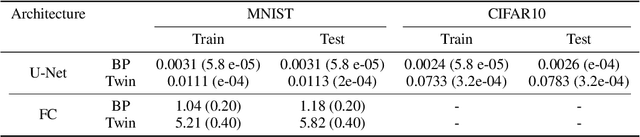
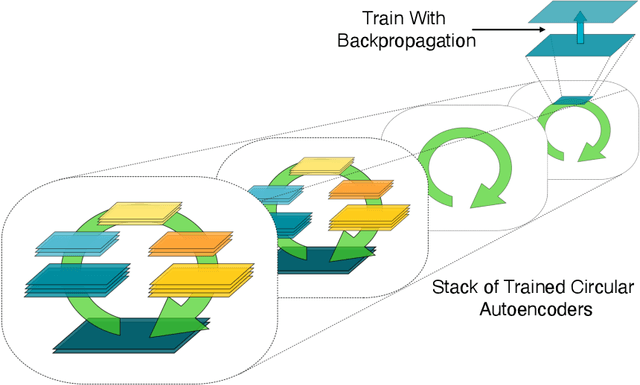
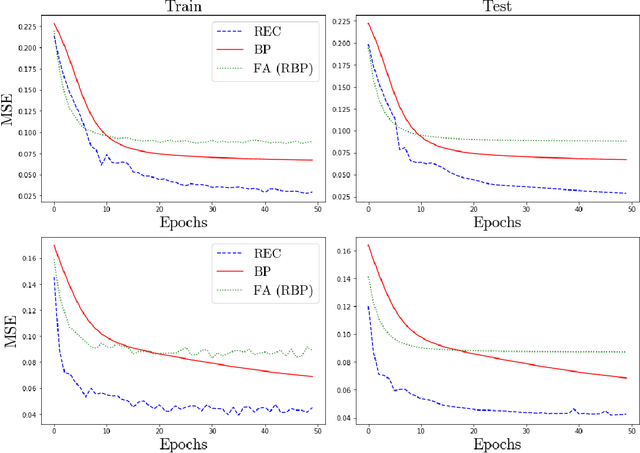
In a physical neural system, backpropagation is faced with a number of obstacles including: the need for labeled data, the violation of the locality learning principle, the need for symmetric connections, and the lack of modularity. Tourbillon is a new architecture that addresses all these limitations. At its core, it consists of a stack of circular autoencoders followed by an output layer. The circular autoencoders are trained in self-supervised mode by recirculation algorithms and the top layer in supervised mode by stochastic gradient descent, with the option of propagating error information through the entire stack using non-symmetric connections. While the Tourbillon architecture is meant primarily to address physical constraints, and not to improve current engineering applications of deep learning, we demonstrate its viability on standard benchmark datasets including MNIST, Fashion MNIST, and CIFAR10. We show that Tourbillon can achieve comparable performance to models trained with backpropagation and outperform models that are trained with other physically plausible algorithms, such as feedback alignment.
Improving Social Welfare While Preserving Autonomy via a Pareto Mediator
Jun 07, 2021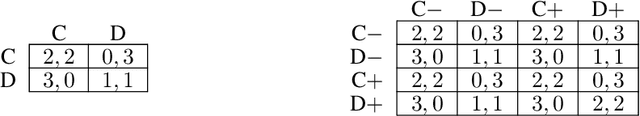
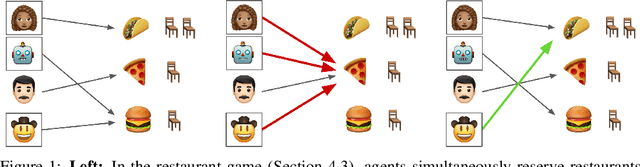
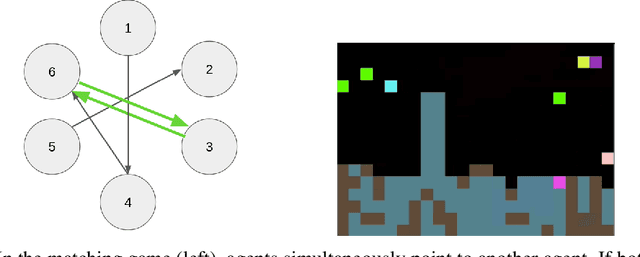

Machine learning algorithms often make decisions on behalf of agents with varied and sometimes conflicting interests. In domains where agents can choose to take their own action or delegate their action to a central mediator, an open question is how mediators should take actions on behalf of delegating agents. The main existing approach uses delegating agents to punish non-delegating agents in an attempt to get all agents to delegate, which tends to be costly for all. We introduce a Pareto Mediator which aims to improve outcomes for delegating agents without making any of them worse off. Our experiments in random normal form games, a restaurant recommendation game, and a reinforcement learning sequential social dilemma show that the Pareto Mediator greatly increases social welfare. Also, even when the Pareto Mediator is based on an incorrect model of agent utility, performance gracefully degrades to the pre-intervention level, due to the individual autonomy preserved by the voluntary mediator.
