 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation and Recovery of Superquadric Models using Convolutional Neural Networks
Jan 28, 2020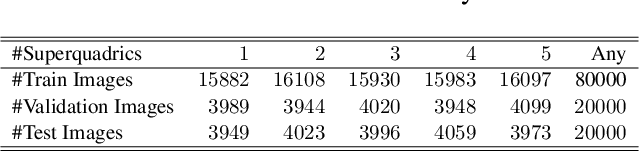

In this paper we address the problem of representing 3D visual data with parameterized volumetric shape primitives. Specifically, we present a (two-stage) approach built around convolutional neural networks (CNNs) capable of segmenting complex depth scenes into the simpler geometric structures that can be represented with superquadric models. In the first stage, our approach uses a Mask RCNN model to identify superquadric-like structures in depth scenes and then fits superquadric models to the segmented structures using a specially designed CNN regressor. Using our approach we are able to describe complex structures with a small number of interpretable parameters. We evaluated the proposed approach on synthetic as well as real-world depth data and show that our solution does not only result in competitive performance in comparison to the state-of-the-art, but is able to decompose scenes into a number of superquadric models at a fraction of the time required by competing approaches. We make all data and models used in the paper available from https://lmi.fe.uni-lj.si/en/research/resources/sq-seg.
Simultaneous regression and feature learning for facial landmarking
Apr 24, 2019
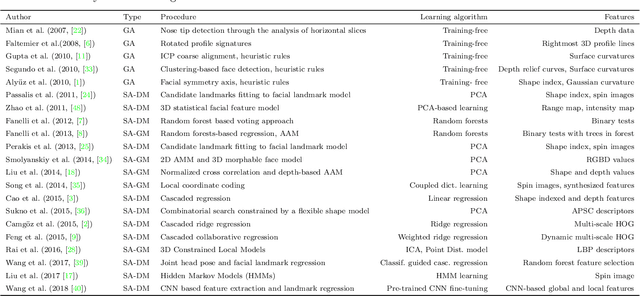
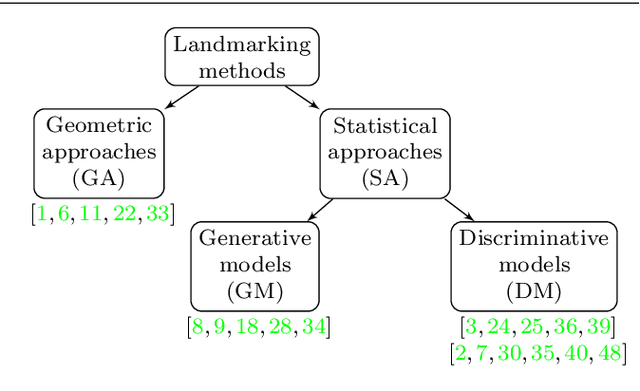
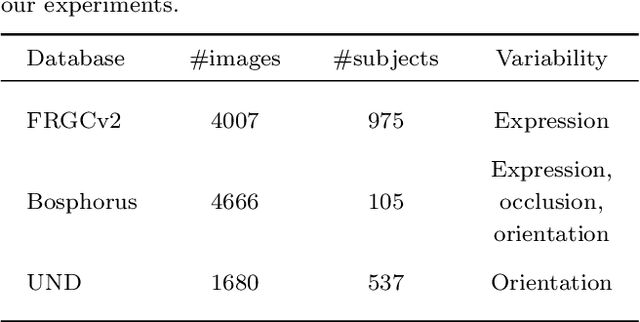
Face alignment (or facial landmarking) is an important task in many face-related applications, ranging from registration, tracking and animation to higher-level classification problems such as face, expression or attribute recognition. While several solutions have been presented in the literature for this task so far, reliably locating salient facial features across a wide range of posses still remains challenging. To address this issue, we propose in this paper a novel method for automatic facial landmark localization in 3D face data designed specifically to address appearance variability caused by significant pose variations. Our method builds on recent cascaded-regression-based methods to facial landmarking and uses a gating mechanism to incorporate multiple linear cascaded regression models each trained for a limited range of poses into a single powerful landmarking model capable of processing arbitrary posed input data. We develop two distinct approaches around the proposed gating mechanism: i) the first uses a gated multiple ridge descent (GRID) mechanism in conjunction with established (hand-crafted) HOG features for face alignment and achieves state-of-the-art landmarking performance across a wide range of facial poses, ii) the second simultaneously learns multiple-descent directions as well as binary features (SMUF) that are optimal for the alignment tasks and in addition to competitive landmarking results also ensures extremely rapid processing. We evaluate both approaches in rigorous experiments on several popular datasets of 3D face images, i.e., the FRGCv2 and Bosphorus 3D Face datasets and image collections F and G from the University of Notre Dame. The results of our evaluation show that both approaches are competitive in comparison to the state-of-the-art, while exhibiting considerable robustness to pose variations.
