 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction Preserving Projection for Scalable Exploration of High-Dimensional Data
Sep 25, 2019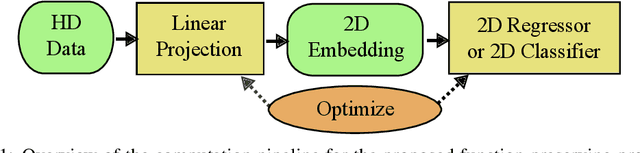
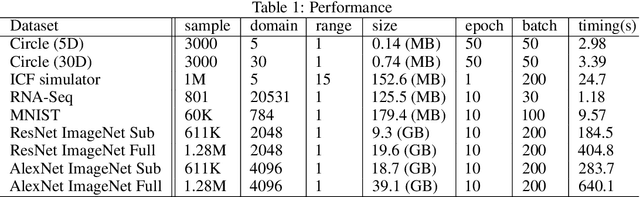
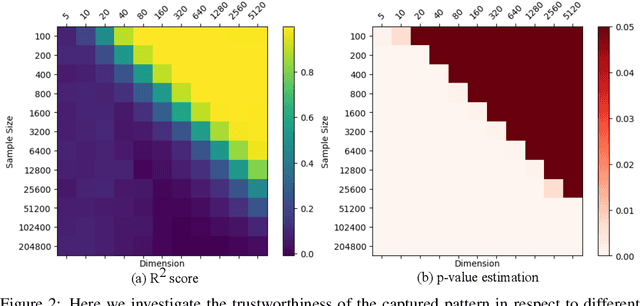
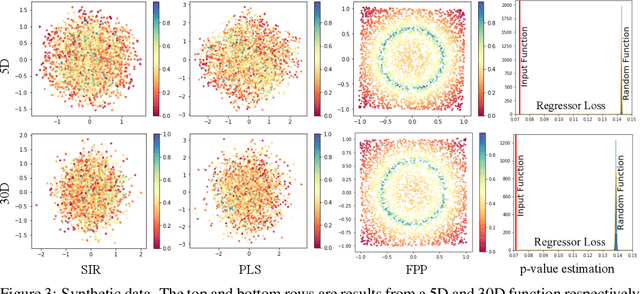
We present function preserving projections (FPP), a scalable linear projection technique for discovering interpretable relationships in high-dimensional data. Conventional dimension reduction methods aim to maximally preserve the global and/or local geometric structure of a dataset. However, in practice one is often more interested in determining how one or multiple user-selected response function(s) can be explained by the data. To intuitively connect the responses to the data, FPP constructs 2D linear embeddings optimized to reveal interpretable yet potentially non-linear patterns of the response functions. More specifically, FPP is designed to (i) produce human-interpretable embeddings; (ii) capture non-linear relationships; (iii) allow the simultaneous use of multiple response functions; and (iv) scale to millions of samples. Using FPP on real-world datasets, one can obtain fundamentally new insights about high-dimensional relationships in large-scale data that could not be achieved using existing dimension reduction methods.
Building Calibrated Deep Models via Uncertainty Matching with Auxiliary Interval Predictors
Sep 09, 2019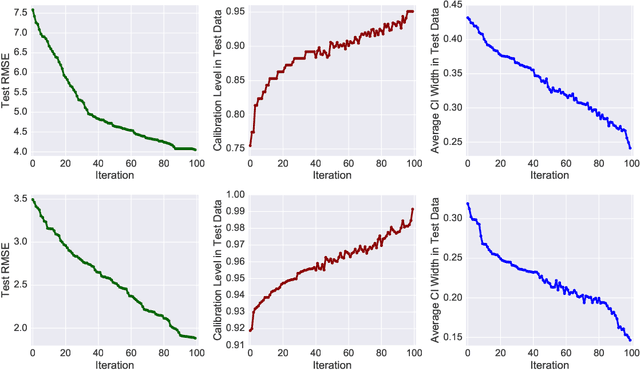
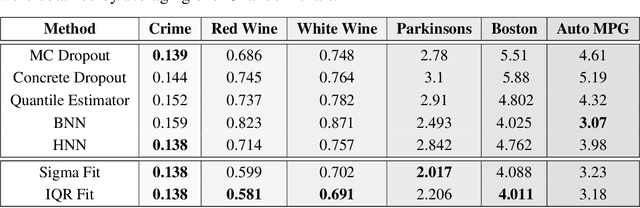
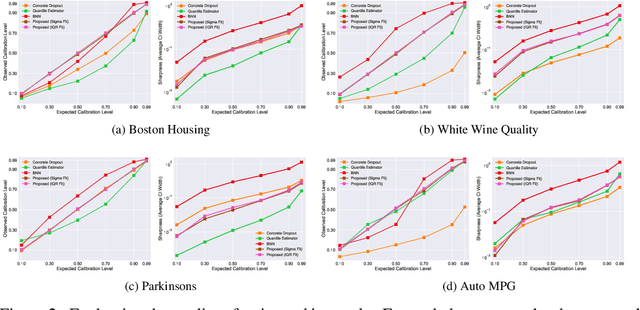
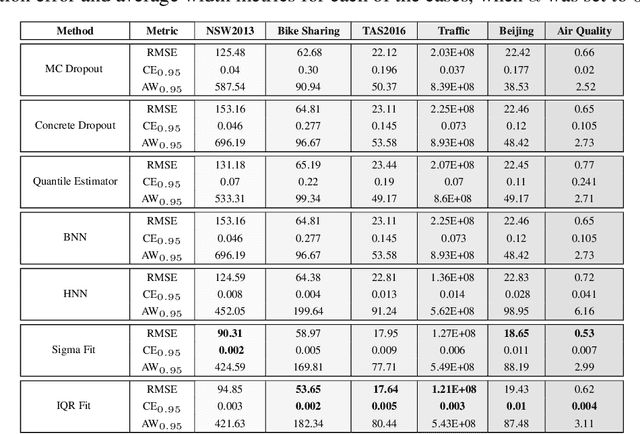
With rapid adoption of deep learning in high-regret applications, the question of when and how much to trust these models often arises, which drives the need to quantify the inherent uncertainties. While identifying all sources that account for the stochasticity of learned models is challenging, it is