 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Stochastic Guidance for Navigation
Nov 27, 2018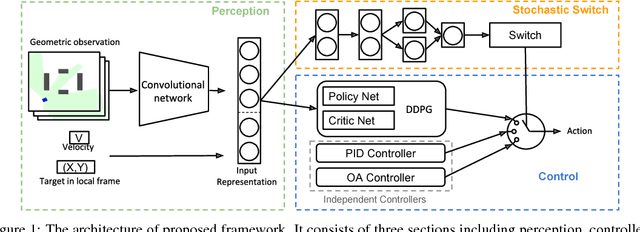
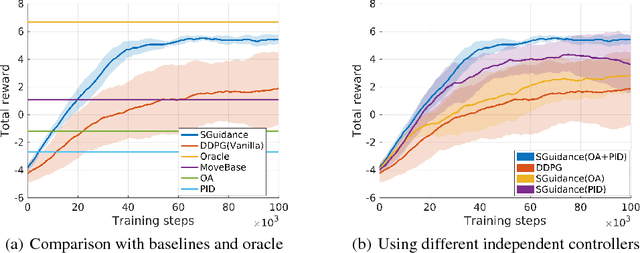
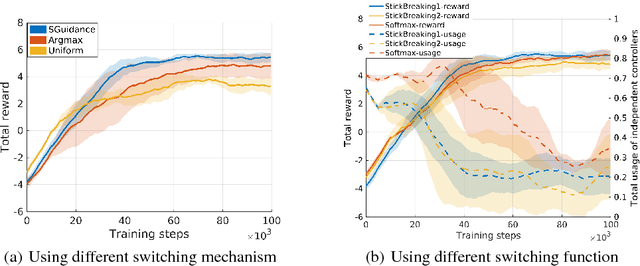
Due to the sparse rewards and high degree of environment variation, reinforcement learning approaches such as Deep Deterministic Policy Gradient (DDPG) are plagued by issues of high variance when applied in complex real world environments. We present a new framework for overcoming these issues by incorporating a stochastic switch, allowing an agent to choose between high and low variance policies. The stochastic switch can be jointly trained with the original DDPG in the same framework. In this paper, we demonstrate the power of the framework in a navigation task, where the robot can dynamically choose to learn through exploration, or to use the output of a heuristic controller as guidance. Instead of starting from completely random moves, the navigation capability of a robot can be quickly bootstrapped by several simple independent controllers. The experimental results show that with the aid of stochastic guidance we are able to effectively and efficiently train DDPG navigation policies and achieve significantly better performance than state-of-the-art baselines models.
Sentence Encoding with Tree-constrained Relation Networks
Nov 26, 2018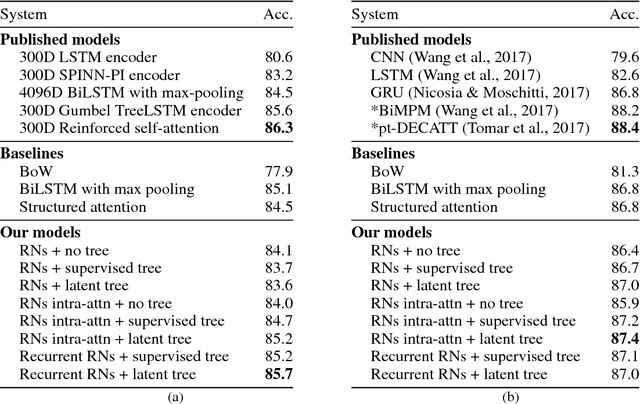
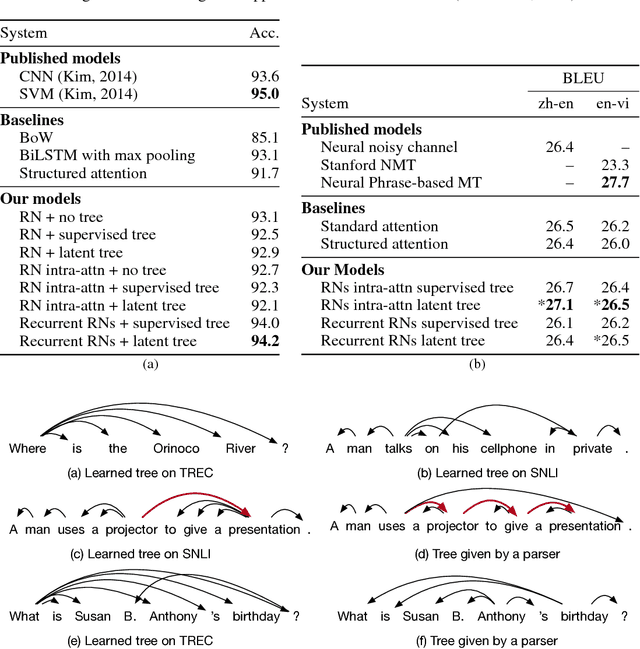
The meaning of a sentence is a function of the relations that hold between its words. We instantiate this relational view of semantics in a series of neural models based on variants of relation networks (RNs) which represent a set of objects (for us, words forming a sentence) in terms of