Recovery of Superquadrics from Range Images using Deep Learning: A Preliminary Study
Apr 13, 2019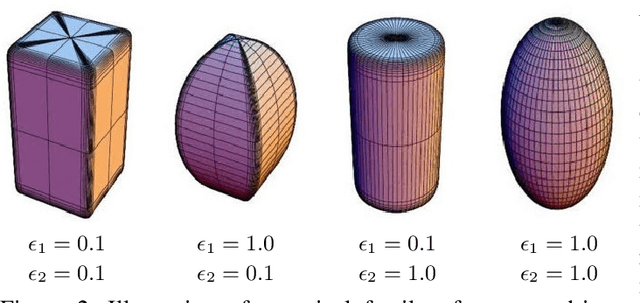
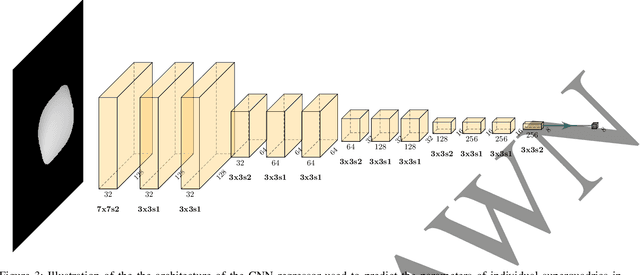

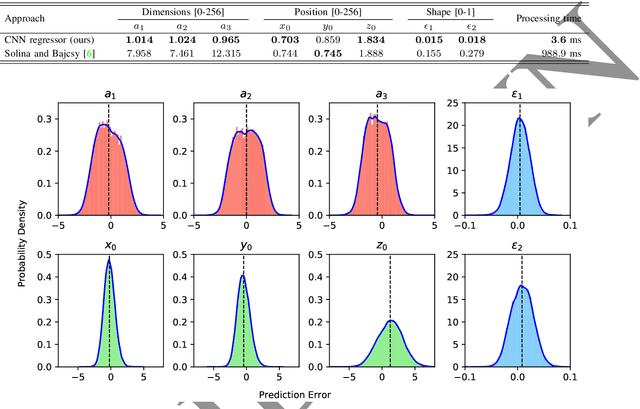
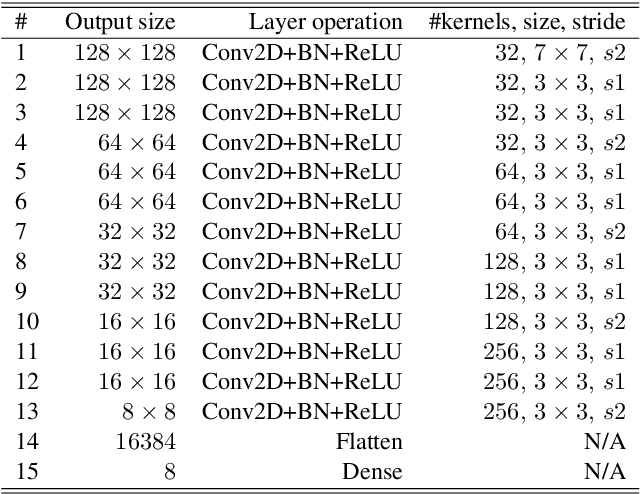
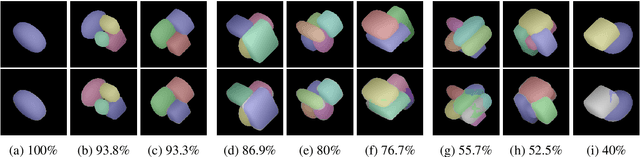
It has been a longstanding goal in computer vision to describe the 3D physical space in terms of parameterized volumetric models that would allow autonomous machines to understand and interact with their surroundings. Such models are typically motivated by human visual perception and aim to represents all elements of the physical word ranging from individual objects to complex scenes using a small set of parameters. One of the de facto stadards to approach this problem are superquadrics - volumetric models that define various 3D shape primitives and can be fitted to actual 3D data (either in the form of point clouds or range images). However, existing solutions to superquadric recovery involve costly iterative fitting procedures, which limit the applicability of such techniques in practice. To alleviate this problem, we