common to augment predictions with confidence intervals to convey the expected variations in a model's behavior. In general, we require confidence intervals to be well-calibrated, reflect the true uncertainties, and to be sharp. However, most existing techniques for obtaining confidence intervals are known to produce unsatisfactory results in terms of at least one of those criteria. To address this challenge, we develop a novel approach for building calibrated estimators. More specifically, we construct separate models for predicting the target variable, and for estimating the confidence intervals, and pose a bi-level optimization problem that allows the predictive model to leverage estimates from the interval estimator through an \textit{uncertainty matching} strategy. Using experiments in regression, time-series forecasting, and object localization, we show that our approach achieves significant improvements over existing uncertainty quantification methods, both in terms of model fidelity and calibration error.
Scalable Topological Data Analysis and Visualization for Evaluating Data-Driven Models in Scientific Applications
Jul 19, 2019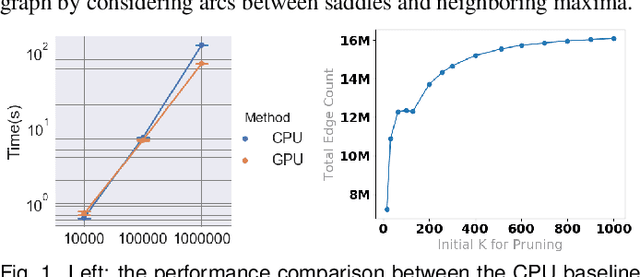
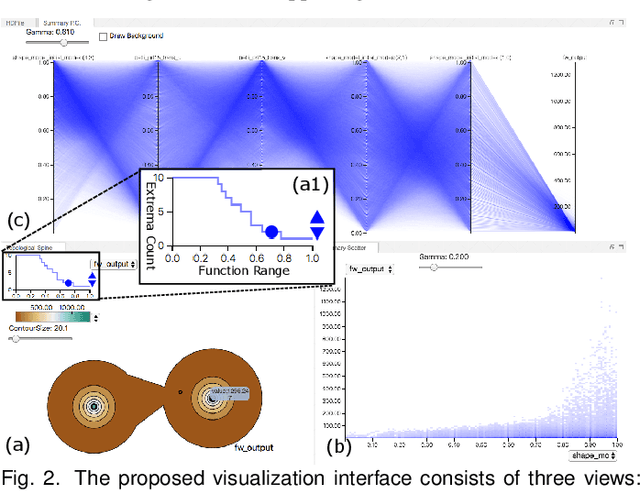
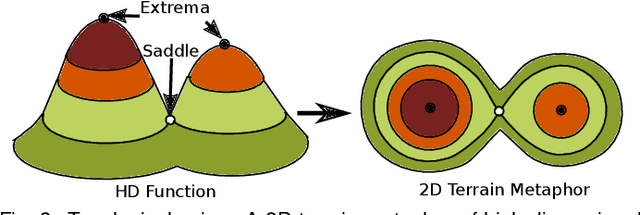
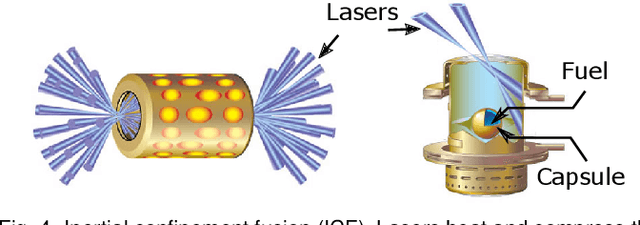
With the rapid adoption of machine learning techniques for large-scale applications in science and engineering comes the convergence of two grand challenges in visualization. First, the utilization of black box models (e.g., deep neural networks) calls for advanced techniques in exploring and interpreting model behaviors. Second, the rapid growth in computing has produced enormous datasets that require techniques that can handle millions or more samples. Although some solutions to these interpretability challenges have been proposed, they typically do not scale beyond thousands of samples, nor do