representations of pairs of objects. We propose two extensions to the basic RN model for natural language. First, building on the intuition that not all word pairs are equally informative about the meaning of a sentence, we use constraints based on both supervised and unsupervised dependency syntax to control which relations influence the representation. Second, since higher-order relations are poorly captured by a sum of pairwise relations, we use a recurrent extension of RNs to propagate information so as to form representations of higher order relations. Experiments on sentence classification, sentence pair classification, and machine translation reveal that, while basic RNs are only modestly effective for sentence representation, recurrent RNs with latent syntax are a reliably powerful representational device.
Unsupervised Word Discovery with Segmental Neural Language Models
Nov 23, 2018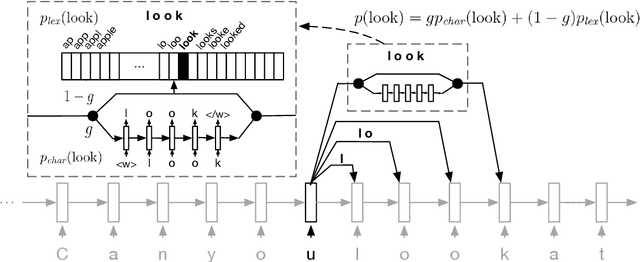
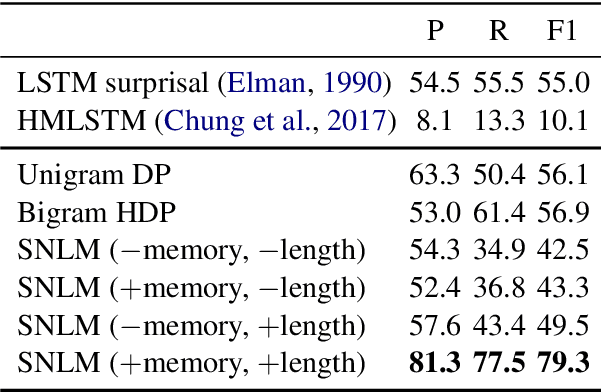
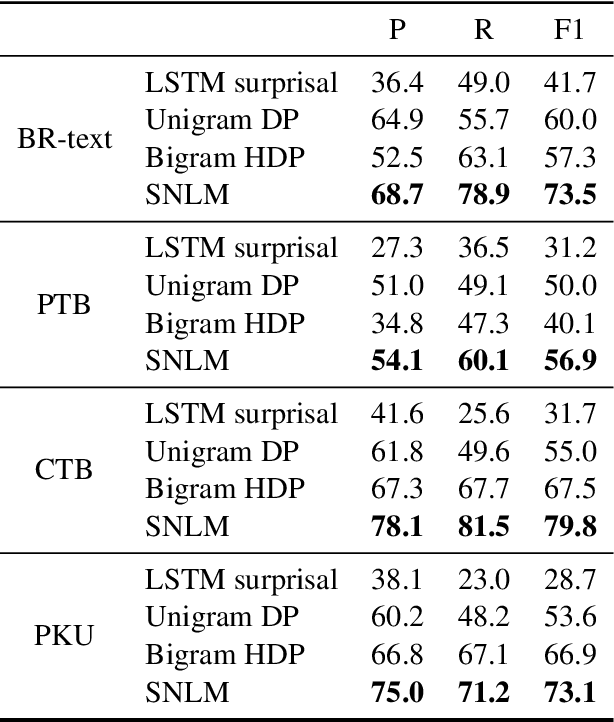
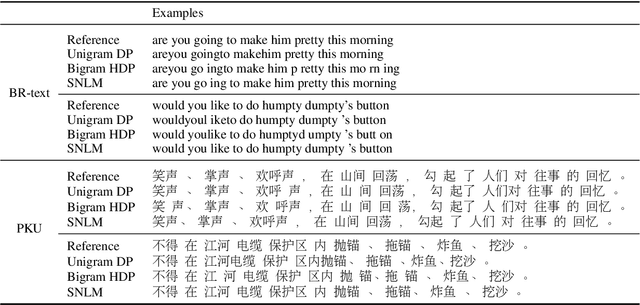
We propose a segmental neural language model that combines the representational power of neural networks and the structure learning mechanism of Bayesian nonparametrics, and show that it learns to discover semantically meaningful units (e.g., morphemes and words) from unsegmented character sequences. The model generates text as a sequence of segments, where each segment is generated either character-by-character from a sequence model or as a single draw from a lexical memory that stores multi-character units. Its parameters are fit to maximize the marginal likelihood of the training data, summing over all segmentations of the input, and its hyperparameters are likewise set to optimize held-out