 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Quantization for Data Agnostic Representation Learning
Dec 19, 2022Self-supervised representation learning follows a paradigm of withholding some part of the data and tasking the network to predict it from the remaining part. Towards this end, masking has emerged as a generic and powerful tool where content is withheld along the sequential dimension, e.g., spatial in images, temporal in audio, and syntactic in language. In this paper, we explore the orthogonal channel dimension for generic data augmentation. The data for each channel is quantized through a non-uniform quantizer, with the quantized value sampled randomly within randomly sampled quantization bins. From another perspective, quantization is analogous to channel-wise masking, as it removes the information within each bin, but preserves the information across bins. We apply the randomized quantization in conjunction with sequential augmentations on self-supervised contrastive models. This generic approach achieves results on par with modality-specific augmentation on vision tasks, and state-of-the-art results on 3D point clouds as well as on audio. We also demonstrate this method to be applicable for augmenting intermediate embeddings in a deep neural network on the comprehensive DABS benchmark which is comprised of various data modalities. Code is availabel at http://www.github.com/microsoft/random_quantize.
SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation
Jun 24, 2022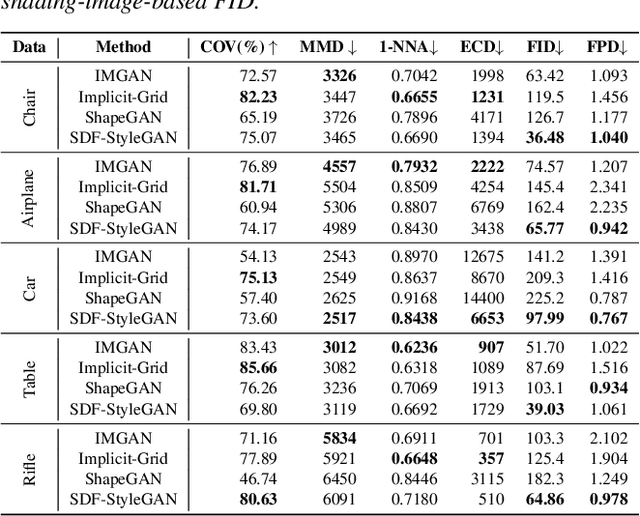

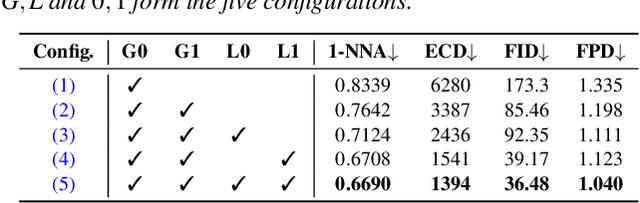
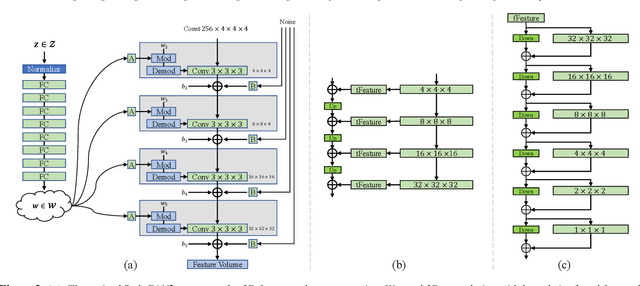
We present a StyleGAN2-based deep learning approach for 3D shape generation, called SDF-StyleGAN, with the aim of reducing visual and geometric dissimilarity between generated shapes and a shape collection. We extend StyleGAN2 to 3D generation and utilize the implicit signed distance function (SDF) as the 3D shape representation, and introduce two novel global and local shape discriminators that distinguish real and fake SDF values and gradients to significantly improve shape geometry and visual quality. We further complement the evaluation metrics of 3D generative models with the shading-image-based Fr\'echet inception distance (FID) scores to better assess visual quality and shape distribution of the generated shapes. Experiments on shape generation demonstrate the superior performance of SDF-StyleGAN over the state-of-the-art. We further demonstrate the efficacy of SDF-StyleGAN in various tasks based on GAN inversion, including shape reconstruction, shape completion from partial point clouds, single-view image-based shape generation, and shape style editing. Extensive ablation studies justify the efficacy of our framework design. Our code and trained models are available at https://github.com/Zhengxinyang/SDF-StyleGAN.