they provide the high-level intuition scientists are looking for. Here, we present the first scalable solution to explore and analyze high-dimensional functions often encountered in the scientific data analysis pipeline. By combining a new streaming neighborhood graph construction, the corresponding topology computation, and a novel data aggregation scheme, namely topology aware datacubes, we enable interactive exploration of both the topological and the geometric aspect of high-dimensional data. Following two use cases from high-energy-density (HED) physics and computational biology, we demonstrate how these capabilities have led to crucial new insights in both applications.
A Look at the Effect of Sample Design on Generalization through the Lens of Spectral Analysis
Jun 08, 2019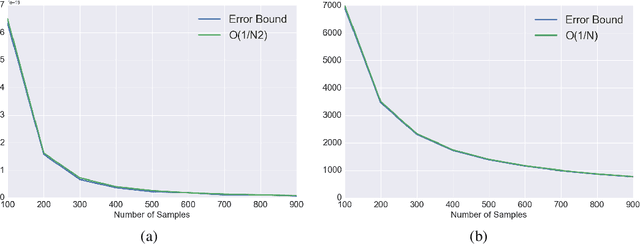
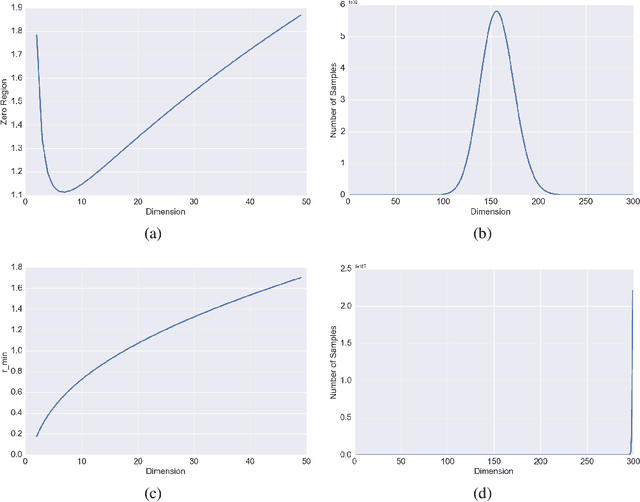
This paper provides a general framework to study the effect of sampling properties of training data on the generalization error of the learned machine learning (ML) models. Specifically, we propose a new spectral analysis of the generalization error, expressed in terms of the power spectra of the sampling pattern and the function involved. The framework is build in the Euclidean space using Fourier analysis and establishes a connection between some high dimensional geometric objects and optimal spectral form of different state-of-the-art sampling patterns. Subsequently, we estimate the expected error bounds and convergence rate of different state-of-the-art sampling patterns, as the number of samples and dimensions increase. We make several observations about generalization error which are valid irrespective of the approximation scheme (or learning architecture) and training (or optimization) algorithms. Our result also sheds light on ways to formulate design principles for constructing optimal sampling methods for particular problems.
