 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Attention for Slate Markov Decision Processes with High-Dimensional States and Actions
Dec 16, 2015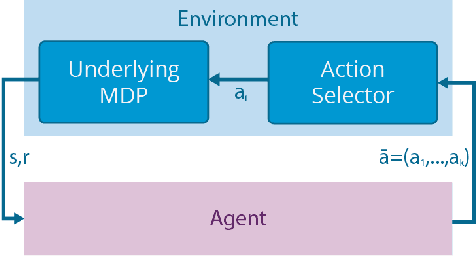
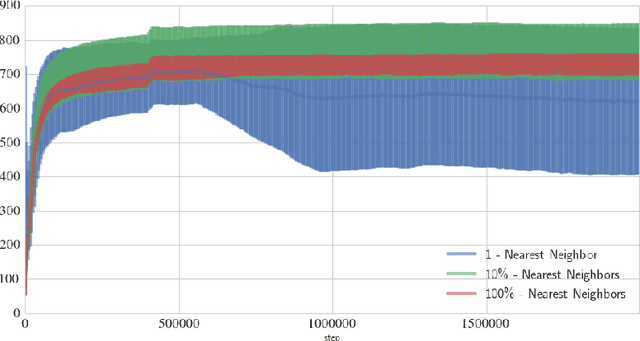
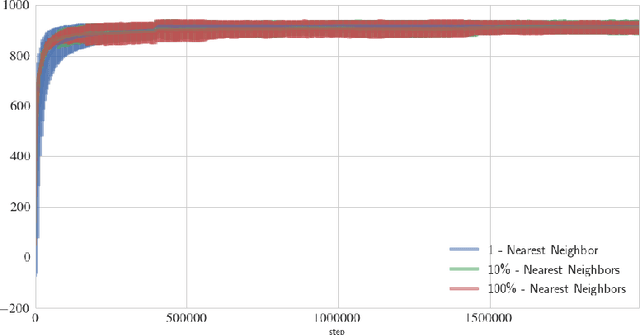
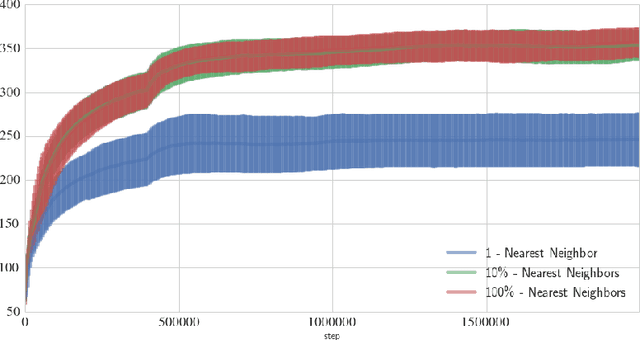
Many real-world problems come with action spaces represented as feature vectors. Although high-dimensional control is a largely unsolved problem, there has recently been progress for modest dimensionalities. Here we report on a successful attempt at addressing problems of dimensionality as high as $2000$, of a particular form. Motivated by important applications such as recommendation systems that do not fit the standard reinforcement learning frameworks, we introduce Slate Markov Decision Processes (slate-MDPs). A Slate-MDP is an MDP with a combinatorial action space consisting of slates (tuples) of primitive actions of which one is executed in an underlying MDP. The agent does not control the choice of this executed action and the action might not even be from the slate, e.g., for recommendation systems for which all recommendations can be ignored. We use deep Q-learning based on feature representations of both the state and action to learn the value of whole slates. Unlike existing methods, we optimize for both the combinatorial and sequential aspects of our tasks. The new agent's superiority over agents that either ignore the combinatorial or sequential long-term value aspect is demonstrated on a range of environments with dynamics from a real-world recommendation system. Further, we use deep deterministic policy gradients to learn a policy that for each position of the slate, guides attention towards the part of the action space in which the value is the highest and we only evaluate actions in this area. The attention is used within a sequentially greedy procedure leveraging submodularity. Finally, we show how introducing risk-seeking can dramatically improve the agents performance and ability to discover more far reaching strategies.