Dual Octree Graph Networks for Learning Adaptive Volumetric Shape Representations
May 06, 2022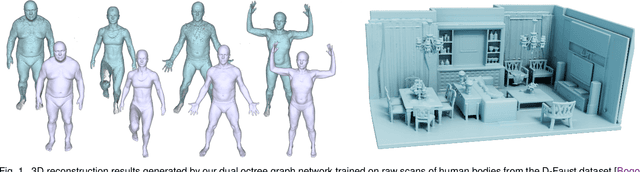

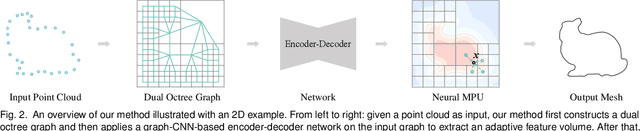
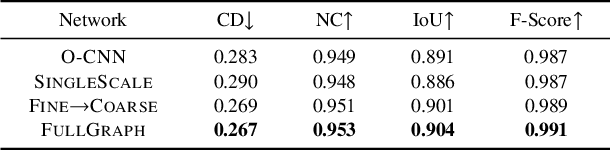
We present an adaptive deep representation of volumetric fields of 3D shapes and an efficient approach to learn this deep representation for high-quality 3D shape reconstruction and auto-encoding. Our method encodes the volumetric field of a 3D shape with an adaptive feature volume organized by an octree and applies a compact multilayer perceptron network for mapping the features to the field value at each 3D position. An encoder-decoder network is designed to learn the adaptive feature volume based on the graph convolutions over the dual graph of octree nodes. The core of our network is a new graph convolution operator defined over a regular grid of features fused from irregular neighboring octree nodes at different levels, which not only reduces the computational and memory cost of the convolutions over irregular neighboring octree nodes, but also improves the performance of feature learning. Our method effectively encodes shape details, enables fast 3D shape reconstruction, and exhibits good generality for modeling 3D shapes out of training categories. We evaluate our method on a set of reconstruction tasks of 3D shapes and scenes and validate its superiority over other existing approaches. Our code, data, and trained models are available at https://wang-ps.github.io/dualocnn.
* Accepted to SIGGRAPH 2022
Semi-supervised 3D shape segmentation with multilevel consistency and part substitution
