 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Need for a Statistical Foundation in Scenario-Based Testing of Autonomous Vehicles
May 04, 2025
Scenario-based testing has emerged as a common method for autonomous vehicles (AVs) safety, offering a more efficient alternative to mile-based testing by focusing on high-risk scenarios. However, fundamental questions persist regarding its stopping rules, residual risk estimation, debug effectiveness, and the impact of simulation fidelity on safety claims. This paper argues that a rigorous statistical foundation is essential to address these challenges and enable rigorous safety assurance. By drawing parallels between AV testing and traditional software testing methodologies, we identify shared research gaps and reusable solutions. We propose proof-of-concept models to quantify the probability of failure per scenario (pfs) and evaluate testing effectiveness under varying conditions. Our analysis reveals that neither scenario-based nor mile-based testing universally outperforms the other. Furthermore, we introduce Risk Estimation Fidelity (REF), a novel metric to certify the alignment of synthetic and real-world testing outcomes, ensuring simulation-based safety claims are statistically defensible.
Evaluation of Confidence-based Ensembling in Deep Learning Image Classification
Mar 03, 2023



Ensembling is a successful technique to improve the performance of machine learning (ML) models. Conf-Ensemble is an adaptation to Boosting to create ensembles based on model confidence instead of model errors to better classify difficult edge-cases. The key idea is to create successive model experts for samples that were difficult (not necessarily incorrectly classified) by the preceding model. This technique has been shown to provide better results than boosting in binary-classification with a small feature space (~80 features). In this paper, we evaluate the Conf-Ensemble approach in the much more complex task of image classification with the ImageNet dataset (224x224x3 features with 1000 classes). Image classification is an important benchmark for AI-based perception and thus it helps to assess if this method can be used in safety-critical applications using ML ensembles. Our experiments indicate that in a complex multi-label classification task, the expected benefit of specialization on complex input samples cannot be achieved with a small sample set, i.e., a good classifier seems to rely on very complex feature analysis that cannot be well trained on just a limited subset of "difficult samples". We propose an improvement to Conf-Ensemble to increase the number of samples fed to successive ensemble members, and a three-member Conf-Ensemble using this improvement was able to surpass a single model in accuracy, although the amount is not significant. Our findings shed light on the limits of the approach and the non-triviality of harnessing big data.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 2
Feb 28, 2020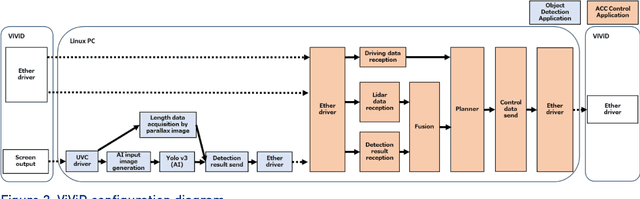
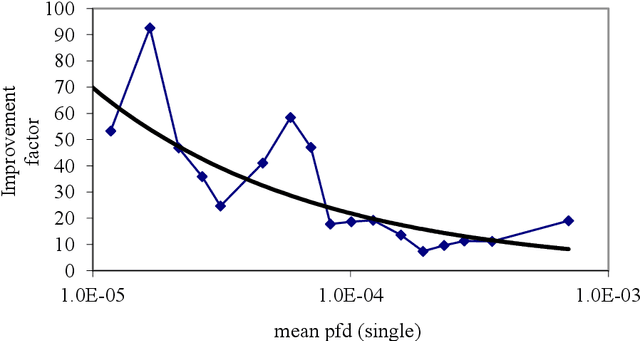

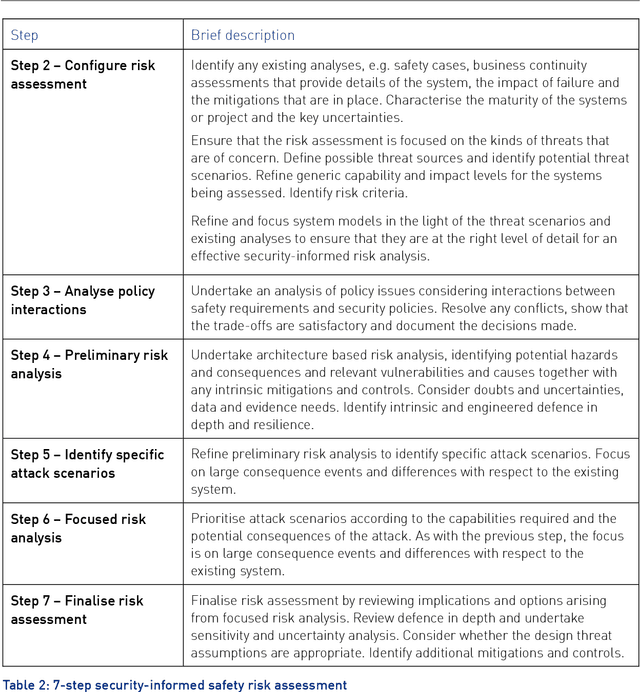
This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. This report is Part 2 and discusses: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 1
Feb 28, 2020This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. Part 2: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.