 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Event Boundaries in Egocentric Activity Recognition from Photostreams
Sep 06, 2018
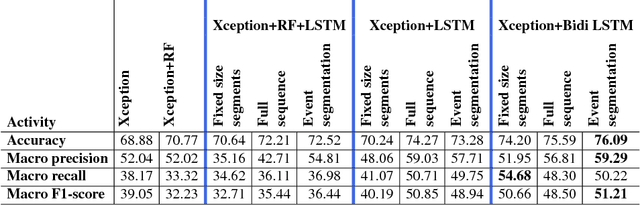

Event boundaries play a crucial role as a pre-processing step for detection, localization, and recognition tasks of human activities in videos. Typically, although their intrinsic subjectiveness, temporal bounds are provided manually as input for training action recognition algorithms. However, their role for activity recognition in the domain of egocentric photostreams has been so far neglected. In this paper, we provide insights of how automatically computed boundaries can impact activity recognition results in the emerging domain of egocentric photostreams. Furthermore, we collected a new annotated dataset acquired by 15 people by a wearable photo-camera and we used it to show the generalization capabilities of several deep learning based architectures to unseen users.
MACNet: Multi-scale Atrous Convolution Networks for Food Places Classification in Egocentric Photo-streams
Aug 29, 2018
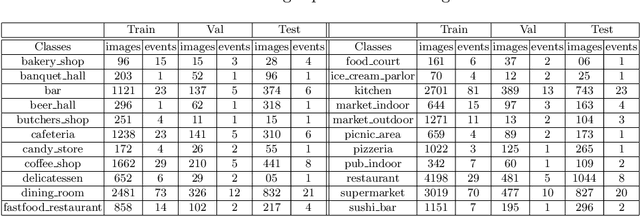
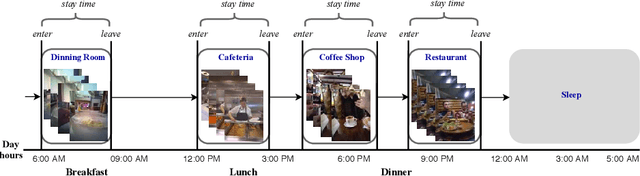
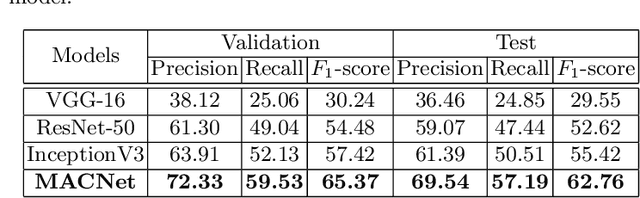
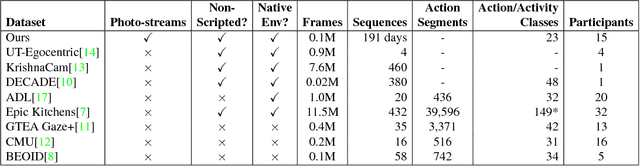
First-person (wearable) camera continually captures unscripted interactions of the camera user with objects, people, and scenes reflecting his personal and relational tendencies. One of the preferences of people is their interaction with food events. The regulation of food intake and its duration has a great importance to protect against diseases. Consequently, this work aims to develop a smart model that is able to determine the recurrences of a person on food places during a day. This model is based on a deep end-to-end model for automatic food places recognition by analyzing egocentric photo-streams. In this paper, we apply multi-scale Atrous convolution networks to extract the key features related to food places of the input images. The proposed model is evaluated on an in-house private dataset called "EgoFoodPlaces". Experimental results shows promising results of food places classification recognition in egocentric photo-streams.