explore in this paper the possibility to recover superquadrics from range images without time consuming iterative parameter estimation techniques by using contemporary deep-learning models, more specifically, convolutional neural networks (CNNs). We pose the superquadric recovery problem as a regression task and develop a CNN regressor that is able to estimate the parameters of a superquadric model from a given range image. We train the regressor on a large set of synthetic range images, each containing a single (unrotated) superquadric shape and evaluate the learned model in comparaitve experiments with the current state-of-the-art. Additionally, we also present a qualitative analysis involving a dataset of real-world objects. The results of our experiments show that the proposed regressor not only outperforms the existing state-of-the-art, but also ensures a 270x faster execution time.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019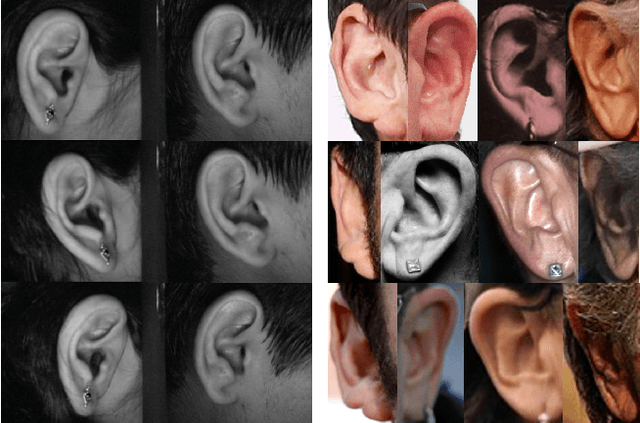

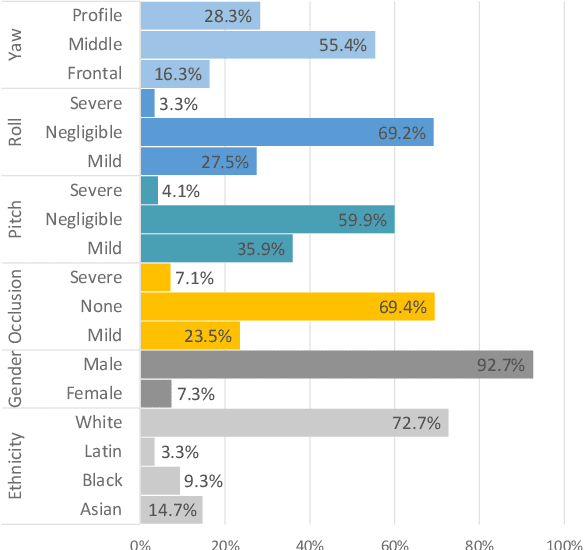
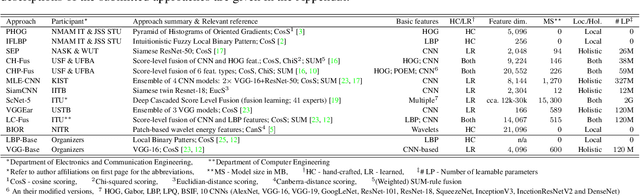
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.
