 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivityForensics: A Comprehensive Benchmark for Localizing Manipulated Activity in Videos
Apr 04, 2026Temporal forgery localization aims to temporally identify manipulated segments in videos. Most existing benchmarks focus on appearance-level forgeries, such as face swapping and object removal. However, recent advances in video generation have driven the emergence of activity-level forgeries that modify human actions to distort event semantics, resulting in highly deceptive forgeries that critically undermine media authenticity and public trust. To overcome this issue, we introduce ActivityForensics, the first large-scale benchmark for localizing manipulated activity in videos. It contains over 6K forged video segments that are seamlessly blended into the video context, rendering high visual consistency that makes them almost indistinguishable from authentic content to the human eye. We further propose Temporal Artifact Diffuser (TADiff), a simple yet effective baseline that exposes artifact cues through a diffusion-based feature regularizer. Based on ActivityForensics, we introduce comprehensive evaluation protocols covering intra-domain, cross-domain, and open-world settings, and benchmark a wide range of state-of-the-art forgery localizers to facilitate future research. The dataset and code are available at https://activityforensics.github.io.
SAKED: Mitigating Hallucination in Large Vision-Language Models via Stability-Aware Knowledge Enhanced Decoding
Feb 10, 2026Hallucinations in Large Vision-Language Models (LVLMs) pose significant security and reliability risks in real-world applications. Inspired by the observation that humans are more error-prone when uncertain or hesitant, we investigate how instability in a model 's internal knowledge contributes to LVLM hallucinations. We conduct extensive empirical analyses from three perspectives, namely attention heads, model layers, and decoding tokens, and identify three key hallucination patterns: (i) visual activation drift across attention heads, (ii) pronounced knowledge fluctuations across layers, and (iii) visual focus distraction between neighboring output tokens. Building on these findings, we propose Stability-Aware Knowledge-Enhanced Decoding (SAKED), which introduces a layer-wise Knowledge Stability Score (KSS) to quantify knowledge stability throughout the model. By contrasting the most stability-aware and stability-agnostic layers, SAKED suppresses decoding noise and dynamically leverages the most reliable internal knowledge for faithful token generation. Moreover, SAKED is training-free and can be seamlessly integrated into different architectures. Extensive experiments demonstrate that SAKED achieves state-of-the-art performance for hallucination mitigation on various models, tasks, and benchmarks.
Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild
Dec 01, 2024



Given a natural language query, video moment retrieval aims to localize the described temporal moment in an untrimmed video. A major challenge of this task is its heavy dependence on labor-intensive annotations for training. Unlike existing works that directly train models on manually curated data, we propose a novel paradigm to reduce annotation costs: pretraining the model on unlabeled, real-world videos. To support this, we introduce Video Moment Retrieval Pretraining (Vid-Morp), a large-scale dataset collected with minimal human intervention, consisting of over 50K videos captured in the wild and 200K pseudo annotations. Direct pretraining on these imperfect pseudo annotations, however, presents significant challenges, including mismatched sentence-video pairs and imprecise temporal boundaries. To address these issues, we propose the ReCorrect algorithm, which comprises two main phases: semantics-guided refinement and memory-consensus correction. The semantics-guided refinement enhances the pseudo labels by leveraging semantic similarity with video frames to clean out unpaired data and make initial adjustments to temporal boundaries. In the following memory-consensus correction phase, a memory bank tracks the model predictions, progressively correcting the temporal boundaries based on consensus within the memory. Comprehensive experiments demonstrate ReCorrect's strong generalization abilities across multiple downstream settings. Zero-shot ReCorrect achieves over 75% and 80% of the best fully-supervised performance on two benchmarks, while unsupervised ReCorrect reaches about 85% on both. The code, dataset, and pretrained models are available at https://github.com/baopj/Vid-Morp.
SimBase: A Simple Baseline for Temporal Video Grounding
Nov 12, 2024


This paper presents SimBase, a simple yet effective baseline for temporal video grounding. While recent advances in temporal grounding have led to impressive performance, they have also driven network architectures toward greater complexity, with a range of methods to (1) capture temporal relationships and (2) achieve effective multimodal fusion. In contrast, this paper explores the question: How effective can a simplified approach be? To investigate, we design SimBase, a network that leverages lightweight, one-dimensional temporal convolutional layers instead of complex temporal structures. For cross-modal interaction, SimBase only employs an element-wise product instead of intricate multimodal fusion. Remarkably, SimBase achieves state-of-the-art results on two large-scale datasets. As a simple yet powerful baseline, we hope SimBase will spark new ideas and streamline future evaluations in temporal video grounding.
Open-Set Deepfake Detection: A Parameter-Efficient Adaptation Method with Forgery Style Mixture
Aug 23, 2024