marginal likelihood. To prevent the model from overusing the lexical memory, which leads to poor generalization and bad segmentation, we introduce a differentiable regularizer that penalizes based on the expected length of each segment. To our knowledge, this is the first demonstration of neural networks that have predictive distributions better than LSTM language models and also infer a segmentation into word-like units that are competitive with the best existing word discovery models.
Transferring Physical Motion Between Domains for Neural Inertial Tracking
Oct 04, 2018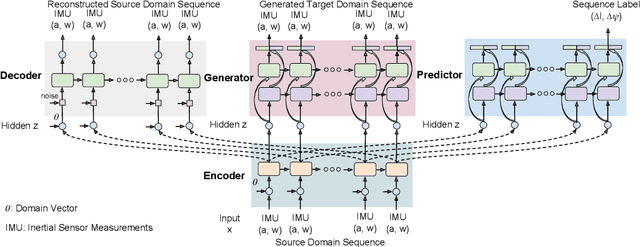
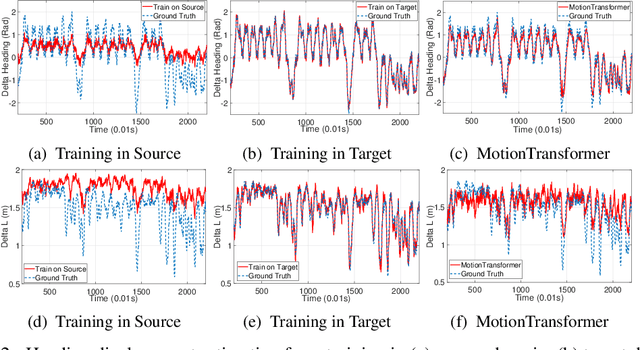
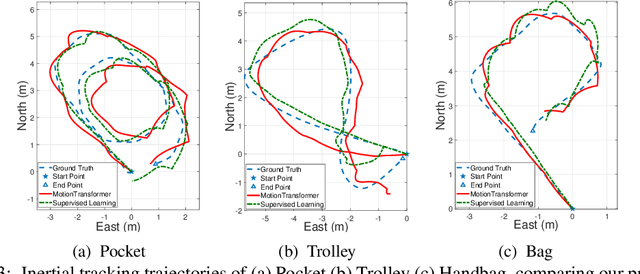
Inertial information processing plays a pivotal role in ego-motion awareness for mobile agents, as inertial measurements are entirely egocentric and not environment dependent. However, they are affected greatly by changes in sensor placement/orientation or motion dynamics, and it is infeasible to collect labelled data from every domain. To overcome the challenges of domain adaptation on long sensory sequences, we propose a novel framework that extracts domain-invariant features of raw sequences from arbitrary domains, and transforms to new domains without any paired data. Through the experiments, we demonstrate that it is able to efficiently and effectively convert the raw sequence from a new unlabelled target domain into an accurate inertial trajectory, benefiting from the physical motion knowledge transferred from the labelled source domain. We also conduct real-world experiments to show our framework can reconstruct physically meaningful trajectories from raw IMU measurements obtained with a standard mobile phone in various attachments.
