 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURGE: An Event-Centric Social Media Sentiment Time Series Benchmark with Interaction Structure
May 20, 2026Public events on social media generate large volumes of discussion whose collective dynamics carry direct value for opinion forecasting and crisis response. Capturing how these dynamics evolve across an event's lifecycle requires organizing fragmented posts into event-level time series. Existing datasets cover only a small number of events within a single category, and typically discard the interaction structure between posts when constructing time series, which restricts both transfer across event types and controlled study of how interactions shape the resulting collective dynamics. We present SURGE, a multi-event social media benchmark that pairs event-level time series with aligned text and interaction structure linking posts within an event. SURGE is built through an automated pipeline that produces calendar-aligned time series at three temporal granularities, covering 67 events and more than 800K posts across five event categories. Each time bin is paired with flat and structured textual views derived from the same selected posts, enabling controlled evaluation of whether social interaction structure affects forecasting behavior. On top of SURGE we define benchmark protocols for numerical-only forecasting, text-augmented forecasting, high-interaction evaluation, and leave-one-category-out generalization. Experiments with representative time-series and multimodal forecasting models reveal three properties of the benchmark: a strong local-persistence regime in which naive baselines remain hard to beat under absolute error, limited transfer of existing text-augmented forecasters to event-driven social-media data, and increased difficulty on reply-dense periods that aggregate metrics tend to obscure. We further include a lightweight structure-aware probe as a reference implementation, illustrating how SURGE can support interaction-aware forecasting research.
Large Language Models Enhanced by Plug and Play Syntactic Knowledge for Aspect-based Sentiment Analysis
Jun 15, 2025



Aspect-based sentiment analysis (ABSA) generally requires a deep understanding of the contextual information, including the words associated with the aspect terms and their syntactic dependencies. Most existing studies employ advanced encoders (e.g., pre-trained models) to capture such context, especially large language models (LLMs). However, training these encoders is resource-intensive, and in many cases, the available data is insufficient for necessary fine-tuning. Therefore it is challenging for learning LLMs within such restricted environments and computation efficiency requirement. As a result, it motivates the exploration of plug-and-play methods that adapt LLMs to ABSA with minimal effort. In this paper, we propose an approach that integrates extendable components capable of incorporating various types of syntactic knowledge, such as constituent syntax, word dependencies, and combinatory categorial grammar (CCG). Specifically, we propose a memory module that records syntactic information and is incorporated into LLMs to instruct the prediction of sentiment polarities. Importantly, this encoder acts as a versatile, detachable plugin that is trained independently of the LLM. We conduct experiments on benchmark datasets, which show that our approach outperforms strong baselines and previous approaches, thus demonstrates its effectiveness.
Representation Decomposition for Learning Similarity and Contrastness Across Modalities for Affective Computing
Jun 08, 2025



Multi-modal affective computing aims to automatically recognize and interpret human attitudes from diverse data sources such as images and text, thereby enhancing human-computer interaction and emotion understanding. Existing approaches typically rely on unimodal analysis or straightforward fusion of cross-modal information that fail to capture complex and conflicting evidence presented across different modalities. In this paper, we propose a novel LLM-based approach for affective computing that explicitly deconstructs visual and textual representations into shared (modality-invariant) and modality-specific components. Specifically, our approach firstly encodes and aligns input modalities using pre-trained multi-modal encoders, then employs a representation decomposition framework to separate common emotional content from unique cues, and finally integrates these decomposed signals via an attention mechanism to form a dynamic soft prompt for a multi-modal LLM. Extensive experiments on three representative tasks for affective computing, namely, multi-modal aspect-based sentiment analysis, multi-modal emotion analysis, and hateful meme detection, demonstrate the effectiveness of our approach, which consistently outperforms strong baselines and state-of-the-art models.
CatVRNN: Generating Category Texts via Multi-task Learning
Jul 12, 2021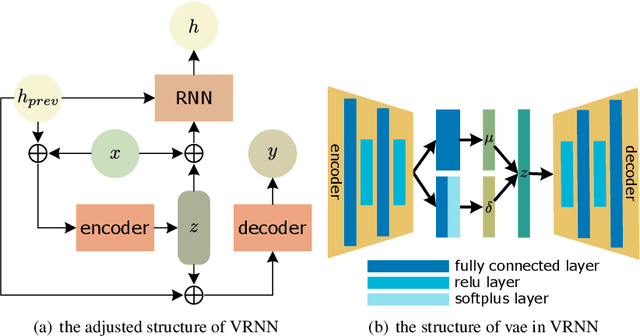
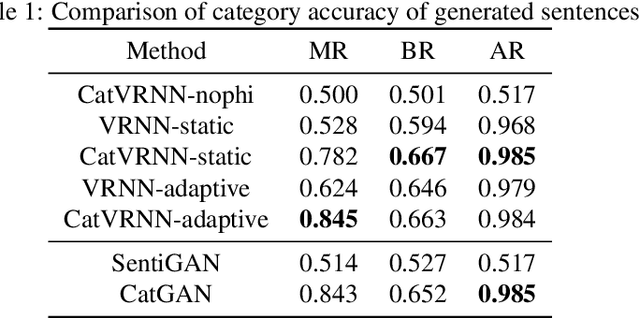

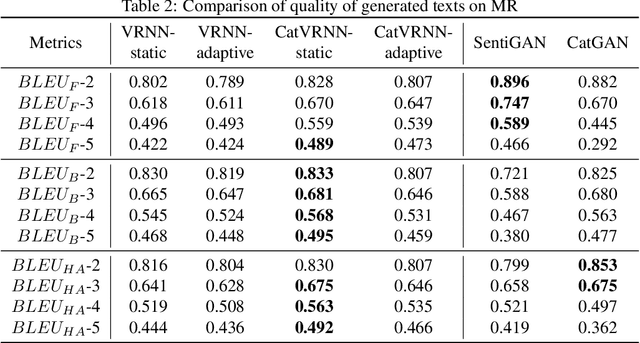
Controlling the model to generate texts of different categories is a challenging task that is getting more and more attention. Recently, generative adversarial net (GAN) has shown promising results in category text generation. However, the texts generated by GANs usually suffer from the problems of mode collapse and training instability. To avoid the above problems, we propose a novel model named category-aware variational recurrent neural network (CatVRNN), which is inspired by multi-task learning. In our model, generation and classification are trained simultaneously, aiming at generating texts of different categories. Moreover, the use of multi-task learning can improve the quality of generated texts, when the classification task is appropriate. And we propose a function to initialize the hidden state of CatVRNN to force model to generate texts of a specific category. Experimental results on three datasets demonstrate that our model can do better than several state-of-the-art text generation methods based GAN in the category accuracy and quality of generated texts.