The Sample-Complexity of General Reinforcement Learning
Aug 22, 2013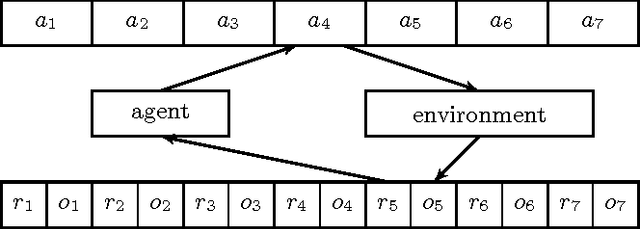
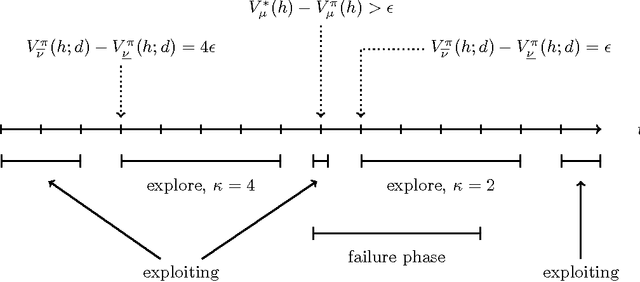
We present a new algorithm for general reinforcement learning where the true environment is known to belong to a finite class of N arbitrary models. The algorithm is shown to be near-optimal for all but O(N log^2 N) time-steps with high probability. Infinite classes are also considered where we show that compactness is a key criterion for determining the existence of uniform sample-complexity bounds. A matching lower bound is given for the finite case.
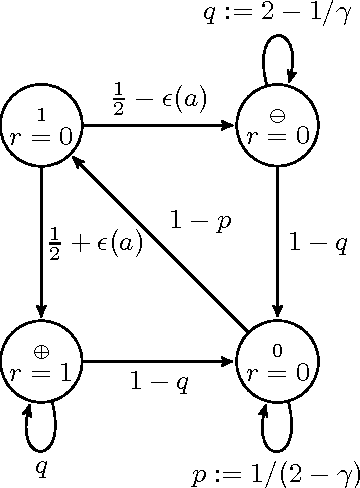
On Nicod's Condition, Rules of Induction and the Raven Paradox
Jul 16, 2013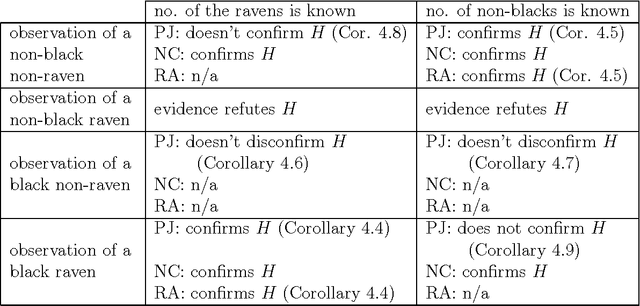
Philosophers writing about the ravens paradox often note that Nicod's Condition (NC) holds given some set of background information, and fails to hold against others, but rarely go any further. That is, it is usually not explored which background information makes NC true or false. The present paper aims to fill this gap. For us, "(objective) background knowledge" is restricted to information that can be expressed as probability events. Any other configuration is regarded as being subjective and a property of the a priori probability distribution. We study NC in two specific settings. In the first case, a complete description of some individuals is known, e.g. one knows of each of a group of individuals whether they are black and whether they are ravens. In the second case, the number of individuals having a particular property is given, e.g. one knows how many ravens or how many black things there are (in the relevant population). While some of the most famous answers to the paradox are measure-dependent, our discussion is not restricted to any particular probability measure. Our most interesting result is that in the second setting, NC violates a simple kind of inductive inference (namely projectability). Since relative to NC, this latter rule is more closely related to, and more directly justified by our intuitive notion of inductive reasoning, this tension makes a case against the plausibility of NC. In the end, we suggest that the informal representation of NC may seem to be intuitively plausible because it can easily be mistaken for reasoning by analogy.