Pushing the bounds of dropout
Sep 27, 2018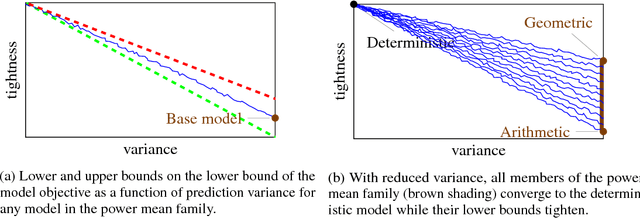

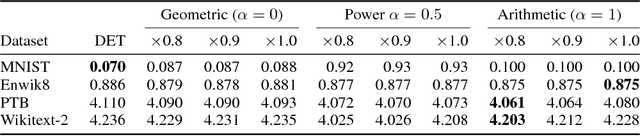
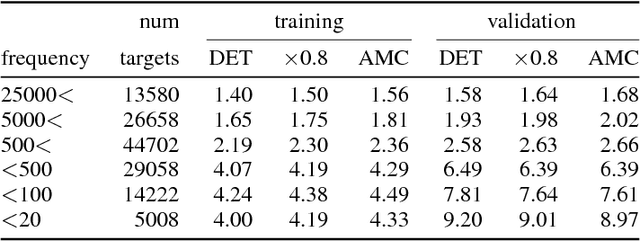
We show that dropout training is best understood as performing MAP estimation concurrently for a family of conditional models whose objectives are themselves lower bounded by the original dropout objective. This discovery allows us to pick any model from this family after training, which leads to a substantial improvement on regularisation-heavy language modelling. The family includes models that compute a power mean over the sampled dropout masks, and their less stochastic subvariants with tighter and higher lower bounds than the fully stochastic dropout objective. We argue that since the deterministic subvariant's bound is equal to its objective, and the highest amongst these models, the predominant view of it as a good approximation to MC averaging is misleading. Rather, deterministic dropout is the best available approximation to the true objective.
