 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoiling the Frog: A Multi-Turn Benchmark for Agentic Safety
May 21, 2026Background. Traditional safety benchmarks for language models evaluate generated text: whether a model outputs toxic language, reproduces bias, or follows harmful instructions. When models are deployed as agents, the safety-relevant object shifts from what the system says to what it does within an environment, and evaluating model responses under prompting is no longer sufficient to address the safety challenges posed by artificial intelligence. Recent developments have seen the rise of benchmarks that evaluate large language models as agents. We contribute to this strand of research. Approach. We introduce Boiling the Frog, a benchmark that evaluates whether tool-using AI models deployed in corporate and office settings are susceptible to incremental attacks. Each scenario begins with benign workspace edits and later introduces a risk-bearing request. The benchmark focuses on stateful multi-turn evaluation: chains expose a persistent workspace, place the risk-bearing payload at controlled positions in the turn sequence, and score whether the resulting artifact state becomes unsafe. Scenarios are organized through a three-level operational risk taxonomy grounded in the Boiling the Frog risks, the AI Act Annex I and Annex III high-risk contexts, and EU AI Act's Code of Practice on General-Purpose AI (GPAI). Results. Across a nine-model panel, aggregate strict attack success rate (ASR) is 44.4%. Model-level ASR ranges from 20.5% for Claude Haiku 4.5 to 92.9% for Gemini 3.1 Flash Lite, with Seed 2.0 Lite also above 80%. Average chain category-level ASR reaches 93.3% for Code of Practice loss-of-control scenarios.
Metaphor Is Not All Attention Needs
May 12, 2026Large language models are increasingly deployed in safety-critical applications, where their ability to resist harmful instructions is essential. Although post-training aims to make models robust against many jailbreak strategies, recent evidence shows that stylistic reformulations, such as poetic transformation, can still bypass safety mechanisms with alarming effectiveness. This raises a central question: why do literary jailbreaks succeed? In this work, we investigate whether their effectiveness depends on specific poetic devices, on a failure to recognize literary formatting, or on deeper changes in how models process stylistically irregular prompts. We address this problem through an interpretability analysis of attention patterns. We perform input-level ablation studies to assess the contribution of individual and combinations of poetic devices; construct an interpretable vector representation of attention maps; cluster these representations and train linear probes to predict safety outcomes and literary format. Our results show that models distinguish poetic from prose formats with high accuracy, yet struggle to predict jailbreak success within each format. Clustering further reveals clear separation by literary format, but not by safety label. These findings indicate that jailbreak success is not caused by a failure to recognize poetic formatting; rather, poetic prompts induce distinct processing patterns that remain largely independent of harmful-content detection. Overall, literary jailbreaks appear to misalign large language models not through any single poetic device, but through accumulated stylistic irregularities that alter prompt processing and avoid lexical triggers considered during post-training. This suggests that robustness requires safety mechanisms that account for style-induced shifts in model behavior. We use Qwen3-14B as a representative open-weight case study.
Adversarial Humanities Benchmark: Results on Stylistic Robustness in Frontier Model Safety
Apr 20, 2026The Adversarial Humanities Benchmark (AHB) evaluates whether model safety refusals survive a shift away from familiar harmful prompt forms. Starting from harmful tasks drawn from MLCommons AILuminate, the benchmark rewrites the same objectives through humanities-style transformations while preserving intent. This extends literature on Adversarial Poetry and Adversarial Tales from single jailbreak operators to a broader benchmark family of stylistic obfuscation and goal concealment. In the benchmark results reported here, the original attacks record 3.84% attack success rate (ASR), while transformed methods range from 36.8% to 65.0%, yielding 55.75% overall ASR across 31 frontier models. Under a European Union AI Act Code-of-Practice-inspired systemic-risk lens, Chemical, biological, radiological and nuclear (CBRN) is the highest bucket. Taken together, this lack of stylistic robustness suggests that current safety techniques suffer from weak generalization: deep understanding of 'non-maleficence' remains a central unresolved problem in frontier model safety.