CuisineNet: Food Attributes Classification using Multi-scale Convolution Network
Jun 08, 2018
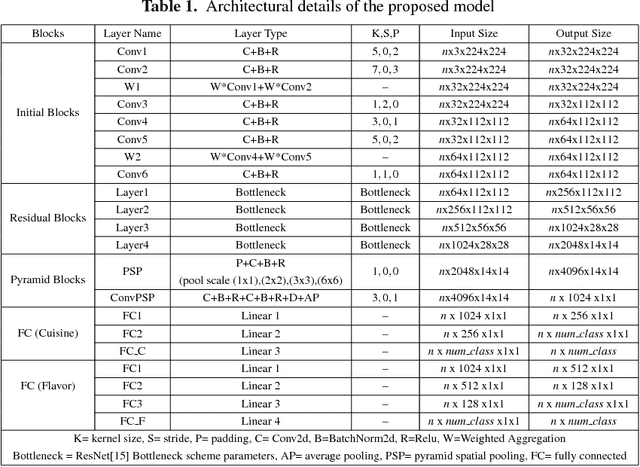
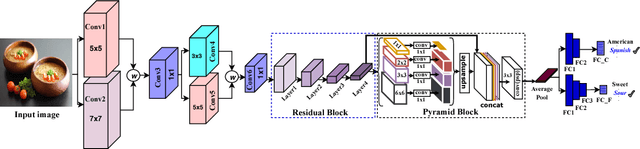
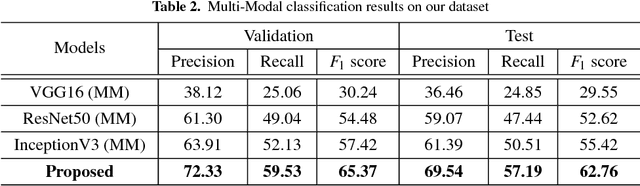
Diversity of food and its attributes represents the culinary habits of peoples from different countries. Thus, this paper addresses the problem of identifying food culture of people around the world and its flavor by classifying two main food attributes, cuisine and flavor. A deep learning model based on multi-scale convotuional networks is proposed for extracting more accurate features from input images. The aggregation of multi-scale convolution layers with different kernel size is also used for weighting the features results from different scales. In addition, a joint loss function based on Negative Log Likelihood (NLL) is used to fit the model probability to multi labeled classes for multi-modal classification task. Furthermore, this work provides a new dataset for food attributes, so-called Yummly48K, extracted from the popular food website, Yummly. Our model is assessed on the constructed Yummly48K dataset. The experimental results show that our proposed method yields 65% and 62% average F1 score on validation and test set which outperforming the state-of-the-art models.
SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks
May 31, 2018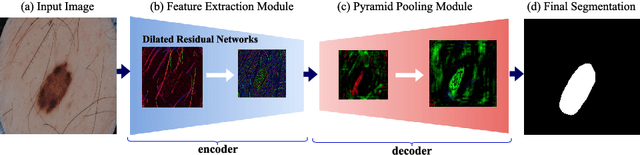
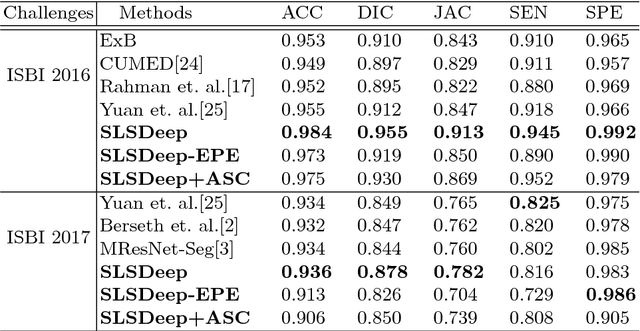
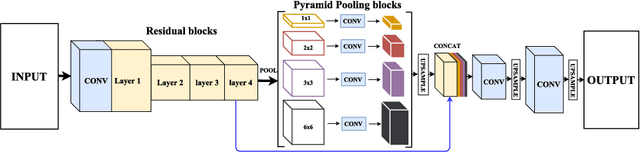
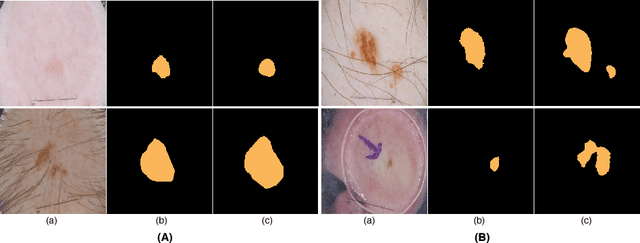
Skin lesion segmentation (SLS) in dermoscopic images is a crucial task for automated diagnosis of melanoma. In this paper, we present a robust deep learning SLS model, so-called SLSDeep, which is represented as an encoder-decoder network. The encoder network is constructed by dilated residual layers, in turn, a pyramid pooling network followed by three