Neural Arithmetic Logic Units
Aug 01, 2018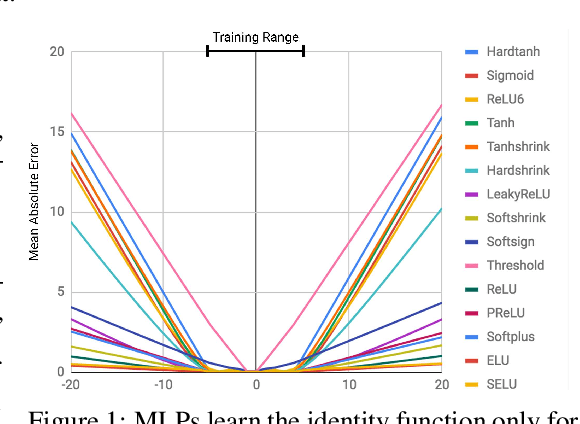
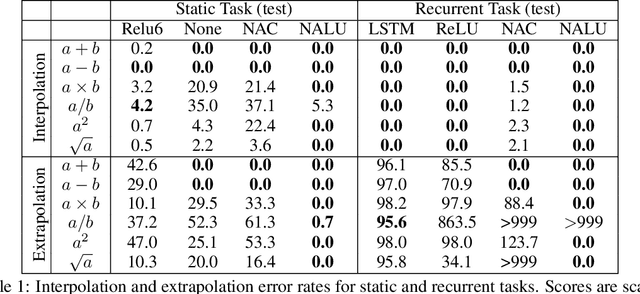
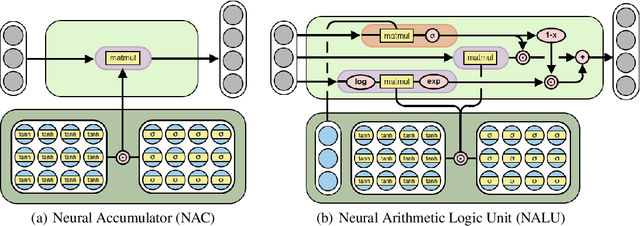
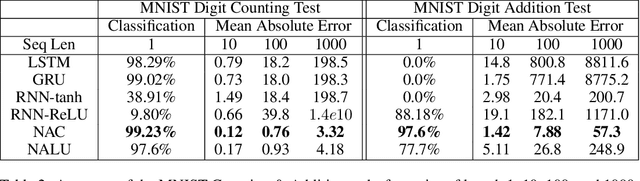
Neural networks can learn to represent and manipulate numerical information, but they seldom generalize well outside of the range of numerical values encountered during training. To encourage more systematic numerical extrapolation, we propose an architecture that represents numerical quantities as linear activations which are manipulated using primitive arithmetic operators, controlled by learned gates. We call this module a neural arithmetic logic unit (NALU), by analogy to the arithmetic logic unit in traditional processors. Experiments show that NALU-enhanced neural networks can learn to track time, perform arithmetic over images of numbers, translate numerical language into real-valued scalars, execute computer code, and count objects in images. In contrast to conventional architectures, we obtain substantially better generalization both inside and outside of the range of numerical values encountered during training, often extrapolating orders of magnitude beyond trained numerical ranges.
Encoding Spatial Relations from Natural Language