Apr 20, 2022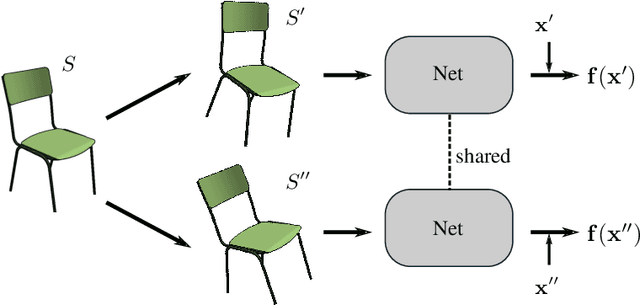
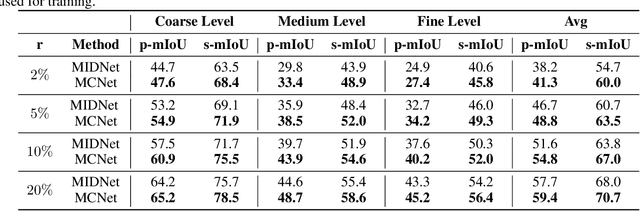
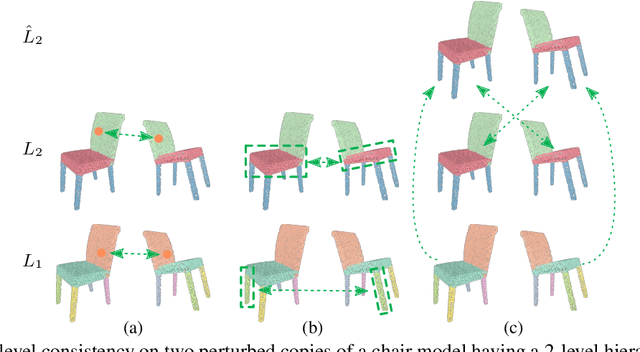
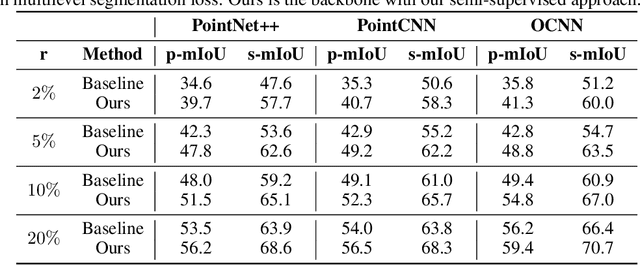
The lack of fine-grained 3D shape segmentation data is the main obstacle to developing learning-based 3D segmentation techniques. We propose an effective semi-supervised method for learning 3D segmentations from a few labeled 3D shapes and a large amount of unlabeled 3D data. For the unlabeled data, we present a novel multilevel consistency loss to enforce consistency of network predictions between perturbed copies of a 3D shape at multiple levels: point-level, part-level, and hierarchical level. For the labeled data, we develop a simple yet effective part substitution scheme to augment the labeled 3D shapes with more structural variations to enhance training. Our method has been extensively validated on the task of 3D object semantic segmentation on PartNet and ShapeNetPart, and indoor scene semantic segmentation on ScanNet. It exhibits superior performance to existing semi-supervised and unsupervised pre-training 3D approaches. Our code and trained models are publicly available at https://github.com/isunchy/semi_supervised_3d_segmentation.
Interpolation-Aware Padding for 3D Sparse Convolutional Neural Networks
Aug 16, 2021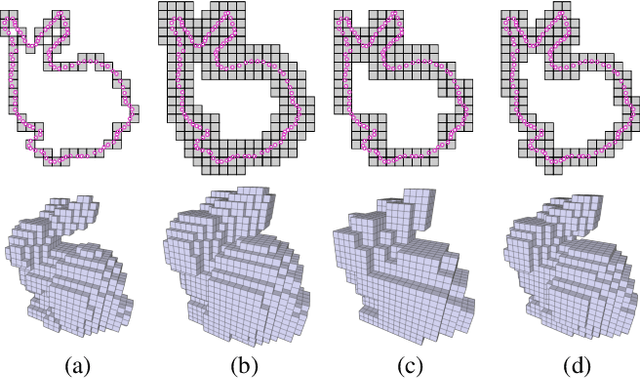
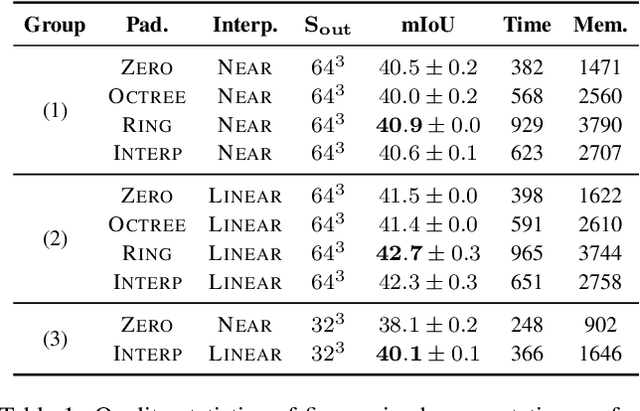
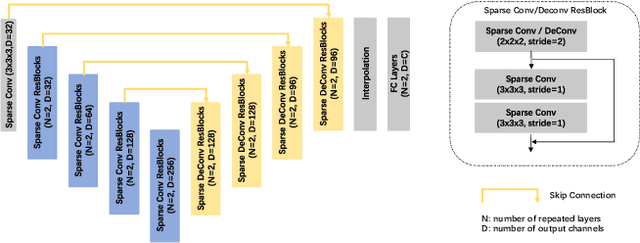
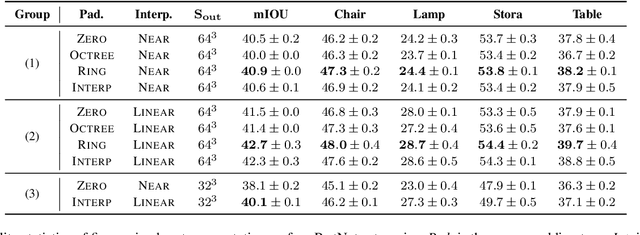