convolution layers is used for the decoder. Unlike the traditional methods employing a cross-entropy loss, we investigated a loss function by combining both Negative Log Likelihood (NLL) and End Point Error (EPE) to accurately segment the melanoma regions with sharp boundaries. The robustness of the proposed model was evaluated on two public databases: ISBI 2016 and 2017 for skin lesion analysis towards melanoma detection challenge. The proposed model outperforms the state-of-the-art methods in terms of segmentation accuracy. Moreover, it is capable to segment more than $100$ images of size 384x384 per second on a recent GPU.
Batch-based Activity Recognition from Egocentric Photo-Streams Revisited
May 09, 2018
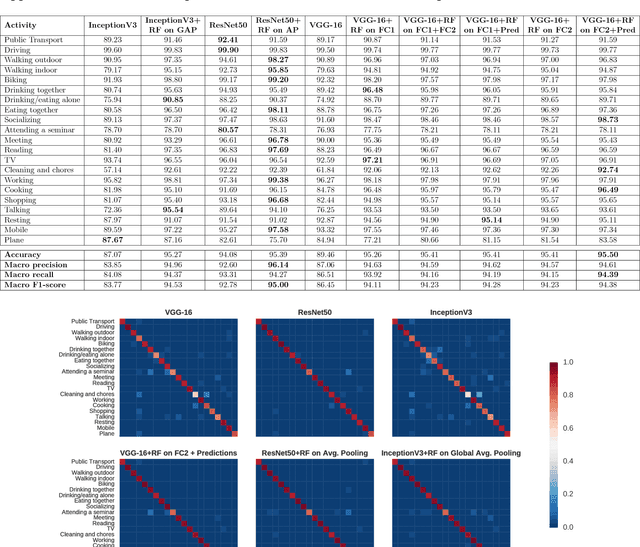
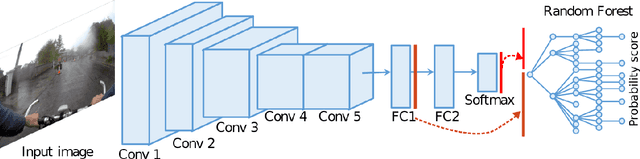
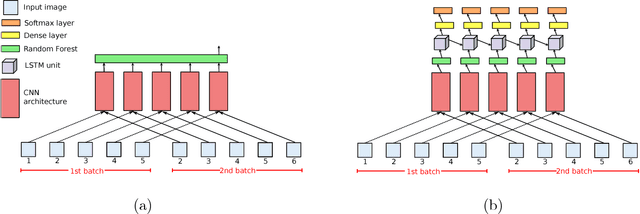
Wearable cameras can gather large a\-mounts of image data that provide rich visual information about the daily activities of the wearer. Motivated by the large number of health applications that could be enabled by the automatic recognition of daily activities, such as lifestyle characterization for habit improvement, context-aware personal assistance and tele-rehabilitation services, we propose a system to classify 21 daily activities from photo-streams acquired by a wearable photo-camera. Our approach combines the advantages of a Late Fusion Ensemble strategy relying on convolutional neural networks at image level with the ability of recurrent neural networks to account for the temporal evolution of high level features in photo-streams without relying on event boundaries. The proposed batch-based approach achieved an overall accuracy of 89.85\%, outperforming state of the art end-to-end methodologies. These results were achieved on a dataset consists of 44,902 egocentric pictures from three persons captured during 26 days in average.
