 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2025 E2LM Competition : Early Training Evaluation of Language Models
Jun 09, 2025Existing benchmarks have proven effective for assessing the performance of fully trained large language models. However, we find striking differences in the early training stages of small models, where benchmarks often fail to provide meaningful or discriminative signals. To explore how these differences arise, this competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with limited computational resources. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their relevance to the scientific knowledge domain. By promoting the design of tailored evaluation strategies for early training, this competition aims to attract a broad range of participants from various disciplines, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Managing Large Dataset Gaps in Urban Air Quality Prediction: DCU-Insight-AQ at MediaEval 2022
Dec 19, 2022Calculating an Air Quality Index (AQI) typically uses data streams from air quality sensors deployed at fixed locations and the calculation is a real time process. If one or a number of sensors are broken or offline, then the real time AQI value cannot be computed. Estimating AQI values for some point in the future is a predictive process and uses historical AQI values to train and build models. In this work we focus on gap filling in air quality data where the task is to predict the AQI at 1, 5 and 7 days into the future. The scenario is where one or a number of air, weather and traffic sensors are offline and explores prediction accuracy under such situations. The work is part of the MediaEval'2022 Urban Air: Urban Life and Air Pollution task submitted by the DCU-Insight-AQ team and uses multimodal and crossmodal data consisting of AQI, weather and CCTV traffic images for air pollution prediction.
Investigating Memorability of Dynamic Media
Dec 31, 2020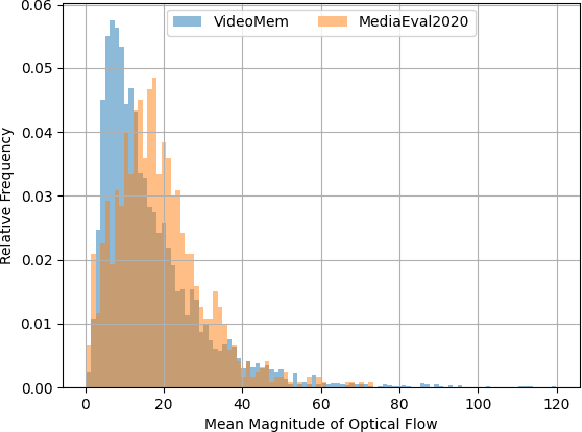
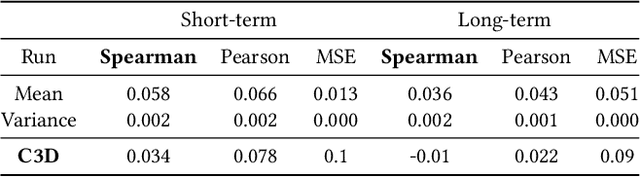
The Predicting Media Memorability task in MediaEval'20 has some challenging aspects compared to previous years. In this paper we identify the high-dynamic content in videos and dataset of limited size as the core challenges for the task, we propose directions to overcome some of these challenges and we present our initial result in these directions.
* 3 pages, 1 figure. 1 table
Contrastive Representation Learning: A Framework and Review
Oct 27, 2020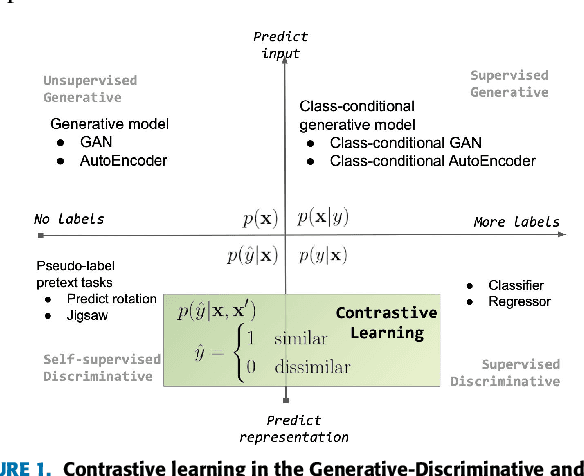
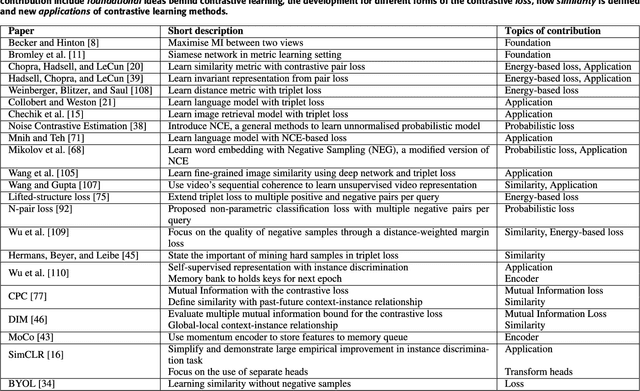
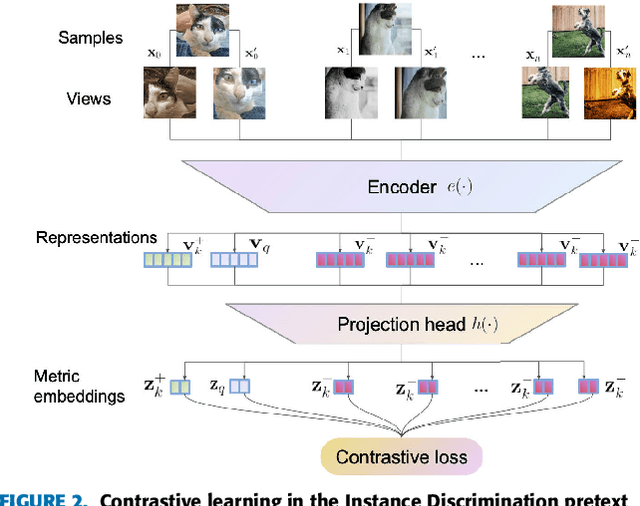
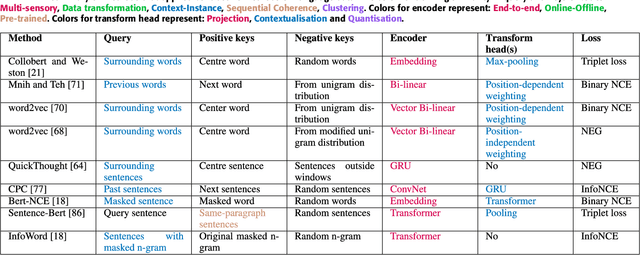
Contrastive Learning has recently received interest due to its success in self-supervised representation learning in the computer vision domain. However, the origins of Contrastive Learning date as far back as the 1990s and its development has spanned across many fields and domains including Metric Learning and natural language processing. In this paper we provide a comprehensive literature review and we propose a general Contrastive Representation Learning framework that simplifies and unifies many different contrastive learning methods. We also provide a taxonomy for each of the components of contrastive learning in order to summarise it and distinguish it from other forms of machine learning. We then discuss the inductive biases which are present in any contrastive learning system and we analyse our framework under different views from various sub-fields of Machine Learning. Examples of how contrastive learning has been applied in computer vision, natural language processing, audio processing, and others, as well as in Reinforcement Learning are also presented. Finally, we discuss the challenges and some of the most promising future research directions ahead.