Sparse voxel-based 3D convolutional neural networks (CNNs) are widely used for various 3D vision tasks. Sparse voxel-based 3D CNNs create sparse non-empty voxels from the 3D input and perform 3D convolution operations on them only. We propose a simple yet effective padding scheme --- interpolation-aware padding to pad a few empty voxels adjacent to the non-empty voxels and involve them in the 3D CNN computation so that all neighboring voxels exist when computing point-wise features via the trilinear interpolation. For fine-grained 3D vision tasks where point-wise features are essential, like semantic segmentation and 3D detection, our network achieves higher prediction accuracy than the existing networks using the nearest neighbor interpolation or the normalized trilinear interpolation with the zero-padding or the octree-padding scheme. Through extensive comparisons on various 3D segmentation and detection tasks, we demonstrate the superiority of 3D sparse CNNs with our padding scheme in conjunction with feature interpolation.
Spline Positional Encoding for Learning 3D Implicit Signed Distance Fields
Jun 03, 2021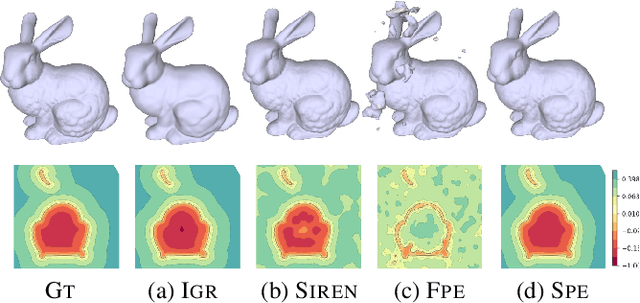

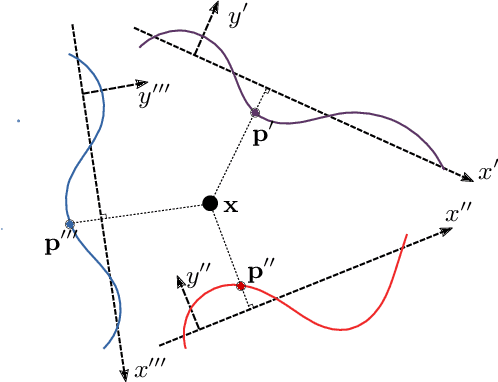
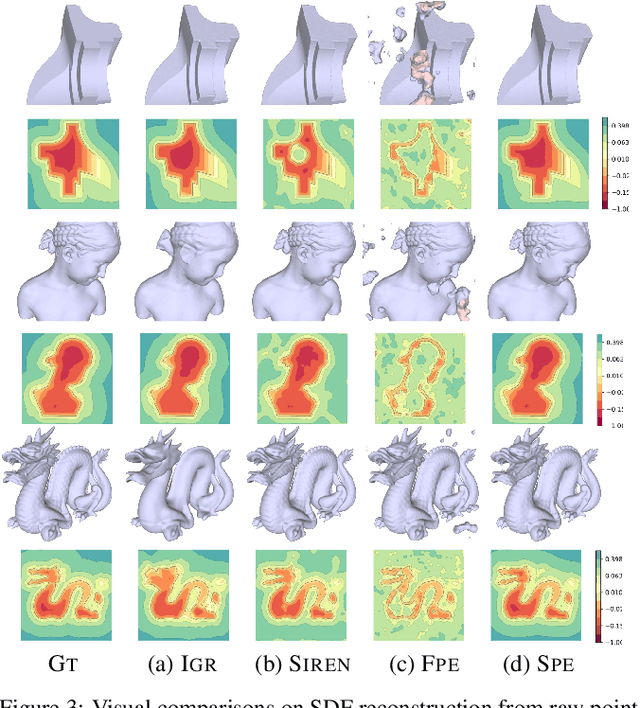
Multilayer perceptrons (MLPs) have been successfully used to represent 3D shapes implicitly and compactly, by mapping 3D coordinates to the corresponding signed distance values or occupancy values. In this paper, we propose a novel positional encoding scheme, called Spline Positional Encoding, to map the input coordinates to a high dimensional space before passing them to MLPs, for helping to recover 3D signed distance fields with fine-scale geometric details from unorganized 3D point clouds. We verified the superiority of our approach over other positional encoding schemes on tasks of 3D shape reconstruction from input point clouds and shape space learning. The efficacy of our approach extended to image reconstruction is also demonstrated and evaluated.