Influence of segmentation on deep iris recognition performance
Jan 29, 2019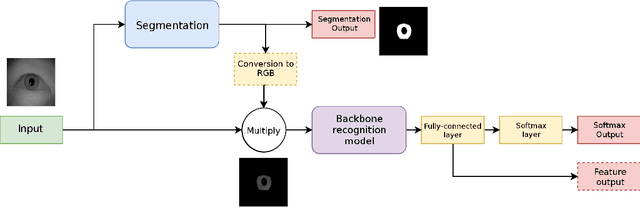
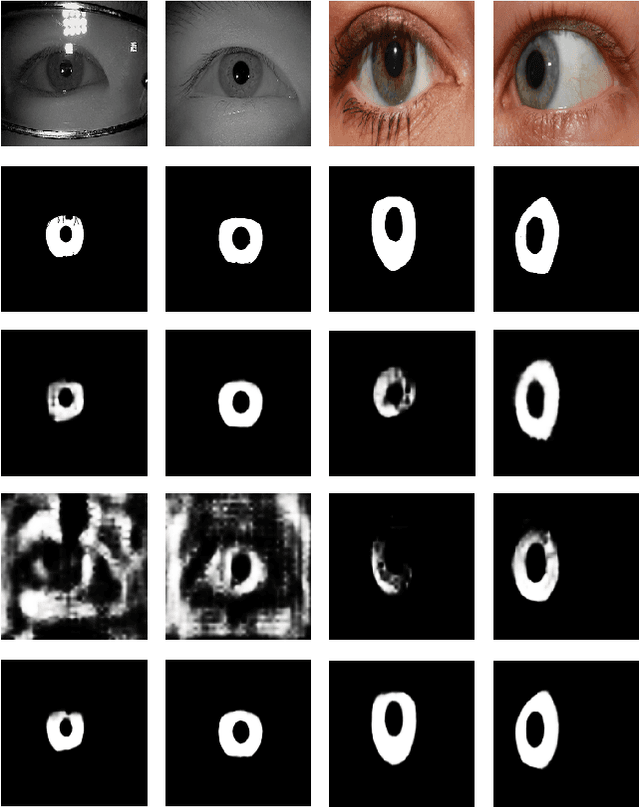
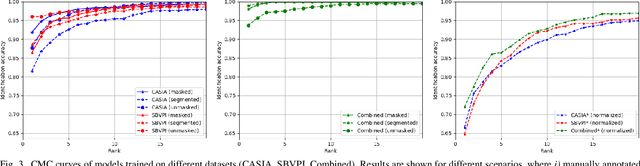
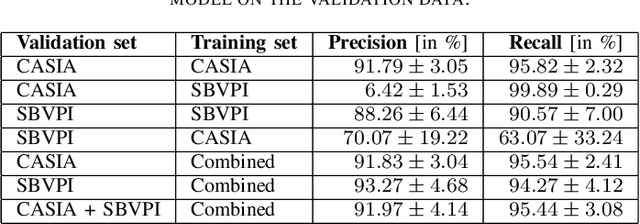
Despite the rise of deep learning in numerous areas of computer vision and image processing, iris recognition has not benefited considerably from these trends so far. Most of the existing research on deep iris recognition is focused on new models for generating discriminative and robust iris representations and relies on methodologies akin to traditional iris recognition pipelines. Hence, the proposed models do not approach iris recognition in an end-to-end manner, but rather use standard heuristic iris segmentation (and unwrapping) techniques to produce normalized inputs for the deep learning models. However, because deep learning is able to model very complex data distributions and nonlinear data changes, an obvious question arises. How important is the use of traditional segmentation methods in a deep learning setting? To answer this question, we present in this paper an empirical analysis of the impact of iris segmentation on the performance of deep learning models using a simple two stage pipeline consisting of a segmentation and a recognition step. We evaluate how the accuracy of segmentation influences recognition performance but also examine if segmentation is needed at all. We use the CASIA Thousand and SBVPI datasets for the experiments and report several interesting findings.