A picture is worth a thousand words but how to organize thousands of pictures?
Mar 15, 2018
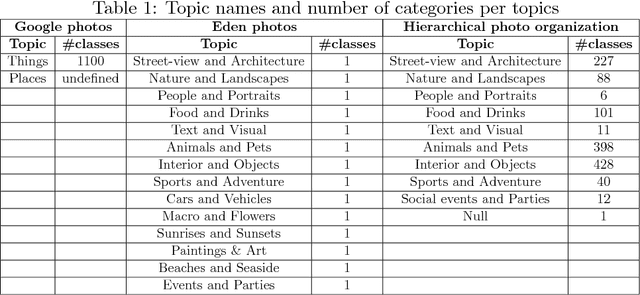

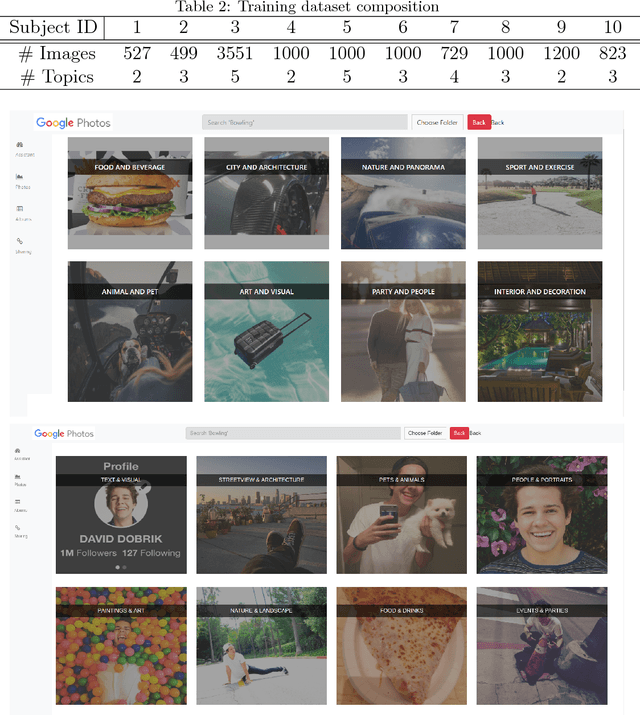
We live in a society where the large majority of the population has a camera-equipped smartphone. In addition, hard drives and cloud storage are getting cheaper and cheaper, leading to a tremendous growth in stored personal photos. Unlike photo collections captured by a digital camera, which typically are pre-processed by the user who organizes them into event-related folders, smartphone pictures are automatically stored in the cloud. As a consequence, photo collections captured by a smartphone are highly unstructured and because smartphones are ubiquitous, they present a larger variability compared to pictures captured by a digital camera. To solve the need of organizing large smartphone photo collections automatically, we propose here a new methodology for hierarchical photo organization into topics and topic-related categories. Our approach successfully estimates latent topics in the pictures by applying probabilistic Latent Semantic Analysis, and automatically assigns a name to each topic by relying on a lexical database. Topic-related categories are then estimated by using a set of topic-specific Convolutional Neuronal Networks. To validate our approach, we ensemble and make public a large dataset of more than 8,000 smartphone pictures from 10 persons. Experimental results demonstrate better user satisfaction with respect to state of the art solutions in terms of organization.