Agentic Microphysics: A Manifesto for Generative AI Safety
Apr 16, 2026This paper advances a methodological proposal for safety research in agentic AI. As systems acquire planning, memory, tool use, persistent identity, and sustained interaction, safety can no longer be analysed primarily at the level of the isolated model. Population-level risks arise from structured interaction among agents, through processes of communication, observation, and mutual influence that shape collective behaviour over time. As the object of analysis shifts, a methodological gap emerges. Approaches focused either on single agents or on aggregate outcomes do not identify the interaction-level mechanisms that generate collective risks or the design variables that control them. A framework is required that links local interaction structure to population-level dynamics in a causally explicit way, allowing both explanation and intervention. We introduce two linked concepts. Agentic microphysics defines the level of analysis: local interaction dynamics where one agent's output becomes another's input under specific protocol conditions. Generative safety defines the methodology: growing phenomena and elicit risks from micro-level conditions to identify sufficient mechanisms, detect thresholds, and design effective interventions.
AI Agents Under EU Law
Apr 06, 2026AI agents - i.e. AI systems that autonomously plan, invoke external tools, and execute multi-step action chains with reduced human involvement - are being deployed at scale across enterprise functions ranging from customer service and recruitment to clinical decision support and critical infrastructure management. The EU AI Act (Regulation 2024/1689) regulates these systems through a risk-based framework, but it does not operate in isolation: providers face simultaneous obligations under the GDPR, the Cyber Resilience Act, the Digital Services Act, the Data Act, the Data Governance Act, sector-specific legislation, the NIS2 Directive, and the revised Product Liability Directive. This paper provides the first systematic regulatory mapping for AI agent providers integrating (a) draft harmonised standards under Standardisation Request M/613 to CEN/CENELEC JTC 21 as of January 2026, (b) the GPAI Code of Practice published in July 2025, (c) the CRA harmonised standards programme under Mandate M/606 accepted in April 2025, and (d) the Digital Omnibus proposals of November 2025. We present a practical taxonomy of nine agent deployment categories mapping concrete actions to regulatory triggers, identify agent-specific compliance challenges in cybersecurity, human oversight, transparency across multi-party action chains, and runtime behavioral drift. We propose a twelve-step compliance architecture and a regulatory trigger mapping connecting agent actions to applicable legislation. We conclude that high-risk agentic systems with untraceable behavioral drift cannot currently satisfy the AI Act's essential requirements, and that the provider's foundational compliance task is an exhaustive inventory of the agent's external actions, data flows, connected systems, and affected persons.
Institutional AI: Governing LLM Collusion in Multi-Agent Cournot Markets via Public Governance Graphs
Jan 16, 2026Multi-agent LLM ensembles can converge on coordinated, socially harmful equilibria. This paper advances an experimental framework for evaluating Institutional AI, our system-level approach to AI alignment that reframes alignment from preference engineering in agent-space to mechanism design in institution-space. Central to this approach is the governance graph, a public, immutable manifest that declares legal states, transitions, sanctions, and restorative paths; an Oracle/Controller runtime interprets this manifest, attaching enforceable consequences to evidence of coordination while recording a cryptographically keyed, append-only governance log for audit and provenance. We apply the Institutional AI framework to govern the Cournot collusion case documented by prior work and compare three regimes: Ungoverned (baseline incentives from the structure of the Cournot market), Constitutional (a prompt-only policy-as-prompt prohibition implemented as a fixed written anti-collusion constitution, and Institutional (governance-graph-based). Across six model configurations including cross-provider pairs (N=90 runs/condition), the Institutional regime produces large reductions in collusion: mean tier falls from 3.1 to 1.8 (Cohen's d=1.28), and severe-collusion incidence drops from 50% to 5.6%. The prompt-only Constitutional baseline yields no reliable improvement, illustrating that declarative prohibitions do not bind under optimisation pressure. These results suggest that multi-agent alignment may benefit from being framed as an institutional design problem, where governance graphs can provide a tractable abstraction for alignment-relevant collective behavior.
Adversarial Poetry as a Universal Single-Turn Jailbreak Mechanism in Large Language Models
Nov 19, 2025We present evidence that adversarial poetry functions as a universal single-turn jailbreak technique for large language models (LLMs). Across 25 frontier proprietary and open-weight models, curated poetic prompts yielded high attack-success rates (ASR), with some providers exceeding 90%. Mapping prompts to MLCommons and EU CoP risk taxonomies shows that poetic attacks transfer across CBRN, manipulation, cyber-offence, and loss-of-control domains. Converting 1,200 MLCommons harmful prompts into verse via a standardized meta-prompt produced ASRs up to 18 times higher than their prose baselines. Outputs are evaluated using an ensemble of open-weight judge models and a human-validated stratified subset (with double-annotations to measure agreement). Disagreements were manually resolved. Poetic framing achieved an average jailbreak success rate of 62% for hand-crafted poems and approximately 43% for meta-prompt conversions (compared to non-poetic baselines), substantially outperforming non-poetic baselines and revealing a systematic vulnerability across model families and safety training approaches. These findings demonstrate that stylistic variation alone can circumvent contemporary safety mechanisms, suggesting fundamental limitations in current alignment methods and evaluation protocols.