Training Convolutional Neural Networks with Limited Training Data for Ear Recognition in the Wild
Nov 27, 2017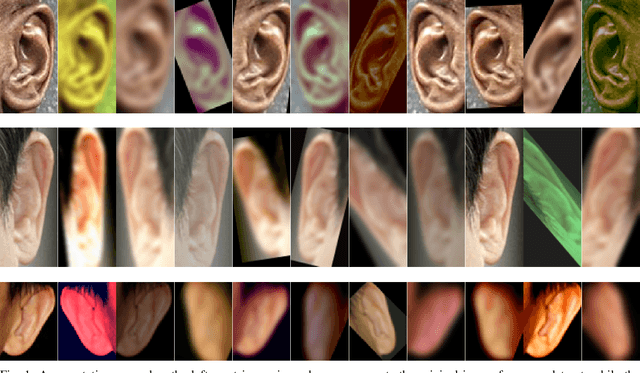
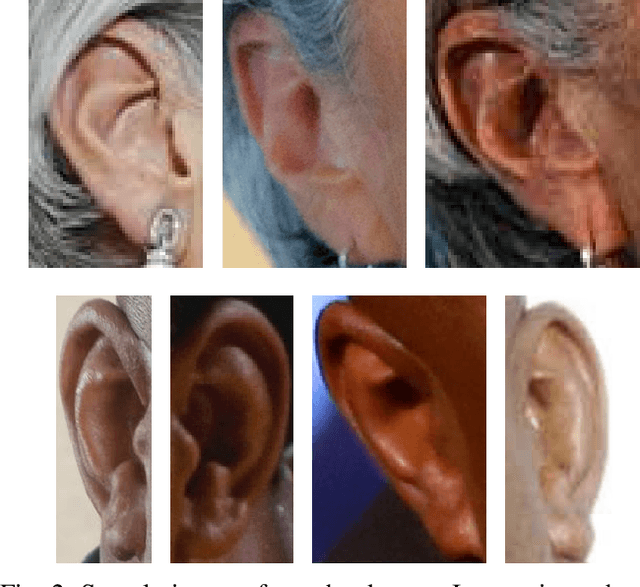
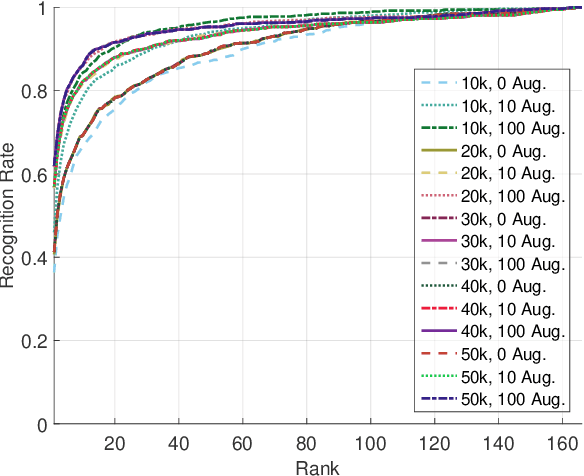
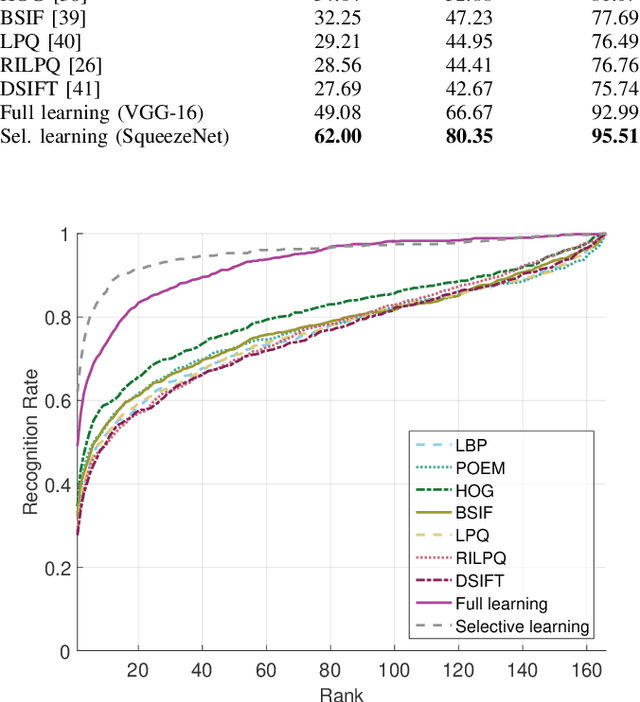
Identity recognition from ear images is an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes ear recognition technology an appealing choice for surveillance and security applications as well as related application domains. In contrast to other biometric modalities, where large datasets captured in uncontrolled settings are readily available, datasets of ear images are still limited in size and mostly of laboratory-like quality. As a consequence, ear recognition technology has not benefited yet from advances in deep learning and convolutional neural networks (CNNs) and is still lacking behind other modalities that experienced significant performance gains owing to deep recognition technology. In this paper we address this problem and aim at building a CNNbased ear recognition model. We explore different strategies towards model training with limited amounts of training data and show that by selecting an appropriate model architecture, using aggressive data augmentation and selective learning on existing (pre-trained) models, we are able to learn an effective CNN-based model using a little more than 1300 training images. The result of our work is the first CNN-based approach to ear recognition that is also made publicly available to the research community. With our model we are able to improve on the rank one recognition rate of the previous state-of-the-art by more than 25% on a challenging dataset of ear images captured from the web (a.k.a. in the wild).