Understanding Deep Neural Networks through Input Uncertainties
Nov 01, 2018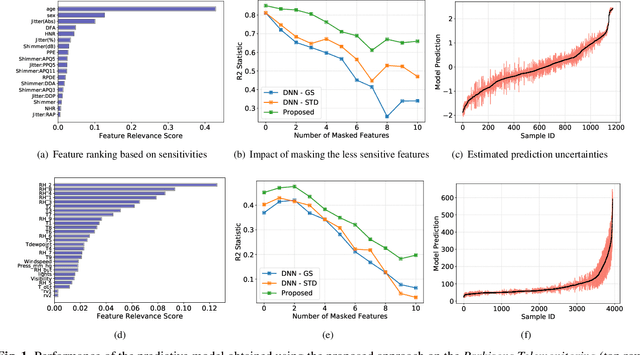
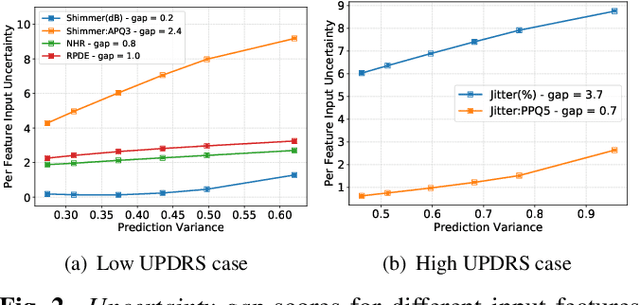
Techniques for understanding the functioning of complex machine learning models are becoming increasingly popular, not only to improve the validation process, but also to extract new insights about the data via exploratory analysis. Though a large class of such tools currently exists, most assume that predictions are point estimates and use a sensitivity analysis of these estimates to interpret the model. Using lightweight probabilistic networks we show how including prediction uncertainties in the sensitivity analysis leads to: (i) more robust and generalizable models; and (ii) a new approach for model interpretation through uncertainty decomposition. In particular, we introduce a new regularization that takes both the mean and variance of a prediction into account and demonstrate that the resulting networks provide improved generalization to unseen data. Furthermore, we propose a new technique to explain prediction uncertainties through uncertainties in the input domain, thus providing new ways to validate and interpret deep learning models.
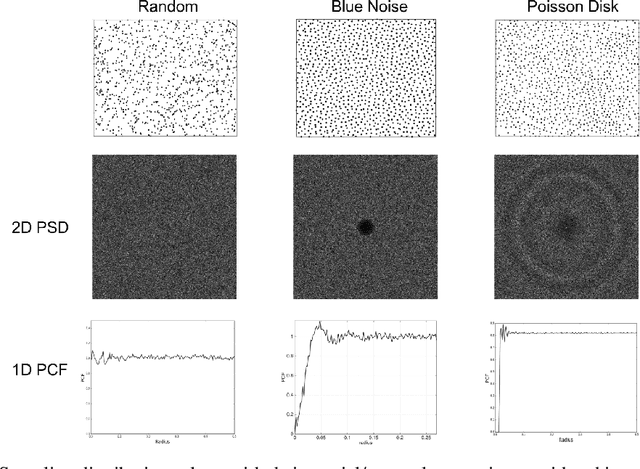
Unsupervised Dimension Selection using a Blue Noise Spectrum
Oct 31, 2018
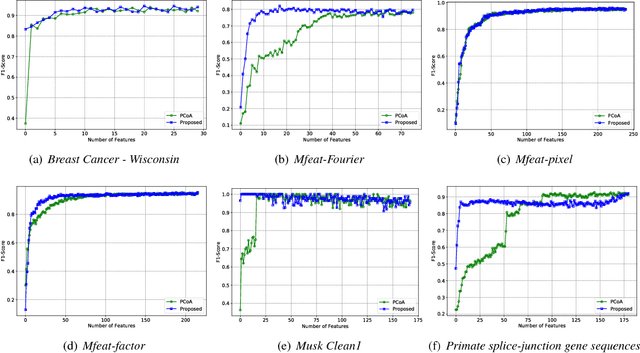
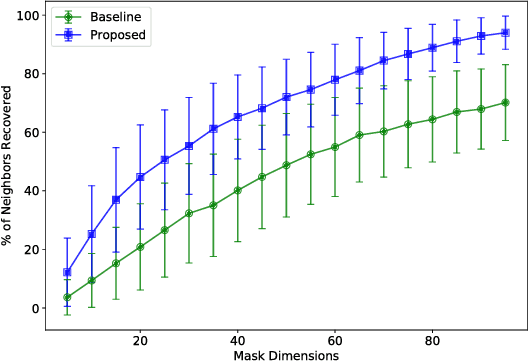
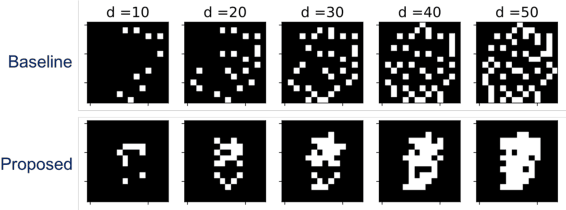
Unsupervised dimension selection is an important problem that seeks to reduce dimensionality of data, while preserving the most useful characteristics. While dimensionality reduction is commonly utilized to construct low-dimensional embeddings, they produce feature spaces that are hard to interpret. Further, in applications such as sensor design, one needs to perform reduction directly in the input domain, instead of constructing transformed spaces. Consequently, dimension selection (DS) aims to solve the combinatorial problem of identifying the top-$k$ dimensions, which is required for effective experiment design, reducing data while keeping it interpretable, and designing better sensing mechanisms. In this paper, we develop a novel approach for DS based on graph signal analysis to measure feature influence. By analyzing synthetic graph signals with a blue noise spectrum, we show that we can measure the importance of each dimension. Using experiments in supervised learning and image masking, we demonstrate the superiority of the proposed approach over existing techniques in capturing crucial characteristics of high dimensional spaces, using only a small subset of the original features.
