 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021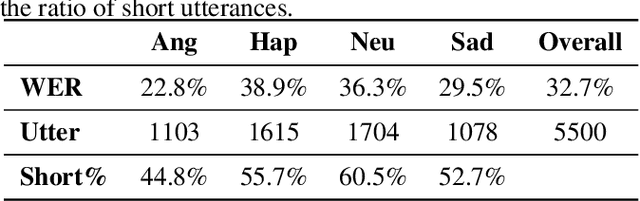
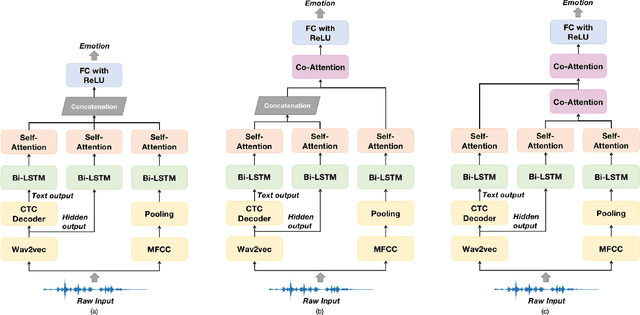
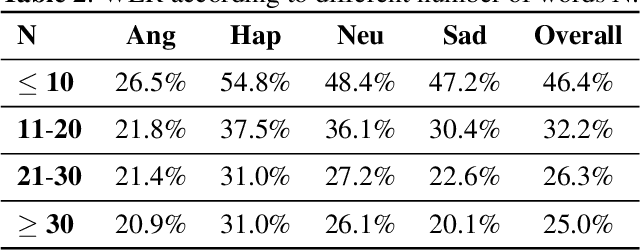

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.
It's not what you said, it's how you said it: discriminative perception of speech as a multichannel communication system
May 01, 2021
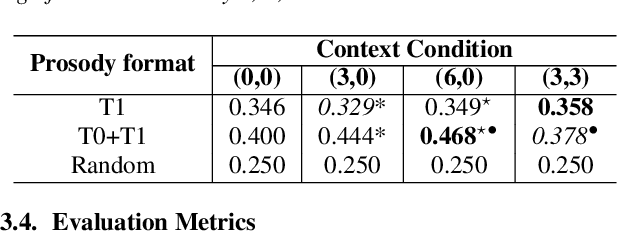
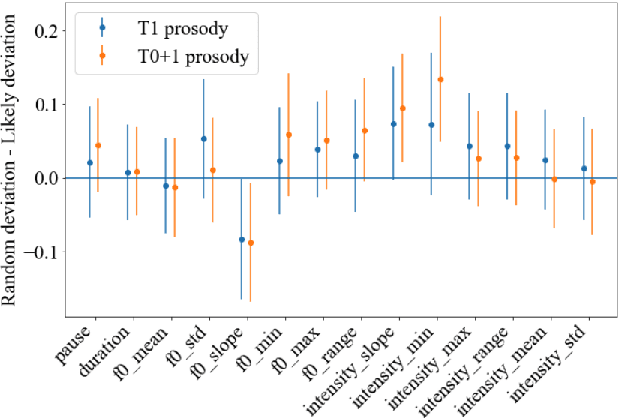
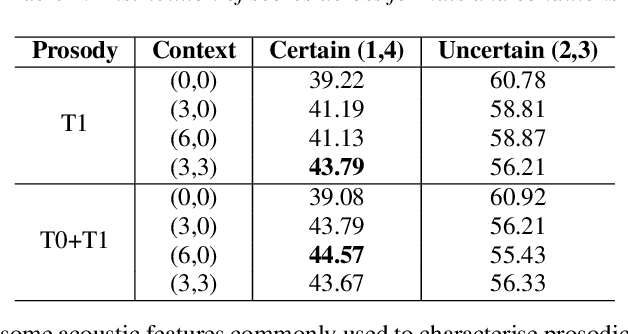
People convey information extremely effectively through spoken interaction using multiple channels of information transmission: the lexical channel of what is said, and the non-lexical channel of how it is said. We propose studying human perception of spoken communication as a means to better understand how information is encoded across these channels, focusing on the question 'What characteristics of communicative context affect listener's expectations of speech?'. To investigate this, we present a novel behavioural task testing whether listeners can discriminate between the true utterance in a dialogue and utterances sampled from other contexts with the same lexical content. We characterize how perception - and subsequent discriminative capability - is affected by different degrees of additional contextual information across both the lexical and non-lexical channel of speech. Results demonstrate that people can effectively discriminate between different prosodic realisations, that non-lexical context is informative, and that this channel provides more salient information than the lexical channel, highlighting the importance of the non-lexical channel in spoken interaction.