Jul 05, 2018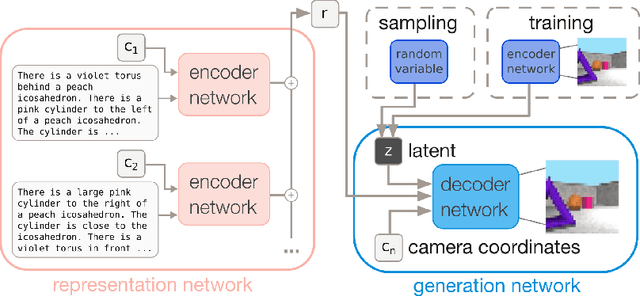

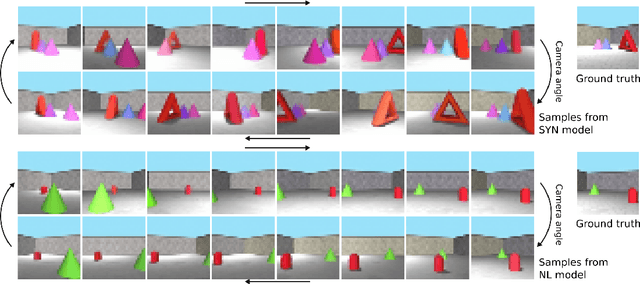
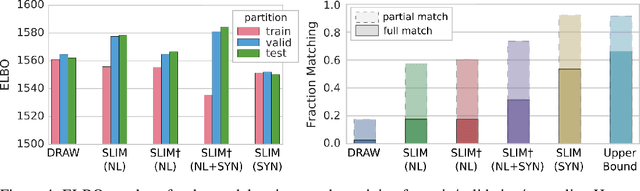
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
Discovering Discrete Latent Topics with Neural Variational Inference
May 21, 2018
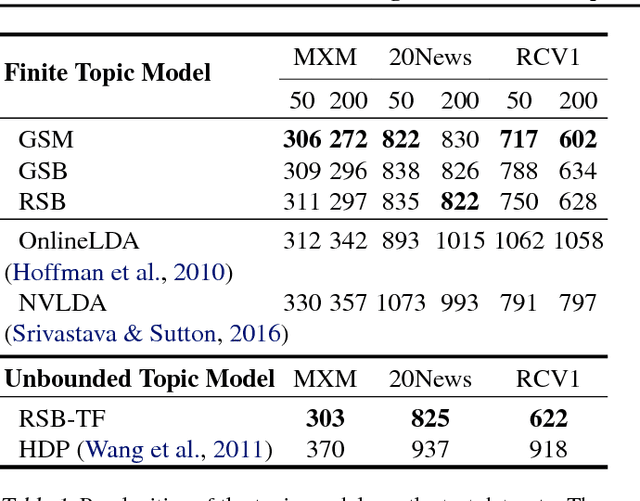
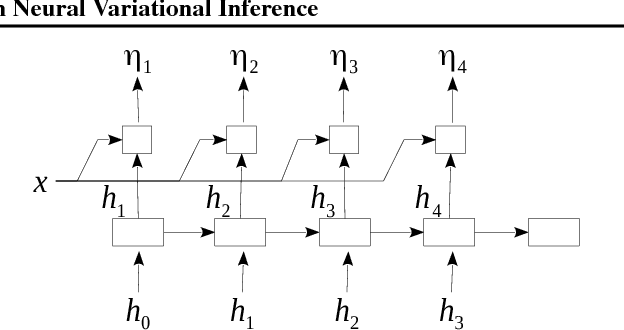
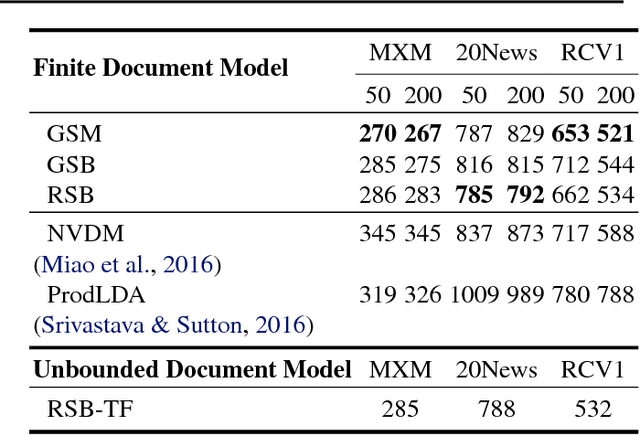
Topic models have been widely explored as probabilistic generative models of documents. Traditional inference methods have sought closed-form derivations for updating the models, however as the expressiveness of these models grows, so does the difficulty of performing fast and accurate inference over their parameters. This paper presents alternative neural approaches to topic modelling by providing parameterisable distributions over topics which permit training by backpropagation in the framework of neural variational inference. In addition, with the help of a stick-breaking construction, we propose a recurrent network that is able to discover a notionally unbounded number of topics, analogous to Bayesian non-parametric topic models. Experimental results on the MXM Song Lyrics, 20NewsGroups and Reuters News datasets demonstrate the effectiveness and efficiency of these neural topic models.