Towards social pattern characterization in egocentric photo-streams
Jan 09, 2018

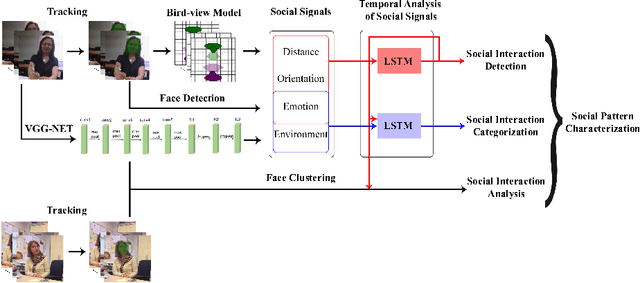
Following the increasingly popular trend of social interaction analysis in egocentric vision, this manuscript presents a comprehensive study for automatic social pattern characterization of a wearable photo-camera user, by relying on the visual analysis of egocentric photo-streams. The proposed framework consists of three major steps. The first step is to detect social interactions of the user where the impact of several social signals on the task is explored. The detected social events are inspected in the second step for categorization into different social meetings. These two steps act at event-level where each potential social event is modeled as a multi-dimensional time-series, whose dimensions correspond to a set of relevant features for each task, and LSTM is employed to classify the time-series. The last step of the framework is to characterize social patterns, which is essentially to infer the diversity and frequency of the social relations of the user through discovery of recurrences of the same people across the whole set of social events of the user. Experimental evaluation over a dataset acquired by 9 users demonstrates promising results on the task of social pattern characterization from egocentric photo-streams.
Grab, Pay and Eat: Semantic Food Detection for Smart Restaurants
Nov 14, 2017
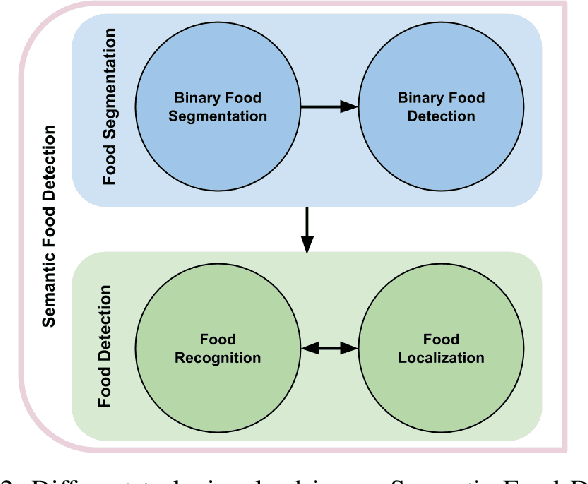
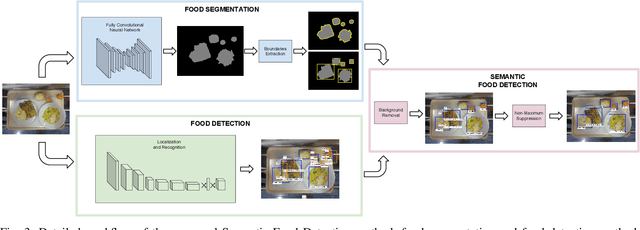

The increase in awareness of people towards their nutritional habits has drawn considerable attention to the field of automatic food analysis. Focusing on self-service restaurants environment, automatic food analysis is not only useful for extracting nutritional information from foods selected by customers, it is also of high interest to speed up the service solving the bottleneck produced at the cashiers in times of high demand. In this paper, we address the problem of automatic food tray analysis in canteens and restaurants environment, which consists in predicting multiple foods placed on a tray image. We propose a new approach for food analysis based on convolutional neural networks, we name Semantic Food Detection, which integrates in the same framework food localization, recognition and segmentation. We demonstrate that our method improves the state of the art food detection by a considerable margin on the public dataset UNIMIB2016 achieving about 90% in terms of F-measure, and thus provides a significant technological advance towards the automatic billing in restaurant environments.
