 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarrier Function Overrides For Non-Convex Fixed Wing Flight Control and Self-Driving Cars
May 08, 2025Reinforcement Learning (RL) has enabled vast performance improvements for robotics systems. To achieve these results though, the agent often must randomly explore the environment, which for safety critical systems presents a significant challenge. Barrier functions can solve this challenge by enabling an override that approximates the RL control input as closely as possible without violating a safety constraint. Unfortunately, this override can be computationally intractable in cases where the dynamics are not convex in the control input or when time is discrete, as is often the case when training RL systems. We therefore consider these cases, developing novel barrier functions for two non-convex systems (fixed wing aircraft and self-driving cars performing lane merging with adaptive cruise control) in discrete time. Although solving for an online and optimal override is in general intractable when the dynamics are nonconvex in the control input, we investigate approximate solutions, finding that these approximations enable performance commensurate with baseline RL methods with zero safety violations. In particular, even without attempting to solve for the optimal override at all, performance is still competitive with baseline RL performance. We discuss the tradeoffs of the approximate override solutions including performance and computational tractability.
Knowledge-based Refinement of Scientific Publication Knowledge Graphs
Sep 10, 2023



We consider the problem of identifying authorship by posing it as a knowledge graph construction and refinement. To this effect, we model this problem as learning a probabilistic logic model in the presence of human guidance (knowledge-based learning). Specifically, we learn relational regression trees using functional gradient boosting that outputs explainable rules. To incorporate human knowledge, advice in the form of first-order clauses is injected to refine the trees. We demonstrate the usefulness of human knowledge both quantitatively and qualitatively in seven authorship domains.
User Friendly Automatic Construction of Background Knowledge: Mode Construction from ER Diagrams
Dec 16, 2019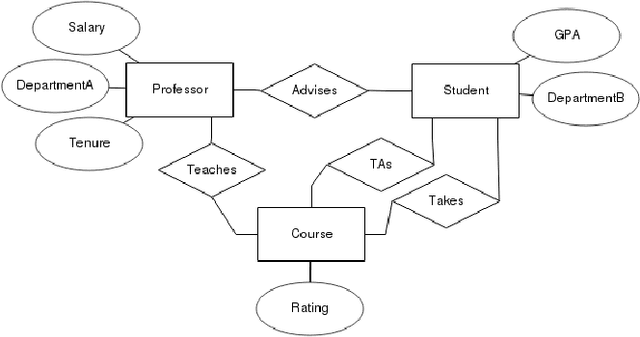

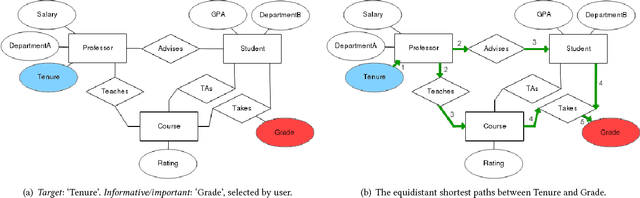
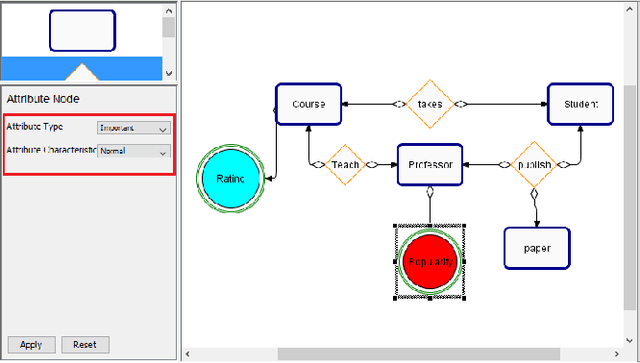
One of the key advantages of Inductive Logic Programming systems is the ability of the domain experts to provide background knowledge as modes that allow for efficient search through the space of hypotheses. However, there is an inherent assumption that this expert should also be an ILP expert to provide effective modes. We relax this assumption by designing a graphical user interface that allows the domain expert to interact with the system using Entity Relationship diagrams. These interactions are used to construct modes for the learning system. We evaluate our algorithm on a probabilistic logic learning system where we demonstrate that the user is able to construct effective background knowledge on par with the expert-encoded knowledge on five data sets.