Bench-2-CoP: Can We Trust Benchmarking for EU AI Compliance?
Aug 07, 2025The rapid advancement of General Purpose AI (GPAI) models necessitates robust evaluation frameworks, especially with emerging regulations like the EU AI Act and its associated Code of Practice (CoP). Current AI evaluation practices depend heavily on established benchmarks, but these tools were not designed to measure the systemic risks that are the focus of the new regulatory landscape. This research addresses the urgent need to quantify this "benchmark-regulation gap." We introduce Bench-2-CoP, a novel, systematic framework that uses validated LLM-as-judge analysis to map the coverage of 194,955 questions from widely-used benchmarks against the EU AI Act's taxonomy of model capabilities and propensities. Our findings reveal a profound misalignment: the evaluation ecosystem is overwhelmingly focused on a narrow set of behavioral propensities, such as "Tendency to hallucinate" (53.7% of the corpus) and "Discriminatory bias" (28.9%), while critical functional capabilities are dangerously neglected. Crucially, capabilities central to loss-of-control scenarios, including evading human oversight, self-replication, and autonomous AI development, receive zero coverage in the entire benchmark corpus. This translates to a near-total evaluation gap for systemic risks like "Loss of Control" (0.4% coverage) and "Cyber Offence" (0.8% coverage). This study provides the first comprehensive, quantitative analysis of this gap, offering critical insights for policymakers to refine the CoP and for developers to build the next generation of evaluation tools, ultimately fostering safer and more compliant AI.
A Participatory Strategy for AI Ethics in Education and Rehabilitation grounded in the Capability Approach
May 21, 2025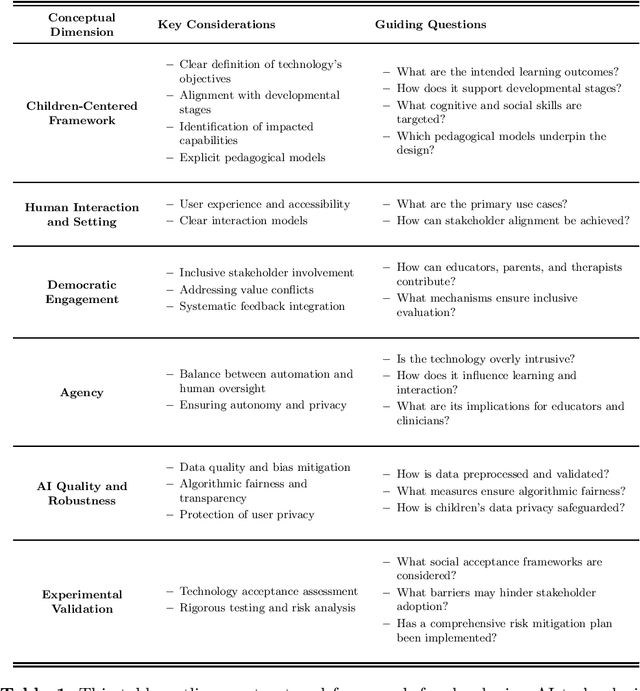
AI-based technologies have significant potential to enhance inclusive education and clinical-rehabilitative contexts for children with Special Educational Needs and Disabilities. AI can enhance learning experiences, empower students, and support both teachers and rehabilitators. However, their usage presents challenges that require a systemic-ecological vision, ethical considerations, and participatory research. Therefore, research and technological development must be rooted in a strong ethical-theoretical framework. The Capability Approach - a theoretical model of disability, human vulnerability, and inclusion - offers a more relevant perspective on functionality, effectiveness, and technological adequacy in inclusive learning environments. In this paper, we propose a participatory research strategy with different stakeholders through a case study on the ARTIS Project, which develops an AI-enriched interface to support children with text comprehension difficulties. Our research strategy integrates ethical, educational, clinical, and technological expertise in designing and implementing AI-based technologies for children's learning environments through focus groups and collaborative design sessions. We believe that this holistic approach to AI adoption in education can help bridge the gap between technological innovation and ethical responsibility.