The Unconstrained Ear Recognition Challenge
Aug 23, 2017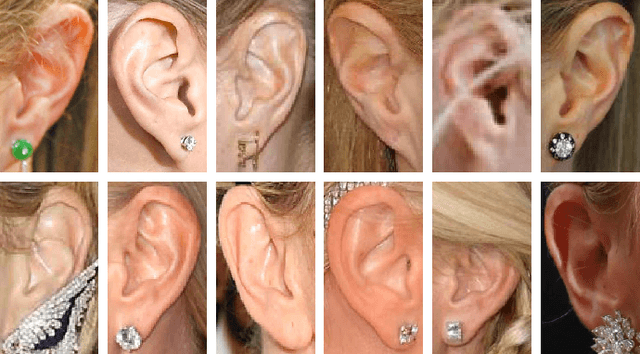


In this paper we present the results of the Unconstrained Ear Recognition Challenge (UERC), a group benchmarking effort centered around the problem of person recognition from ear images captured in uncontrolled conditions. The goal of the challenge was to assess the performance of existing ear recognition techniques on a challenging large-scale dataset and identify open problems that need to be addressed in the future. Five groups from three continents participated in the challenge and contributed six ear recognition techniques for the evaluation, while multiple baselines were made available for the challenge by the UERC organizers. A comprehensive analysis was conducted with all participating approaches addressing essential research questions pertaining to the sensitivity of the technology to head rotation, flipping, gallery size, large-scale recognition and others. The top performer of the UERC was found to ensure robust performance on a smaller part of the dataset (with 180 subjects) regardless of image characteristics, but still exhibited a significant performance drop when the entire dataset comprising 3,704 subjects was used for testing.
Face Deidentification with Generative Deep Neural Networks
Jul 28, 2017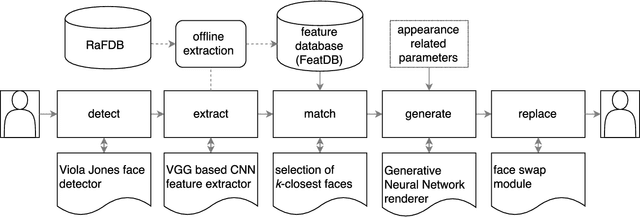
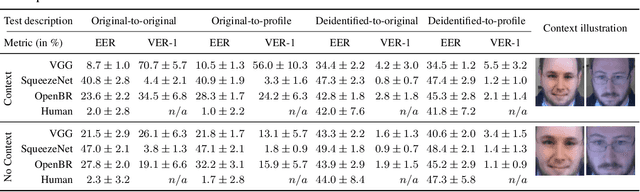

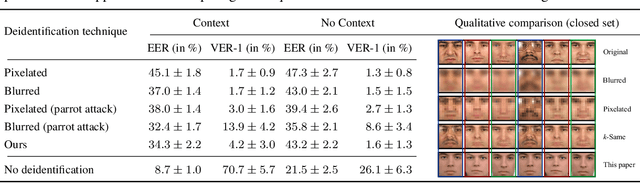
Face deidentification is an active topic amongst privacy and security researchers. Early deidentification methods relying on image blurring or pixelization were replaced in recent years with techniques based on formal anonymity models that provide privacy guaranties and at the same time aim at retaining certain characteristics of the data even after deidentification. The latter aspect is particularly important, as it allows to exploit the deidentified data in applications for which identity information is irrelevant. In this work we present a novel face deidentification pipeline, which ensures anonymity by synthesizing artificial surrogate faces using generative neural networks (GNNs). The generated faces are used to deidentify subjects in images or video, while preserving non-identity-related aspects of the data and consequently enabling data utilization. Since generative networks are very adaptive and can utilize a diverse set of parameters (pertaining to the appearance of the generated output in terms of facial expressions, gender, race, etc.), they represent a natural choice for the problem of face deidentification. To demonstrate the feasibility of our approach, we perform experiments using automated recognition tools and human annotators. Our results show that the recognition performance on deidentified images is close to chance, suggesting that the deidentification process based on GNNs is highly effective.