Segmenting Subtitles for Correcting ASR Segmentation Errors
Apr 16, 2021
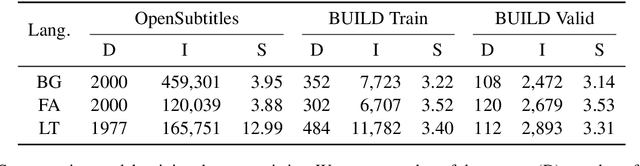

Typical ASR systems segment the input audio into utterances using purely acoustic information, which may not resemble the sentence-like units that are expected by conventional machine translation (MT) systems for Spoken Language Translation. In this work, we propose a model for correcting the acoustic segmentation of ASR models for low-resource languages to improve performance on downstream tasks. We propose the use of subtitles as a proxy dataset for correcting ASR acoustic segmentation, creating synthetic acoustic utterances by modeling common error modes. We train a neural tagging model for correcting ASR acoustic segmentation and show that it improves downstream performance on MT and audio-document cross-language information retrieval (CLIR).
Train your classifier first: Cascade Neural Networks Training from upper layers to lower layers
Feb 09, 2021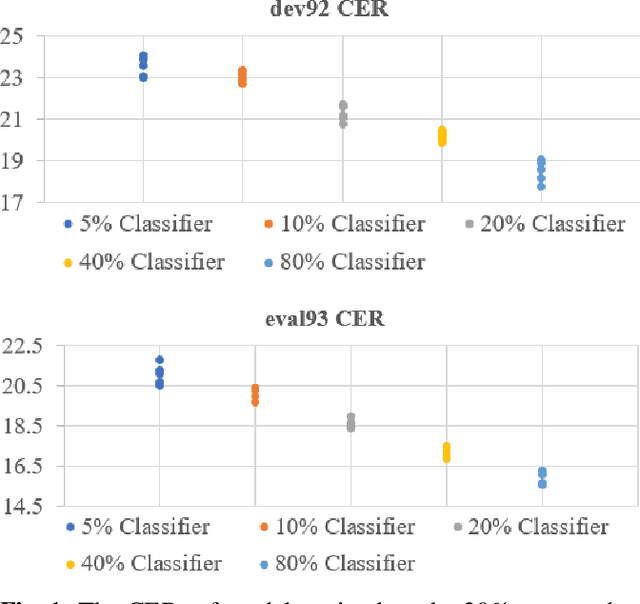
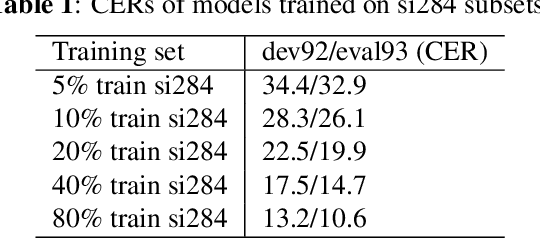
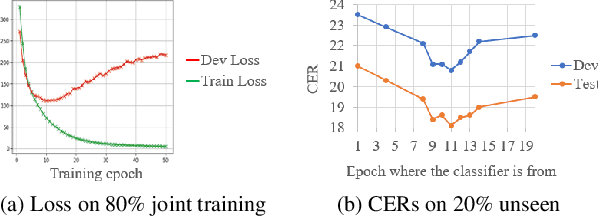
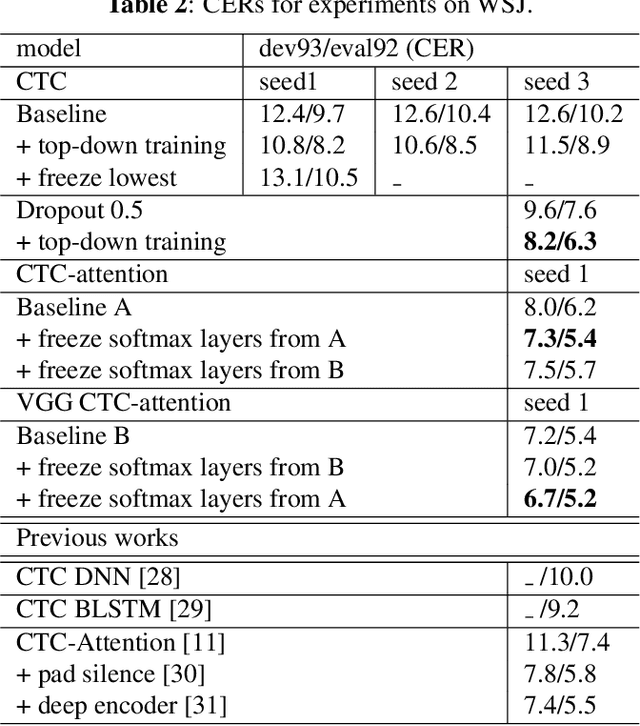
Although the lower layers of a deep neural network learn features which are transferable across datasets, these layers are not transferable within the same dataset. That is, in general, freezing the trained feature extractor (the lower layers) and retraining the classifier (the upper layers) on the same dataset leads to worse performance. In this paper, for the first time, we show that the frozen classifier is transferable within the same dataset. We develop a novel top-down training method which can be viewed as an algorithm for searching for high-quality classifiers. We tested this method on automatic speech recognition (ASR) tasks and language modelling tasks. The proposed method consistently improves recurrent neural network ASR models on Wall Street Journal, self-attention ASR models on Switchboard, and AWD-LSTM language models on WikiText-2.
Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning
Dec 10, 2020
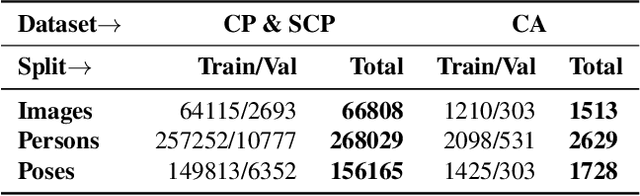

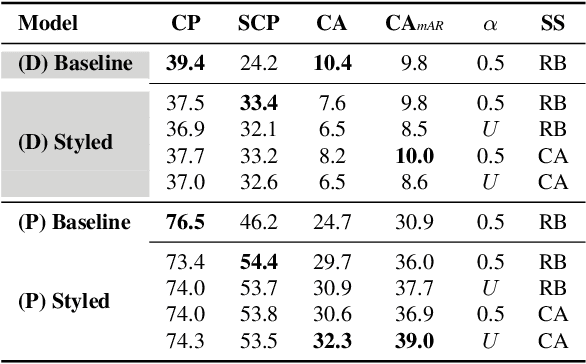
Human pose estimation (HPE) is a central part of understanding the visual narration and body movements of characters depicted in artwork collections, such as Greek vase paintings. Unfortunately, existing HPE methods do not generalise well across domains resulting in poorly recognized poses. Therefore, we propose a two step approach: (1) adapting a dataset of natural images of known person and pose annotations to the style of Greek vase paintings by means of image style-transfer. We introduce a perceptually-grounded style transfer training to enforce perceptual consistency. Then, we fine-tune the base model with this newly created dataset. We show that using style-transfer learning significantly improves the SOTA performance on unlabelled data by more than 6% mean average precision (mAP) as well as mean average recall (mAR). (2) To improve the already strong results further, we created a small dataset (ClassArch) consisting of ancient Greek vase paintings from the 6-5th century BCE with person and pose annotations. We show that fine-tuning on this data with a style-transferred model improves the performance further. In a thorough ablation study, we give a targeted analysis of the influence of style intensities, revealing that the model learns generic domain styles. Additionally, we provide a pose-based image retrieval to demonstrate the effectiveness of our method.