* 8 pages. Published in Proceedings of the Knowledge Capture Conference, 2017
Multi-class Classification without Multi-class Labels
Jan 02, 2019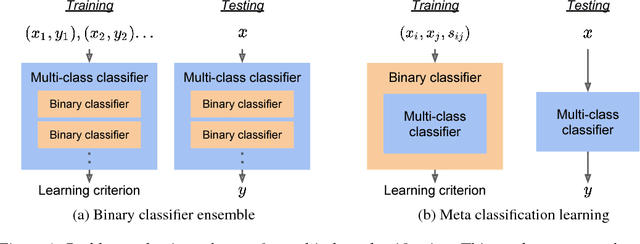
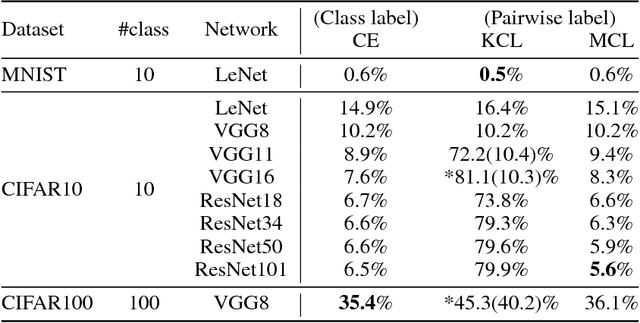
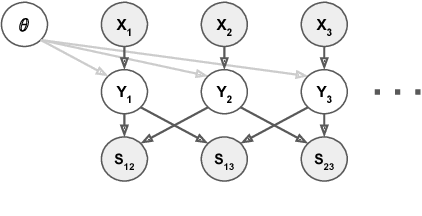
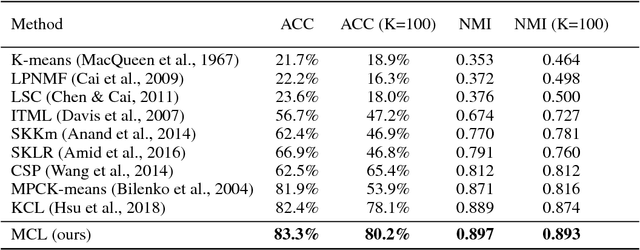
This work presents a new strategy for multi-class classification that requires no class-specific labels, but instead leverages pairwise similarity between examples, which is a weaker form of annotation. The proposed method, meta classification learning, optimizes a binary classifier for pairwise similarity prediction and through this process learns a multi-class classifier as a submodule. We formulate this approach, present a probabilistic graphical model for it, and derive a surprisingly simple loss function that can be used to learn neural network-based models. We then demonstrate that this same framework generalizes to the supervised, unsupervised cross-task, and semi-supervised settings. Our method is evaluated against state of the art in all three learning paradigms and shows a superior or comparable accuracy, providing evidence that learning multi-class classification without multi-class labels is a viable learning option.
A probabilistic constrained clustering for transfer learning and image category discovery
Jun 28, 2018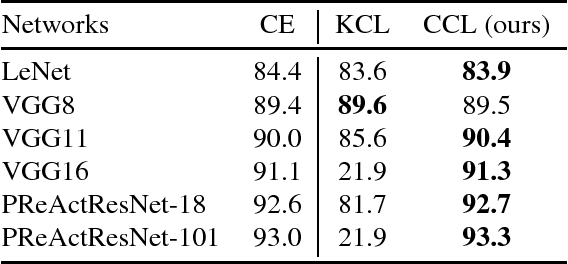
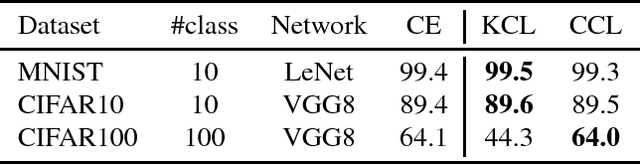
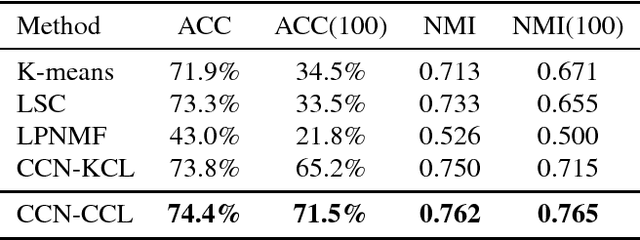
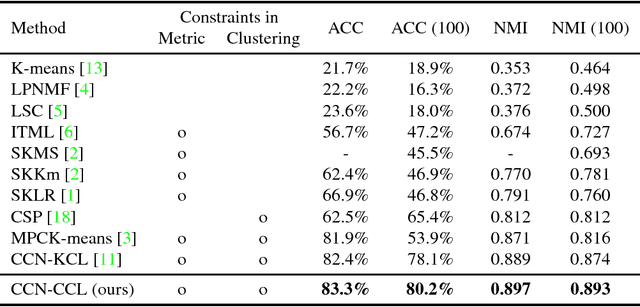
Neural network-based clustering has recently gained popularity, and in particular a constrained clustering formulation has been proposed to perform transfer learning and image category discovery using deep learning. The core idea is to formulate a clustering objective with pairwise constraints that can be used to train a deep clustering network; therefore the cluster assignments and their underlying feature representations are jointly optimized end-to-end. In this work, we provide a novel clustering formulation to address scalability issues of previous work in terms of optimizing deeper networks and larger amounts of categories. The proposed objective directly minimizes the negative log-likelihood of cluster assignment with respect to the pairwise constraints, has no hyper-parameters, and demonstrates improved scalability and performance on both supervised learning and unsupervised transfer learning.