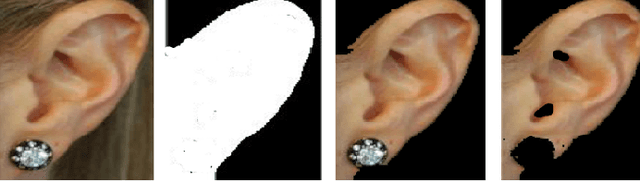
Pixel-wise Ear Detection with Convolutional Encoder-Decoder Networks
Feb 01, 2017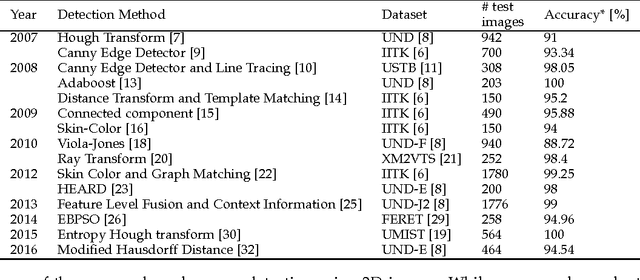
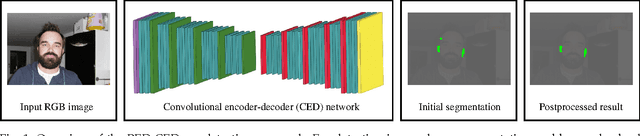
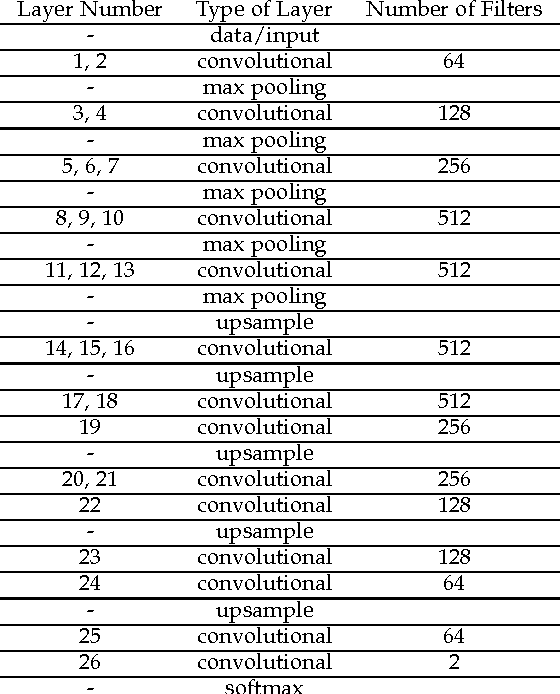
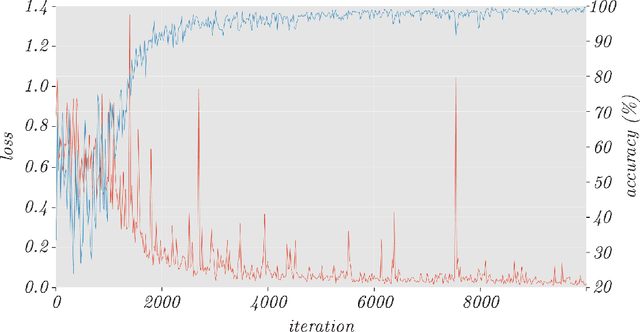
Object detection and segmentation represents the basis for many tasks in computer and machine vision. In biometric recognition systems the detection of the region-of-interest (ROI) is one of the most crucial steps in the overall processing pipeline, significantly impacting the performance of the entire recognition system. Existing approaches to ear detection, for example, are commonly susceptible to the presence of severe occlusions, ear accessories or variable illumination conditions and often deteriorate in their performance if applied on ear images captured in unconstrained settings. To address these shortcomings, we present in this paper a novel ear detection technique based on convolutional encoder-decoder networks (CEDs). For our technique, we formulate the problem of ear detection as a two-class segmentation problem and train a convolutional encoder-decoder network based on the SegNet architecture to distinguish between image-pixels belonging to either the ear or the non-ear class. The output of the network is then post-processed to further refine the segmentation result and return the final locations of the ears in the input image. Different from competing techniques from the literature, our approach does not simply return a bounding box around the detected ear, but provides detailed, pixel-wise information about the location of the ears in the image. Our experiments on a dataset gathered from the web (a.k.a. in the wild) show that the proposed technique ensures good detection results in the presence of various covariate factors and significantly outperforms the existing state-of-the-art.