On the Usefulness of Self-Attention for Automatic Speech Recognition with Transformers
Nov 08, 2020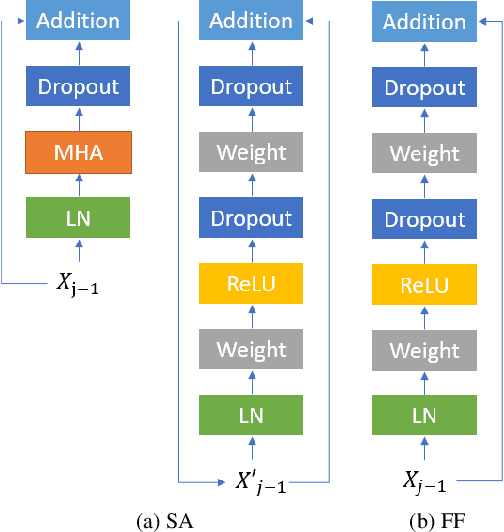
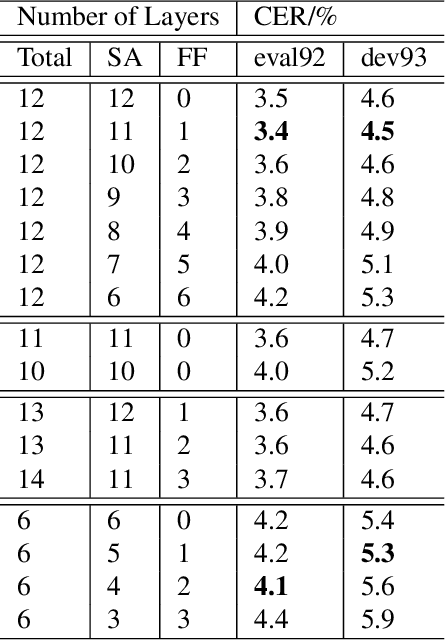
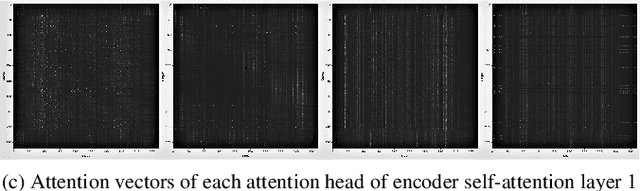
Self-attention models such as Transformers, which can capture temporal relationships without being limited by the distance between events, have given competitive speech recognition results. However, we note the range of the learned context increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence useful for the upper self-attention encoder layers in Transformers? To investigate this, we train models with lower self-attention/upper feed-forward layers encoders on Wall Street Journal and Switchboard. Compared to baseline Transformers, no performance drop but minor gains are observed. We further developed a novel metric of the diagonality of attention matrices and found the learned diagonality indeed increases from the lower to upper encoder self-attention layers. We conclude the global view is unnecessary in training upper encoder layers.
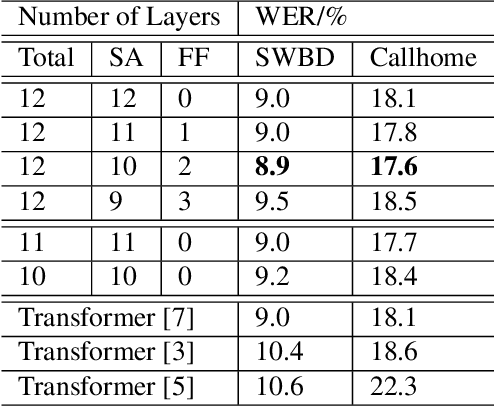
Stochastic Attention Head Removal: A Simple and Effective Method for Improving Automatic Speech Recognition with Transformers
Nov 08, 2020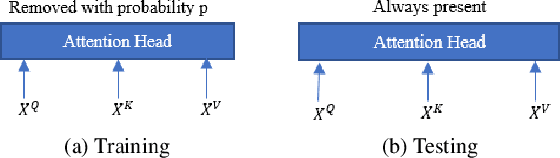
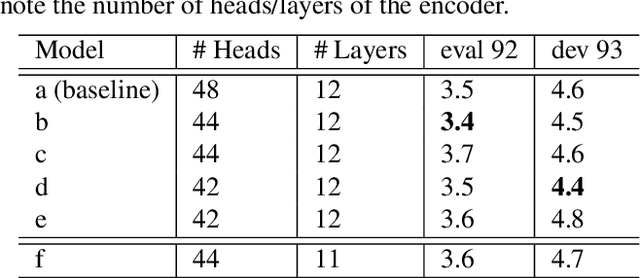
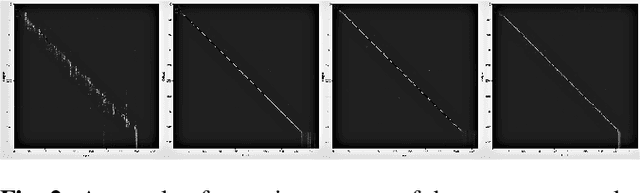
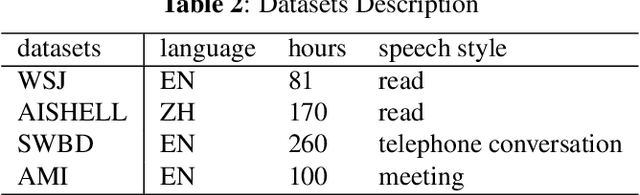
Recently, Transformers have shown competitive automatic speech recognition (ASR) results. One key factor to the success of these models is the multi-head attention mechanism. However, we observed in trained models, the diagonal attention matrices indicating