 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPM: Mutual Pair Merging for Efficient Vision Transformers
Apr 07, 2026Decreasing sequence length is a common way to accelerate transformers, but prior token reduction work often targets classification and reports proxy metrics rather than end-to-end latency. For semantic segmentation, token reduction is further constrained by the need to reconstruct dense, pixel-aligned features, and on modern accelerators the overhead of computing merge maps can erase expected gains. We propose Mutual Pair Merging (MPM), a training-free token aggregation module that forms mutual nearest-neighbor pairs in cosine space, averages each pair, and records a merge map enabling a gather-based reconstruction before the decoder so that existing segmentation heads can be used unchanged. MPM introduces no learned parameters and no continuous compression knob (no keep-rate or threshold). The speed-accuracy trade-off is set by a discrete insertion schedule. We benchmark end-to-end latency on an NVIDIA H100 GPU (with and without FlashAttention-2) and a Raspberry Pi 5 across standard segmentation datasets. On ADE20K, MPM reduces per-image latency by up to 60% for ViT-Tiny on Raspberry Pi 5, and increases throughput by up to 20% on H100 with FlashAttention-2 while keeping the mIoU drop below 3%. These results suggest that simple, reconstruction-aware, training-free token merging can translate into practical wall-clock gains for segmentation when overhead is explicitly accounted for.
Unlocking Zero-Shot Plant Segmentation with Pl@ntNet Intelligence
Oct 14, 2025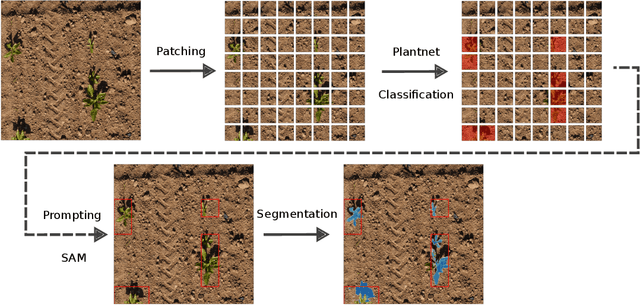


We present a zero-shot segmentation approach for agricultural imagery that leverages Plantnet, a large-scale plant classification model, in conjunction with its DinoV2 backbone and the Segment Anything Model (SAM). Rather than collecting and annotating new datasets, our method exploits Plantnet's specialized plant representations to identify plant regions and produce coarse segmentation masks. These masks are then refined by SAM to yield detailed segmentations. We evaluate on four publicly available datasets of various complexity in terms of contrast including some where the limited size of the training data and complex field conditions often hinder purely supervised methods. Our results show consistent performance gains when using Plantnet-fine-tuned DinoV2 over the base DinoV2 model, as measured by the Jaccard Index (IoU). These findings highlight the potential of combining foundation models with specialized plant-centric models to alleviate the annotation bottleneck and enable effective segmentation in diverse agricultural scenarios.
Toward more frugal models for functional cerebral networks automatic recognition with resting-state fMRI
Jul 04, 2023



We refer to a machine learning situation where models based on classical convolutional neural networks have shown good performance. We are investigating different encoding techniques in the form of supervoxels, then graphs to reduce the complexity of the model while tracking the loss of performance. This approach is illustrated on a recognition task of resting-state functional networks for patients with brain tumors. Graphs encoding supervoxels preserve activation characteristics of functional brain networks from images, optimize model parameters by 26 times while maintaining CNN model performance.
Image Resolution Enhancement by Using Interpolation Followed by Iterative Back Projection
Jan 03, 2016
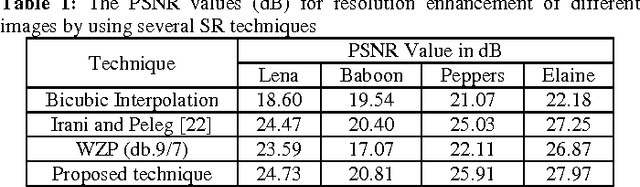

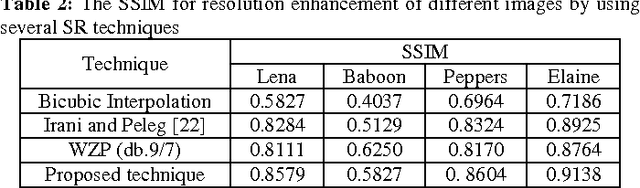
In this paper, we propose a new super resolution technique based on the interpolation followed by registering them using iterative back projection (IBP). Low resolution images are being interpolated and then the interpolated images are being registered in order to generate a sharper high resolution image. The proposed technique has been tested on Lena, Elaine, Pepper, and Baboon. The quantitative peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) results as well as the visual results show the superiority of the proposed technique over the conventional and state-of-art image super resolution techniques. For Lena's image, the PSNR is 6.52 dB higher than the bicubic interpolation.