Ear Recognition: More Than a Survey
Nov 18, 2016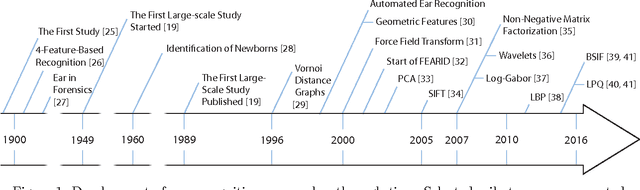
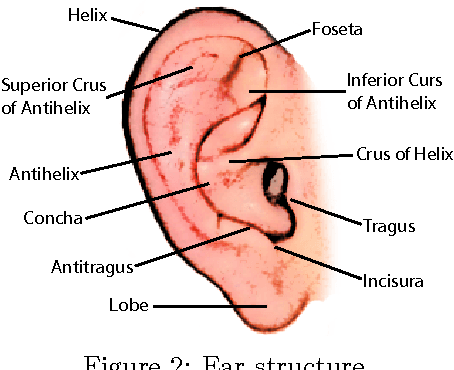
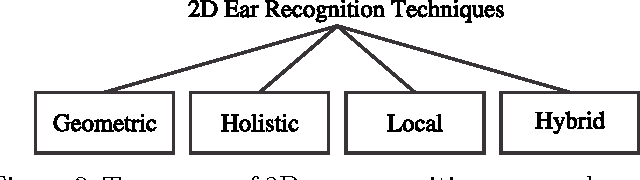
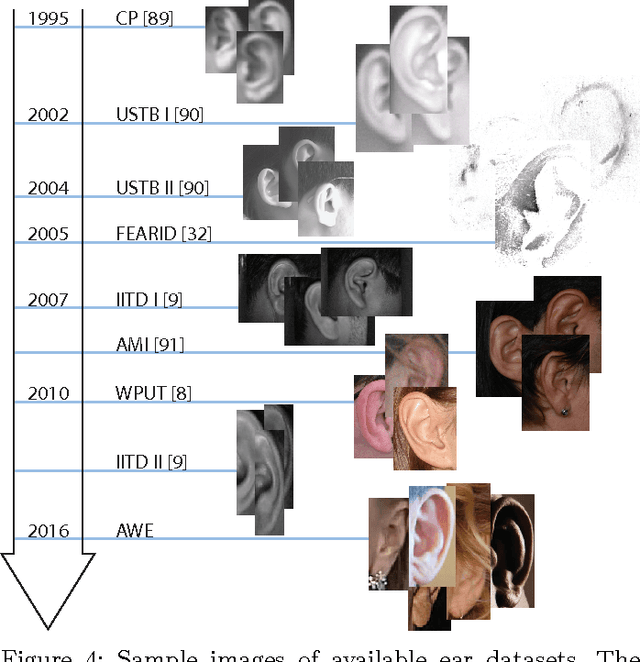
Automatic identity recognition from ear images represents an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes the technology an appealing choice for surveillance and security applications as well as other application domains. Significant contributions have been made in the field over recent years, but open research problems still remain and hinder a wider (commercial) deployment of the technology. This paper presents an overview of the field of automatic ear recognition (from 2D images) and focuses specifically on the most recent, descriptor-based methods proposed in this area. Open challenges are discussed and potential research directions are outlined with the goal of providing the reader with a point of reference for issues worth examining in the future. In addition to a comprehensive review on ear recognition technology, the paper also introduces a new, fully unconstrained dataset of ear images gathered from the web and a toolbox implementing several state-of-the-art techniques for ear recognition. The dataset and toolbox are meant to address some of the open issues in the field and are made publicly available to the research community.