Deep Implicit Moving Least-Squares Functions for 3D Reconstruction
Apr 06, 2021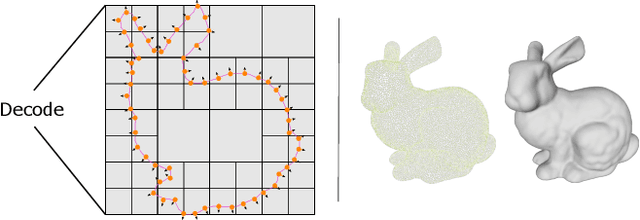
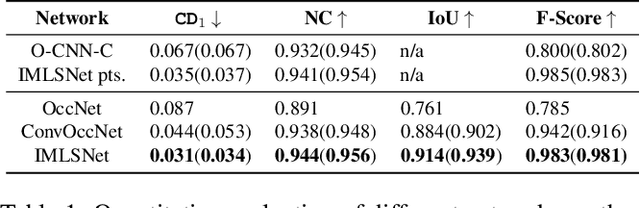
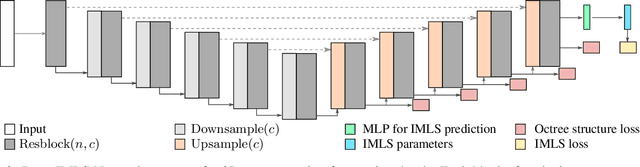
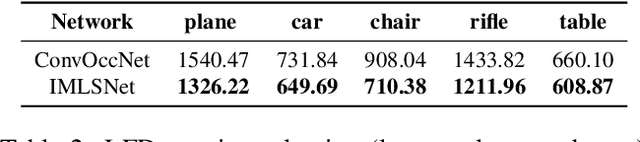
Point set is a flexible and lightweight representation widely used for 3D deep learning. However, their discrete nature prevents them from representing continuous and fine geometry, posing a major issue for learning-based shape generation. In this work, we turn the discrete point sets into smooth surfaces by introducing the well-known implicit moving least-squares (IMLS) surface formulation, which naturally defines locally implicit functions on point sets. We incorporate IMLS surface generation into deep neural networks for inheriting both the flexibility of point sets and the high quality of implicit surfaces. Our IMLSNet predicts an octree structure as a scaffold for generating MLS points where needed and characterizes shape geometry with learned local priors. Furthermore, our implicit function evaluation is independent of the neural network once the MLS points are predicted, thus enabling fast runtime evaluation. Our experiments on 3D object reconstruction demonstrate that IMLSNets outperform state-of-the-art learning-based methods in terms of reconstruction quality and computational efficiency. Extensive ablation tests also validate our network design and loss functions.