the redundancy of the corresponding attention heads. Furthermore, we found some architectures with reduced numbers of attention heads have better performance. Since the search for the best structure is time prohibitive, we propose to randomly remove attention heads during training and keep all attention heads at test time, thus the final model can be viewed as an average of models with different architectures. This method gives consistent performance gains on the Wall Street Journal, AISHELL, Switchboard and AMI ASR tasks. On the AISHELL dev/test sets, the proposed method achieves state-of-the-art Transformer results with 5.8%/6.3% word error rates.
Leveraging speaker attribute information using multi task learning for speaker verification and diarization
Oct 27, 2020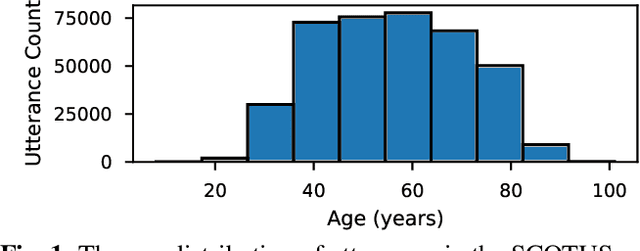
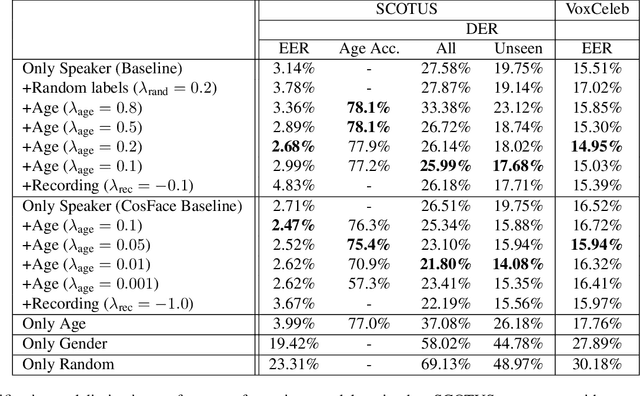
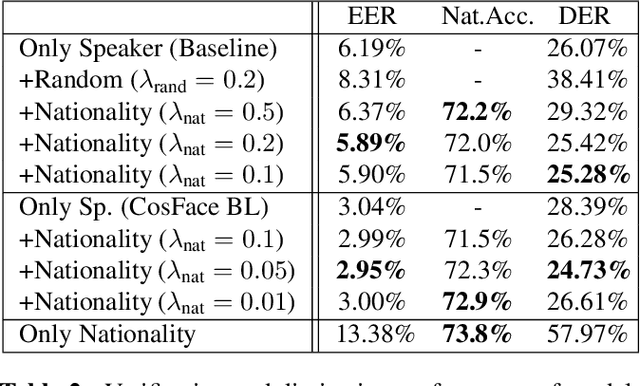
Deep speaker embeddings have become the leading method for encoding speaker identity in speaker recognition tasks. The embedding space should ideally capture the variations between all possible speakers, encoding the multiple aspects that make up speaker identity. In this work, utilizing speaker age as an auxiliary variable in US Supreme Court recordings and speaker nationality with VoxCeleb, we show that by leveraging additional speaker attribute information in a multi task learning setting, deep speaker embedding performance can be increased for verification and diarization tasks, achieving a relative improvement of 17.8% in DER and 8.9% in EER for Supreme Court audio compared to omitting the auxiliary task. Experimental code has been made publicly available.