SPANet: Generalized Permutationless Set Assignment for Particle Physics using Symmetry Preserving Attention
Jun 07, 2021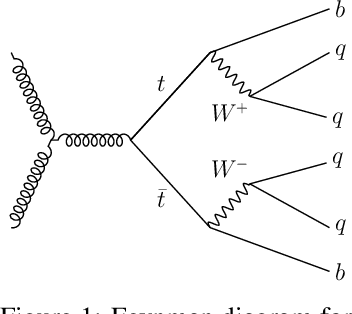
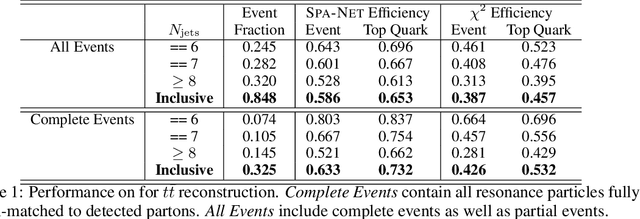
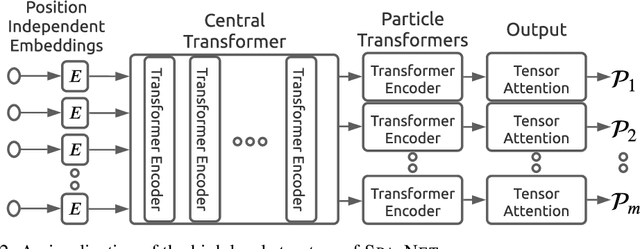
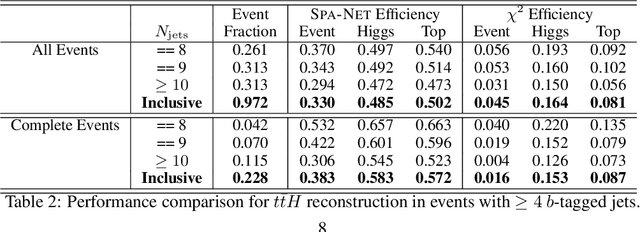
The creation of unstable heavy particles at the Large Hadron Collider is the most direct way to address some of the deepest open questions in physics. Collisions typically produce variable-size sets of observed particles which have inherent ambiguities complicating the assignment of observed particles to the decay products of the heavy particles. Current strategies for tackling these challenges in the physics community ignore the physical symmetries of the decay products and consider all possible assignment permutations and do not scale to complex configurations. Attention based deep learning methods for sequence modelling have achieved state-of-the-art performance in natural language processing, but they lack built-in mechanisms to deal with the unique symmetries found in physical set-assignment problems. We introduce a novel method for constructing symmetry-preserving attention networks which reflect the problem's natural invariances to efficiently find assignments without evaluating all permutations. This general approach is applicable to arbitrarily complex configurations and significantly outperforms current methods, improving reconstruction efficiency between 19\% - 35\% on typical benchmark problems while decreasing inference time by two to five orders of magnitude on the most complex events, making many important and previously intractable cases tractable. A full code repository containing a general library, the specific configuration used, and a complete dataset release, are avaiable at https://github.com/Alexanders101/SPANet
Quantum Mechanics and Machine Learning Synergies: Graph Attention Neural Networks to Predict Chemical Reactivity
Mar 24, 2021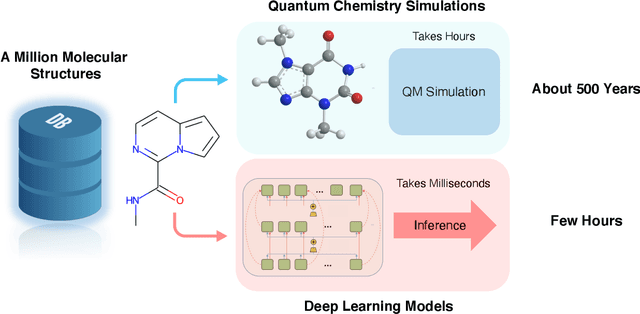
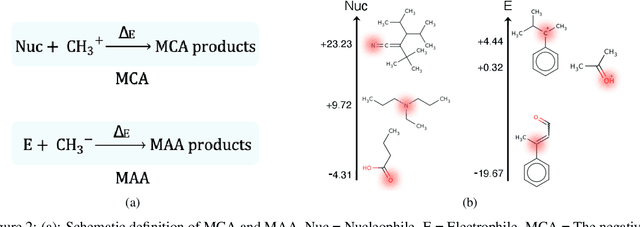

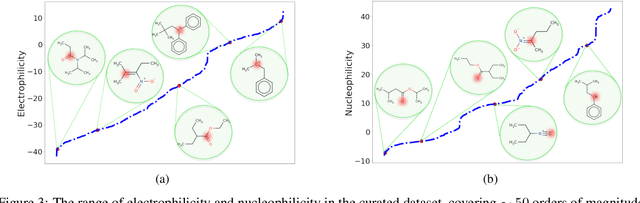
There is a lack of scalable quantitative measures of reactivity for functional groups in organic chemistry. Measuring reactivity experimentally is costly and time-consuming and does not scale to the astronomical size of chemical space. In previous quantum chemistry studies, we have introduced Methyl Cation Affinities (MCA*) and Methyl Anion Affinities (MAA*), using a solvation model, as quantitative measures of reactivity for organic functional groups over the broadest range. Although MCA* and MAA* offer good estimates of reactivity parameters, their calculation through Density Functional Theory (DFT) simulations is time-consuming. To circumvent this problem, we first use DFT to calculate MCA* and MAA* for more than 2,400 organic molecules thereby establishing a large dataset of chemical reactivity scores. We then design deep learning methods to predict the reactivity of molecular structures and train them using this curated