Concentration and Confidence for Discrete Bayesian Sequence Predictors
Jun 29, 2013
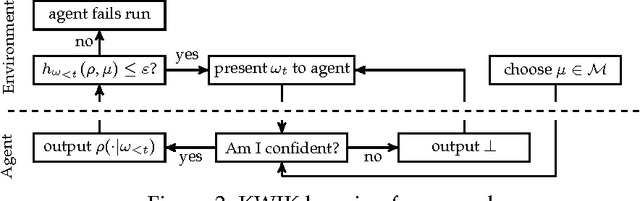
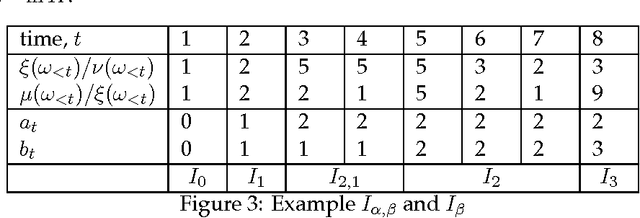
Bayesian sequence prediction is a simple technique for predicting future symbols sampled from an unknown measure on infinite sequences over a countable alphabet. While strong bounds on the expected cumulative error are known, there are only limited results on the distribution of this error. We prove tight high-probability bounds on the cumulative error, which is measured in terms of the Kullback-Leibler (KL) divergence. We also consider the problem of constructing upper confidence bounds on the KL and Hellinger errors similar to those constructed from Hoeffding-like bounds in the i.i.d. case. The new results are applied to show that Bayesian sequence prediction can be used in the Knows What It Knows (KWIK) framework with bounds that match the state-of-the-art.
Optimistic Agents are Asymptotically Optimal
Sep 29, 2012We use optimism to introduce generic asymptotically optimal reinforcement learning agents. They achieve, with an arbitrary finite or compact class of environments, asymptotically optimal behavior. Furthermore, in the finite deterministic case we provide finite error bounds.
* 13 LaTeX pages
Adaptive Context Tree Weighting
Jan 10, 2012

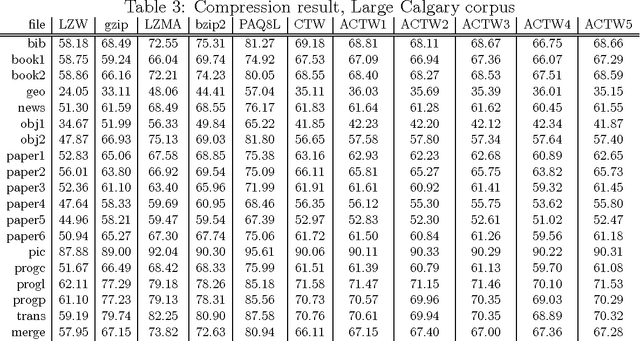
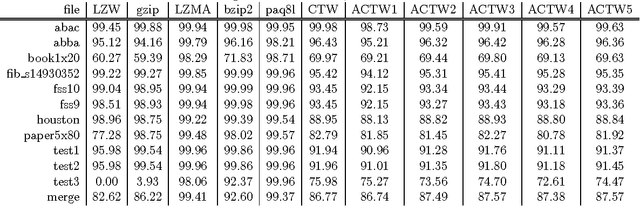
We describe an adaptive context tree weighting (ACTW) algorithm, as an extension to the standard context tree weighting (CTW) algorithm. Unlike the standard CTW algorithm, which weights all observations equally regardless of the depth, ACTW gives increasing weight to more recent observations, aiming to improve performance in cases where the input sequence is from a non-stationary distribution. Data compression results show ACTW variants improving over CTW on merged files from standard compression benchmark tests while never being significantly worse on any individual file.