Unsupervised 3D Learning for Shape Analysis via Multiresolution Instance Discrimination
Aug 03, 2020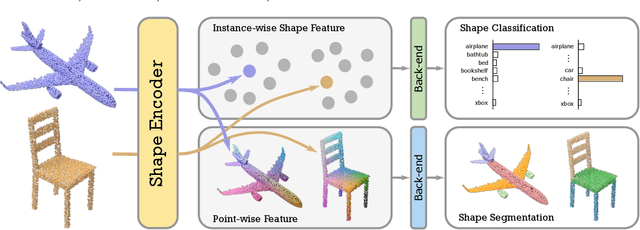
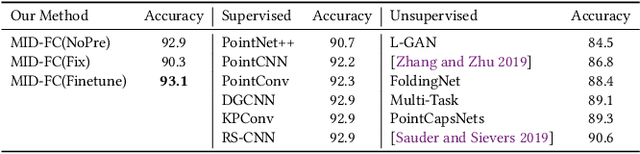
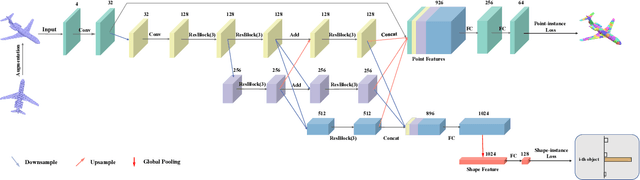
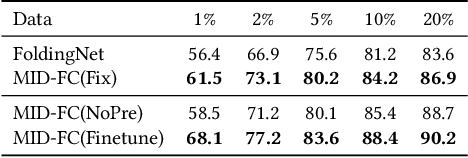
Although unsupervised feature learning has demonstrated its advantages to reducing the workload of data labeling and network design in many fields, existing unsupervised 3D learning methods still cannot offer a generic network for various shape analysis tasks with competitive performance to supervised methods. In this paper, we propose an unsupervised method for learning a generic and efficient shape encoding network for different shape analysis tasks. The key idea of our method is to jointly encode and learn shape and point features from unlabeled 3D point clouds. For this purpose, we adapt HR-Net to octree-based convolutional neural networks for jointly encoding shape and point features with fused multiresolution subnetworks and design a simple-yet-efficient \emph{Multiresolution Instance Discrimination} (MID) loss for jointly learning the shape and point features. Our network takes a 3D point cloud as input and output both shape and point features. After training, the network is concatenated with simple task-specific back-end layers and fine-tuned for different shape analysis tasks. We evaluate the efficacy and generality of our method and validate our network and loss design with a set of shape analysis tasks, including shape classification, semantic shape segmentation, as well as shape registration tasks. With simple back-ends, our network demonstrates the best performance among all unsupervised methods and achieves competitive performance to supervised methods, especially in tasks with a small labeled dataset. For fine-grained shape segmentation, our method even surpasses existing supervised methods by a large margin.