Egocentric Video Description based on Temporally-Linked Sequences
Nov 09, 2017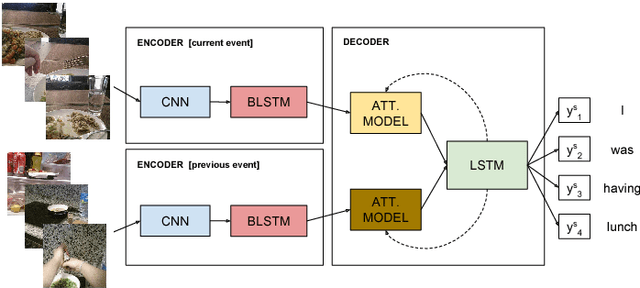

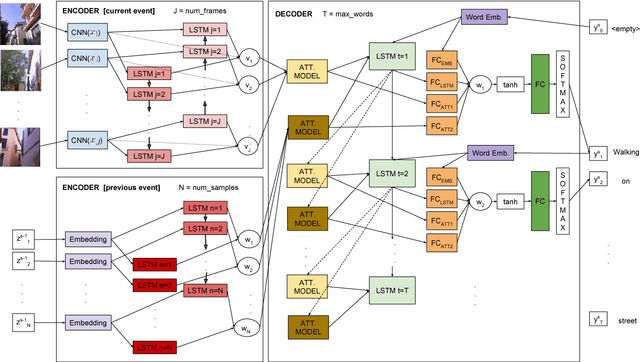

Egocentric vision consists in acquiring images along the day from a first person point-of-view using wearable cameras. The automatic analysis of this information allows to discover daily patterns for improving the quality of life of the user. A natural topic that arises in egocentric vision is storytelling, that is, how to understand and tell the story relying behind the pictures. In this paper, we tackle storytelling as an egocentric sequences description problem. We propose a novel methodology that exploits information from temporally neighboring events, matching precisely the nature of egocentric sequences. Furthermore, we present a new method for multimodal data fusion consisting on a multi-input attention recurrent network. We also publish the first dataset for egocentric image sequences description, consisting of 1,339 events with 3,991 descriptions, from 55 days acquired by 11 people. Furthermore, we prove that our proposal outperforms classical attentional encoder-decoder methods for video description.
Social Style Characterization from Egocentric Photo-streams
Sep 18, 2017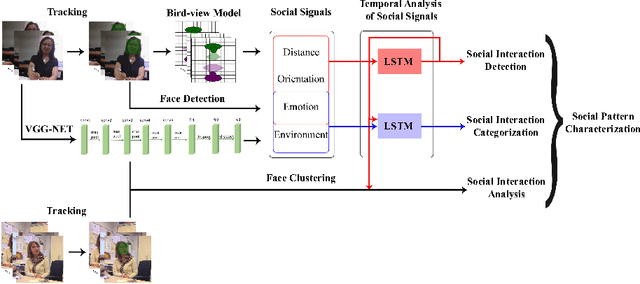
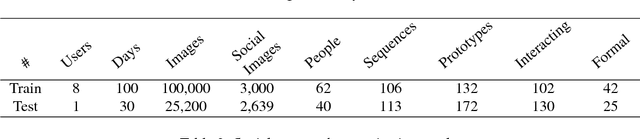

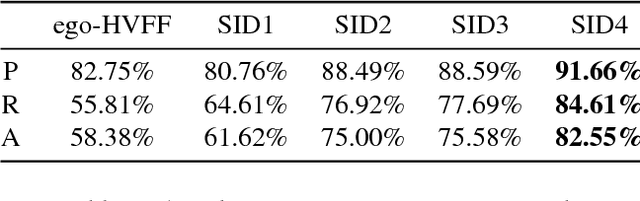
This paper proposes a system for automatic social pattern characterization using a wearable photo-camera. The proposed pipeline consists of three major steps. First, detection of people with whom the camera wearer interacts and, second, categorization of the detected social interactions into formal and informal. These two steps act at event-level where each potential social event is modeled as a multi-dimensional time-series, whose dimensions correspond to a set of relevant features for each task, and a LSTM network is employed for time-series classification. In the last step, recurrences of the same person across the whole set of social interactions are clustered to achieve a comprehensive understanding of the diversity and frequency of the social relations of the user. Experiments over a dataset acquired by a user wearing a photo-camera during a month show promising results on the task of social pattern characterization from egocentric photo-streams.