Principles of Solomonoff Induction and AIXI
Nov 25, 2011We identify principles characterizing Solomonoff Induction by demands on an agent's external behaviour. Key concepts are rationality, computability, indifference and time consistency. Furthermore, we discuss extensions to the full AI case to derive AIXI.
* 14 LaTeX pages
Feature Reinforcement Learning In Practice
Aug 18, 2011
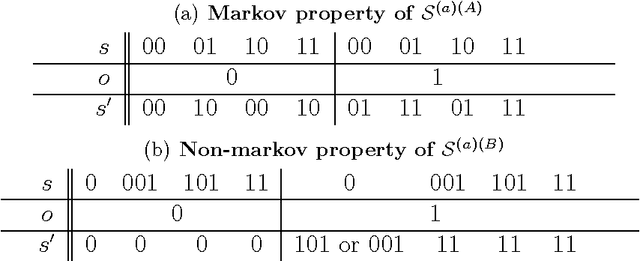

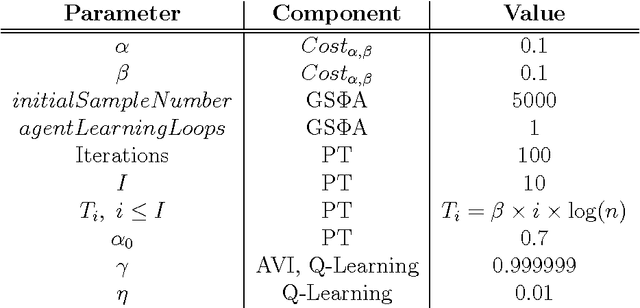
Following a recent surge in using history-based methods for resolving perceptual aliasing in reinforcement learning, we introduce an algorithm based on the feature reinforcement learning framework called PhiMDP. To create a practical algorithm we devise a stochastic search procedure for a class of context trees based on parallel tempering and a specialized proposal distribution. We provide the first empirical evaluation for PhiMDP. Our proposed algorithm achieves superior performance to the classical U-tree algorithm and the recent active-LZ algorithm, and is competitive with MC-AIXI-CTW that maintains a bayesian mixture over all context trees up to a chosen depth.We are encouraged by our ability to compete with this sophisticated method using an algorithm that simply picks one single model, and uses Q-learning on the corresponding MDP. Our PhiMDP algorithm is much simpler, yet consumes less time and memory. These results show promise for our future work on attacking more complex and larger problems.
Axioms for Rational Reinforcement Learning
Jul 27, 2011We provide a formal, simple and intuitive theory of rational decision making including sequential decisions that affect the environment. The theory has a geometric flavor, which makes the arguments easy to visualize and understand. Our theory is for complete decision makers, which means that they have a complete set of preferences. Our main result shows that a complete rational decision maker implicitly has a probabilistic model of the environment. We have a countable version of this result that brings light on the issue of countable vs finite additivity by showing how it depends on the geometry of the space which we have preferences over. This is achieved through fruitfully connecting rationality with the Hahn-Banach Theorem. The theory presented here can be viewed as a formalization and extension of the betting odds approach to probability of Ramsey and De Finetti.
* 16 LaTeX pages
Consistency of Feature Markov Processes
Jul 13, 2010We are studying long term sequence prediction (forecasting). We approach this by investigating criteria for choosing a compact useful state representation. The state is supposed to summarize useful information from the history. We want a method that is asymptotically consistent in the sense it will provably eventually only choose between alternatives that satisfy an optimality property related to the used criterion. We extend our work to the case where there is side information that one can take advantage of and, furthermore, we briefly discuss the active setting where an agent takes actions to achieve desirable outcomes.
* 16 LaTeX pages