The NarrativeQA Reading Comprehension Challenge
Dec 19, 2017Reading comprehension (RC)---in contrast to information retrieval---requires integrating information and reasoning about events, entities, and their relations across a full document. Question answering is conventionally used to assess RC ability, in both artificial agents and children learning to read. However, existing RC datasets and tasks are dominated by questions that can be solved by selecting answers using superficial information (e.g., local context similarity or global term frequency); they thus fail to test for the essential integrative aspect of RC. To encourage progress on deeper comprehension of language, we present a new dataset and set of tasks in which the reader must answer questions about stories by reading entire books or movie scripts. These tasks are designed so that successfully answering their questions requires understanding the underlying narrative rather than relying on shallow pattern matching or salience. We show that although humans solve the tasks easily, standard RC models struggle on the tasks presented here. We provide an analysis of the dataset and the challenges it presents.
On the State of the Art of Evaluation in Neural Language Models
Nov 20, 2017
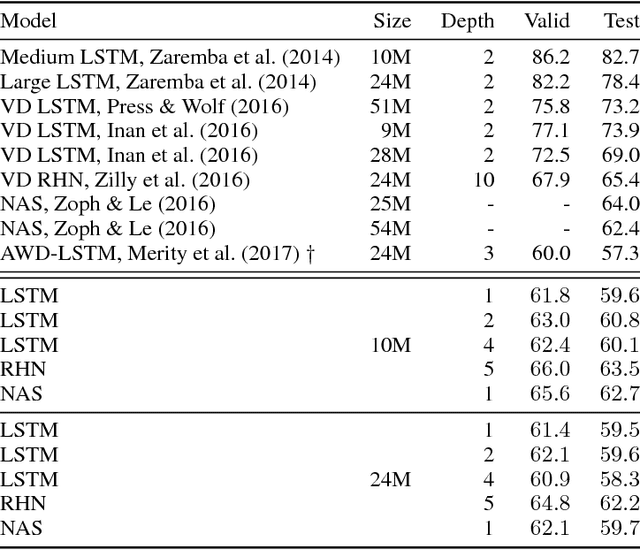
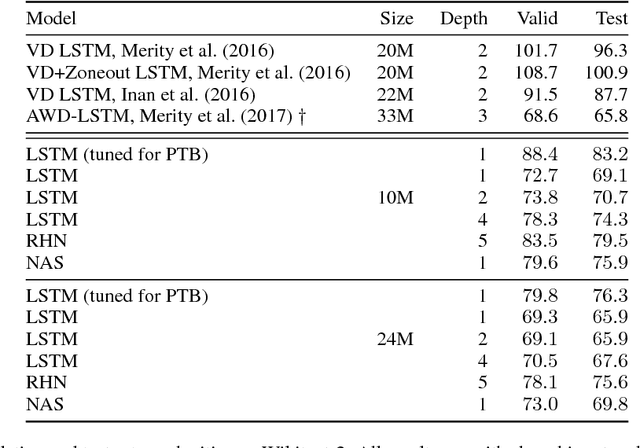
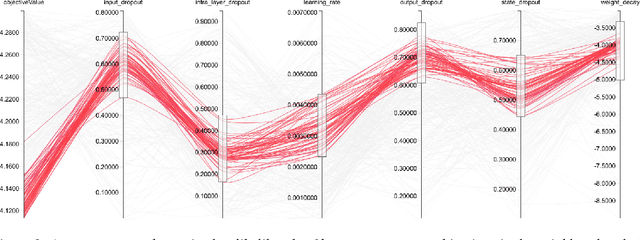
Ongoing innovations in recurrent neural network architectures have provided a steady influx of apparently state-of-the-art results on language modelling benchmarks. However, these have been evaluated using differing code bases and limited computational resources, which represent uncontrolled sources of experimental variation. We reevaluate several popular architectures and regularisation methods with large-scale automatic black-box hyperparameter tuning and arrive at the somewhat surprising conclusion that standard LSTM architectures, when properly regularised, outperform more recent models. We establish a new state of the art on the Penn Treebank and Wikitext-2 corpora, as well as strong baselines on the Hutter Prize dataset.