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020
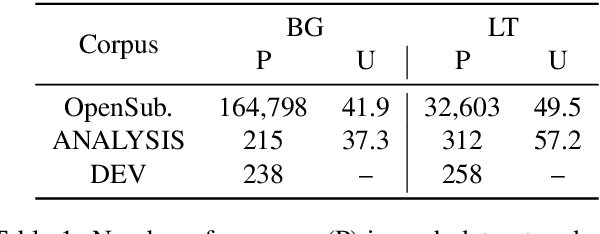
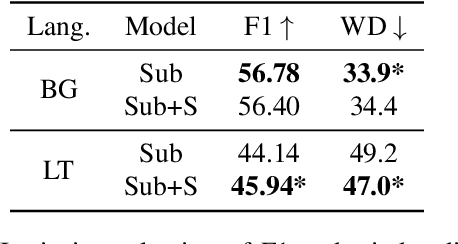

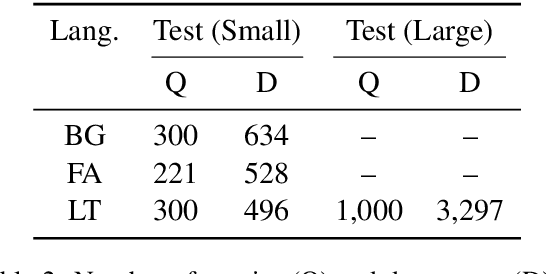
In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Understanding Compositional Structures in Art Historical Images using Pose and Gaze Priors
Sep 08, 2020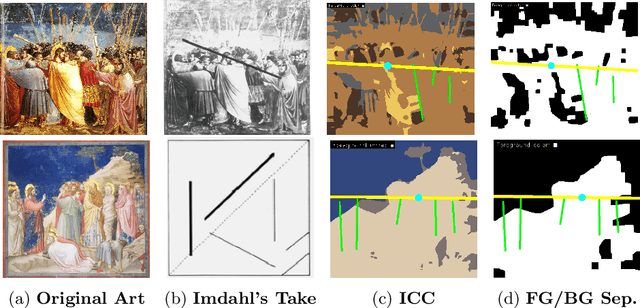
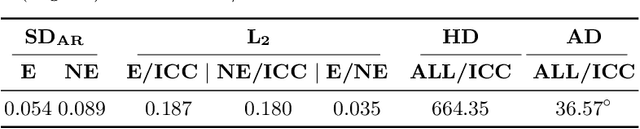
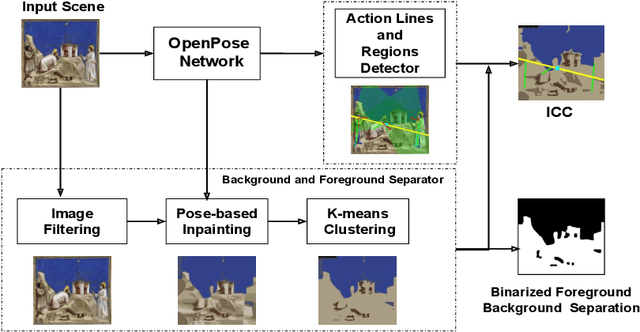

Image compositions as a tool for analysis of artworks is of extreme significance for art historians. These compositions are useful in analyzing the interactions in an image to study artists and their artworks. Max Imdahl in his work called Ikonik, along with other prominent art historians of the 20th century, underlined the aesthetic and semantic importance of the structural composition of an image. Understanding underlying compositional structures within images is challenging and a time consuming task. Generating these structures automatically using computer vision techniques (1) can help art historians towards their sophisticated analysis by saving lot of time; providing an overview and access to huge image repositories and (2) also provide an important step towards an understanding of man made imagery by machines. In this work, we attempt to automate this process using the existing state of the art machine learning techniques, without involving any form of training. Our approach, inspired by Max Imdahl's pioneering work, focuses on two central themes of image composition: (a) detection of action regions and action lines of the artwork; and (b) pose-based segmentation of foreground and background. Currently, our approach works for artworks comprising of protagonists (persons) in an image. In order to validate our approach qualitatively and quantitatively, we conduct a user study involving experts and non-experts. The outcome of the study highly correlates with our approach and also demonstrates its domain-agnostic capability. We have open-sourced the code at https://github.com/image-compostion-canvas-group/image-compostion-canvas.