dataset in combination with different representations of molecular structures. Using ten-fold cross-validation, we show that graph attention neural networks applied to informative input fingerprints produce the most accurate estimates of reactivity, achieving over 91% test accuracy for predicting the MCA* plus-minus 3.0 or MAA* plus-minus 3.0, over 50 orders of magnitude. Finally, we demonstrate the application of these reactivity scores to two tasks: (1) chemical reaction prediction; (2) combinatorial generation of reaction mechanisms. The curated dataset of MCA* and MAA* scores is available through the ChemDB chemoinformatics web portal at www.cdb.ics.uci.edu.
XDO: A Double Oracle Algorithm for Extensive-Form Games
Mar 11, 2021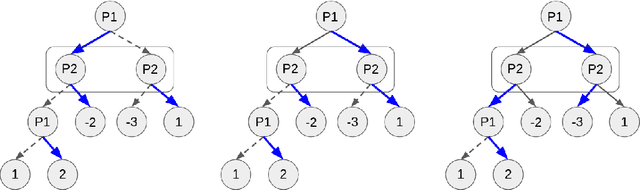
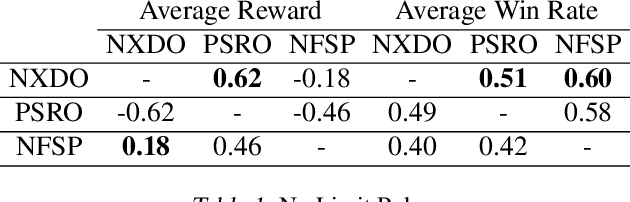

Policy Space Response Oracles (PSRO) is a deep reinforcement learning algorithm for two-player zero-sum games that has empirically found approximate Nash equilibria in large games. Although PSRO is guaranteed to converge to a Nash equilibrium, it may take an exponential number of iterations as the number of infostates grows. We propose Extensive-Form Double Oracle (XDO), an extensive-form double oracle algorithm that is guaranteed to converge to an approximate Nash equilibrium linearly in the number of infostates. Unlike PSRO, which mixes best responses at the root of the game, XDO mixes best responses at every infostate. We also introduce Neural XDO (NXDO), where the best response is learned through deep RL. In tabular experiments on Leduc poker, we find that XDO achieves an approximate Nash equilibrium in a number of iterations 1-2 orders of magnitude smaller than PSRO. In experiments on a modified Leduc poker game, we show that tabular XDO achieves over 11x lower exploitability than CFR and over 82x lower exploitability than PSRO and XFP in the same amount of time. We also show that NXDO beats PSRO and is competitive with NFSP on a large no-limit poker game.
A theory of capacity and sparse neural encoding
Feb 19, 2021
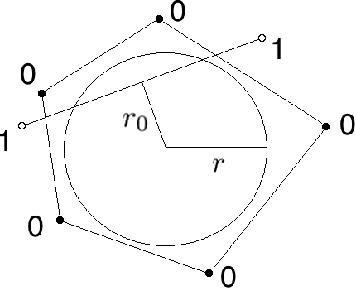
Motivated by biological considerations, we study sparse neural maps from an input layer to a target layer with sparse activity, and specifically the problem of storing $K$ input-target associations $(x,y)$, or memories, when the target vectors $y$ are sparse. We mathematically prove that $K$ undergoes a phase transition and that in general, and somewhat paradoxically, sparsity in the target layers increases the storage capacity of the map. The target vectors can be chosen arbitrarily, including in random fashion, and the memories can be both encoded and decoded by networks trained using local learning rules, including the simple Hebb rule. These results are robust under a variety of statistical assumptions on the data. The proofs rely on elegant properties of random polytopes and sub-gaussian random vector variables. Open problems and connections to capacity theories and polynomial threshold maps are discussed.
A* Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
Feb 08, 2021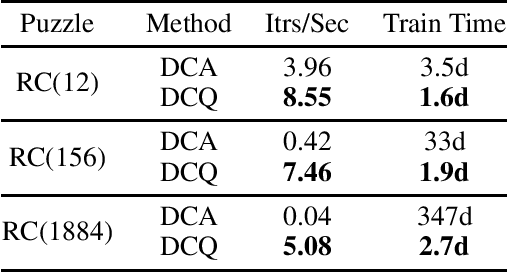
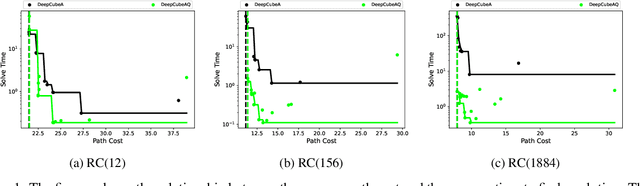
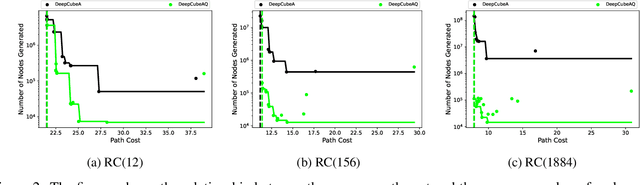

A* search is an informed search algorithm that uses a heuristic function to guide the order in which nodes are expanded. Since the computation required to expand a node and compute the heuristic values for all of its generated children grows linearly with the size of the action space, A* search can become impractical for problems with large action spaces. This computational burden becomes even more apparent when heuristic functions are learned by general, but computationally expensive, deep neural networks. To address this problem, we introduce DeepCubeAQ, a deep reinforcement learning and search algorithm that builds on the DeepCubeA algorithm and deep Q-networks. DeepCubeAQ learns a heuristic function that, with a single forward pass through a deep neural network, computes the sum of the transition cost and the heuristic value of all of the children of a node without explicitly generating any of the children, eliminating the need for node expansions. DeepCubeAQ then uses a novel variant of A* search, called AQ* search, that uses the deep Q-network to guide search. We use DeepCubeAQ to solve the Rubik's cube when formulated with a large action space that includes 1872 meta-actions and show that this 157-fold increase in the size of the action space incurs less than a 4-fold increase in computation time when performing AQ* search and that AQ* search is orders of magnitude faster than A* search.
Detecting Pulmonary Coccidioidomycosis (Valley fever) with Deep Convolutional Neural Networks
Jan 30, 2021

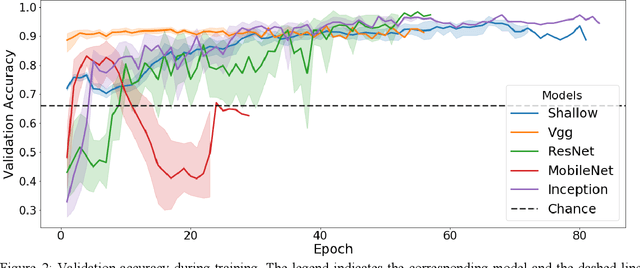
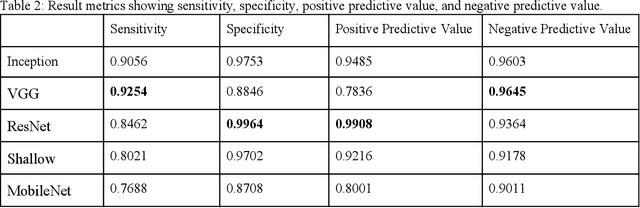
Coccidioidomycosis is the most common systemic mycosis in dogs in the southwestern United States. With warming climates, affected areas and number of cases are expected to increase in the coming years, escalating also the chances of transmission to humans. As a result, developing methods for automating the detection of the disease is important, as this will help doctors and veterinarians more easily identify and diagnose positive cases. We apply machine learning models to provide accurate and interpretable predictions of Coccidioidomycosis. We assemble a set of radiographic images and use it to train and test state-of-the-art convolutional neural networks to detect Coccidioidomycosis. These methods are relatively inexpensive to train and very fast at inference time. We demonstrate the successful application of this approach to detect the disease with an Area Under the Curve (AUC) above 0.99 using 10-fold cross validation. We also use the classification model to identify regions of interest and localize the disease in the radiographic images, as illustrated through visual heatmaps. This proof-of-concept study establishes the feasibility of very accurate and rapid automated detection of Valley Fever in radiographic images.