Preference-Guided Planning: An Active Elicitation Approach
Apr 19, 2018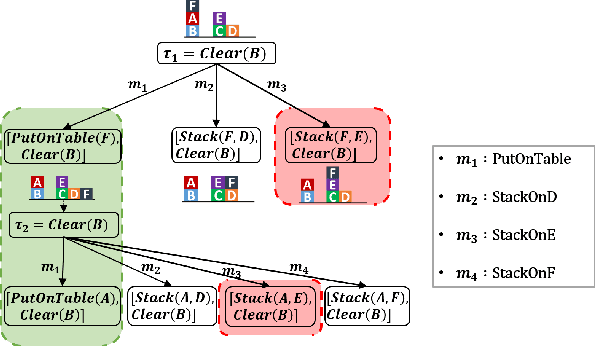
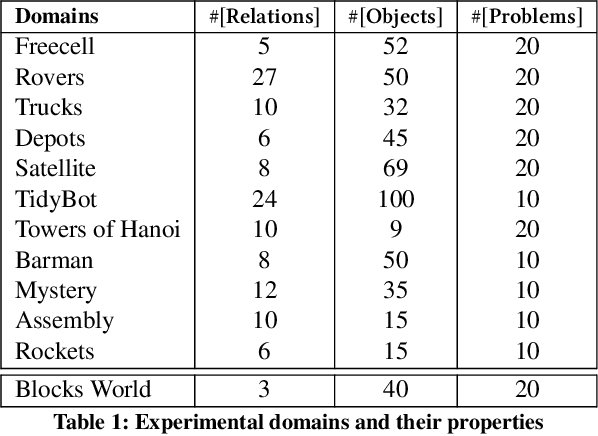

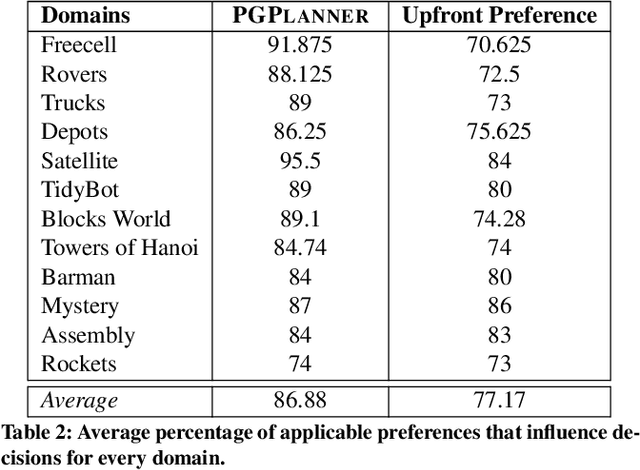
Planning with preferences has been employed extensively to quickly generate high-quality plans. However, it may be difficult for the human expert to supply this information without knowledge of the reasoning employed by the planner and the distribution of planning problems. We consider the problem of actively eliciting preferences from a human expert during the planning process. Specifically, we study this problem in the context of the Hierarchical Task Network (HTN) planning framework as it allows easy interaction with the human. Our experimental results on several diverse planning domains show that the preferences gathered using the proposed approach improve the quality and speed of the planner, while reducing the burden on the human expert.