Open-set face forgery detection poses significant security threats and presents substantial challenges for existing detection models. These detectors primarily have two limitations: they cannot generalize across unknown forgery domains and inefficiently adapt to new data. To address these issues, we introduce an approach that is both general and parameter-efficient for face forgery detection. It builds on the assumption that different forgery source domains exhibit distinct style statistics. Previous methods typically require fully fine-tuning pre-trained networks, consuming substantial time and computational resources. In turn, we design a forgery-style mixture formulation that augments the diversity of forgery source domains, enhancing the model's generalizability across unseen domains. Drawing on recent advancements in vision transformers (ViT) for face forgery detection, we develop a parameter-efficient ViT-based detection model that includes lightweight forgery feature extraction modules and enables the model to extract global and local forgery clues simultaneously. We only optimize the inserted lightweight modules during training, maintaining the original ViT structure with its pre-trained ImageNet weights. This training strategy effectively preserves the informative pre-trained knowledge while flexibly adapting the model to the task of Deepfake detection. Extensive experimental results demonstrate that the designed model achieves state-of-the-art generalizability with significantly reduced trainable parameters, representing an important step toward open-set Deepfake detection in the wild.
Learning Sample Importance for Cross-Scenario Video Temporal Grounding
Jan 08, 2022
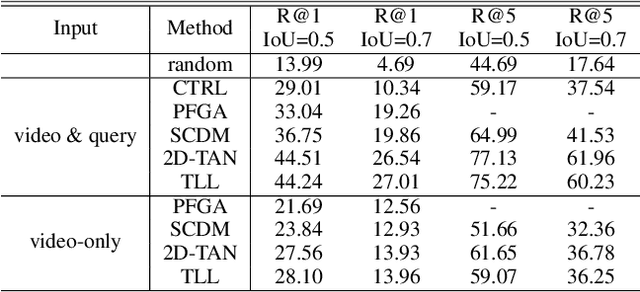
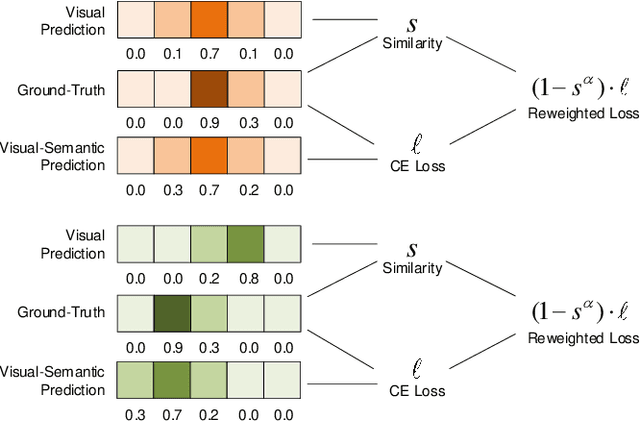
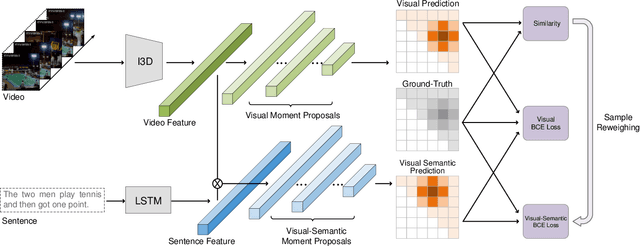
The task of temporal grounding aims to locate video moment in an untrimmed video, with a given sentence query. This paper for the first time investigates some superficial biases that are specific to the temporal grounding task, and proposes a novel targeted solution. Most alarmingly, we observe that existing temporal ground models heavily rely on some biases (e.g., high preference on frequent concepts or certain temporal intervals) in the visual modal. This leads to inferior performance when generalizing the model in cross-scenario test setting. To this end, we propose a novel method called Debiased Temporal Language Localizer (DebiasTLL) to prevent the model from naively memorizing the biases and enforce it to ground the query sentence based on true inter-modal relationship. Debias-TLL simultaneously trains two models. By our design, a large discrepancy of these two models' predictions when judging a sample reveals higher probability of being a biased sample. Harnessing the informative discrepancy, we devise a data re-weighing scheme for mitigating the data biases. We evaluate the proposed model in cross-scenario temporal grounding, where the train / test data are heterogeneously sourced. Experiments show large-margin superiority of the proposed method in comparison with state-of-the-art competitors.