Deep Octree-based CNNs with Output-Guided Skip Connections for 3D Shape and Scene Completion
Jun 06, 2020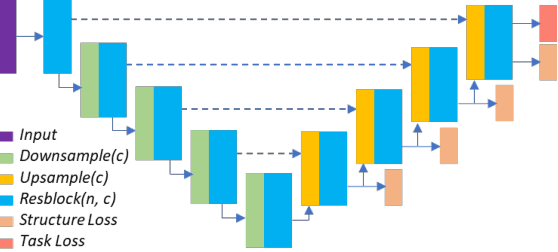

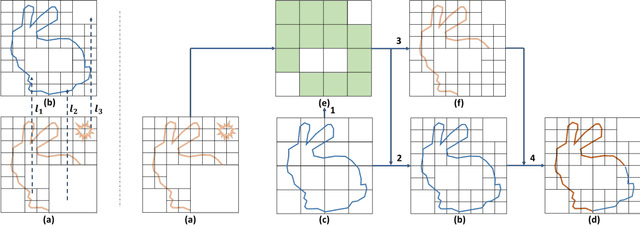
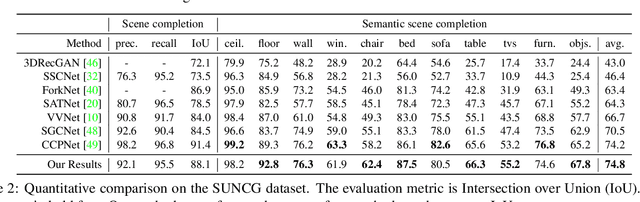
Acquiring complete and clean 3D shape and scene data is challenging due to geometric occlusion and insufficient views during 3D capturing. We present a simple yet effective deep learning approach for completing the input noisy and incomplete shapes or scenes. Our network is built upon the octree-based CNNs (O-CNN) with U-Net like structures, which enjoys high computational and memory efficiency and supports to construct a very deep network structure for 3D CNNs. A novel output-guided skip-connection is introduced to the network structure for better preserving the input geometry and learning geometry prior from data effectively. We show that with these simple adaptions -- output-guided skip-connection and deeper O-CNN (up to 70 layers), our network achieves state-of-the-art results in 3D shape completion and semantic scene computation.
Adaptive O-CNN: A Patch-based Deep Representation of 3D Shapes
Sep 21, 2018
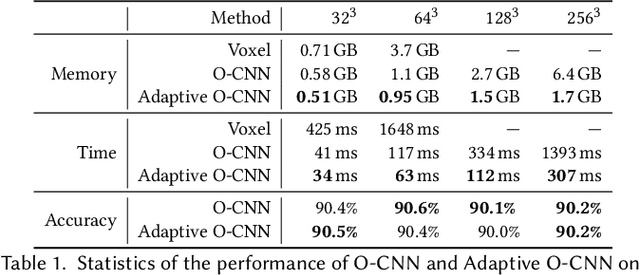

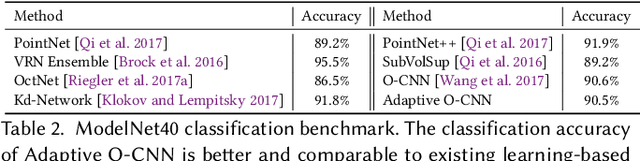
We present an Adaptive Octree-based Convolutional Neural Network (Adaptive O-CNN) for efficient 3D shape encoding and decoding. Different from volumetric-based or octree-based CNN methods that represent a 3D shape with voxels in the same resolution, our method represents a 3D shape adaptively with octants at different levels and models the 3D shape within each octant with a planar patch. Based on this adaptive patch-based representation, we propose an Adaptive O-CNN encoder and decoder for encoding and decoding 3D shapes. The Adaptive O-CNN encoder takes the planar patch normal and displacement as input and performs 3D convolutions only at the octants at each level, while the Adaptive O-CNN decoder infers the shape occupancy and subdivision status of octants at each level and estimates the best plane normal and displacement for each leaf octant. As a general framework for 3D shape analysis and generation, the Adaptive O-CNN not only reduces the memory and computational cost, but also offers better shape generation capability than the existing 3D-CNN approaches. We validate Adaptive O-CNN in terms of efficiency and effectiveness on different shape analysis and generation tasks, including shape classification, 3D autoencoding, shape prediction from a single image, and shape completion for noisy and incomplete point clouds.