Controlled Random Search Improves Sample Mining and Hyper-Parameter Optimization
Sep 05, 2018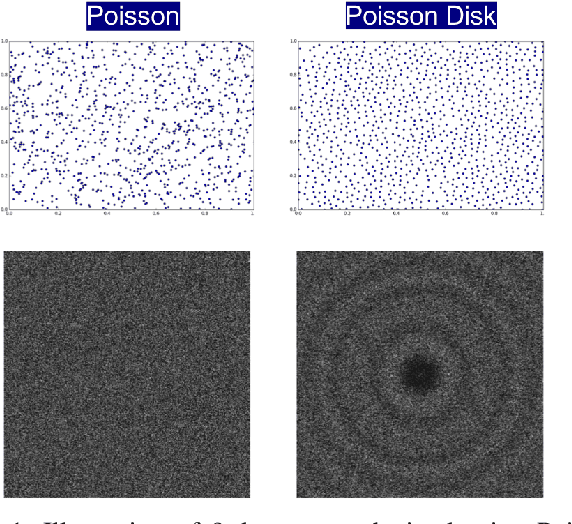
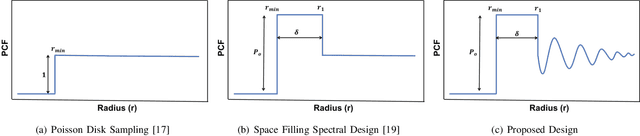
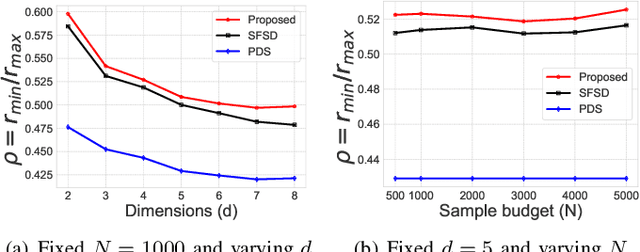
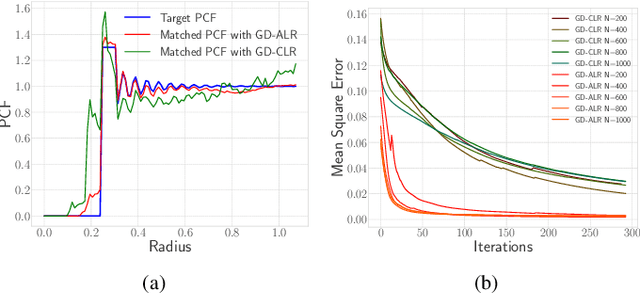
A common challenge in machine learning and related fields is the need to efficiently explore high dimensional parameter spaces using small numbers of samples. Typical examples are hyper-parameter optimization in deep learning and sample mining in predictive modeling tasks. All such problems trade-off exploration, which samples the space without knowledge of the target function, and exploitation where information from previous evaluations is used in an adaptive feedback loop. Much of the recent focus has been on the exploitation while exploration is done with simple designs such as Latin hypercube or even uniform random sampling. In this paper, we introduce optimal space-filling sample designs for effective exploration of high dimensional spaces. Specifically, we propose a new parameterized family of sample designs called space-filling spectral designs, and introduce a framework to choose optimal designs for a given sample size and dimension. Furthermore, we present an efficient algorithm to synthesize a given spectral design. Finally, we evaluate the performance of spectral designs in both data space and model space applications. The data space exploration is targeted at recovering complex regression functions in high dimensional spaces. The model space exploration focuses on selecting hyper-parameters for a given neural network architecture. Our empirical studies demonstrate that the proposed approach consistently outperforms state-of-the-art techniques, particularly with smaller design sizes.
Exploring High-Dimensional Structure via Axis-Aligned Decomposition of Linear Projections
Dec 20, 2017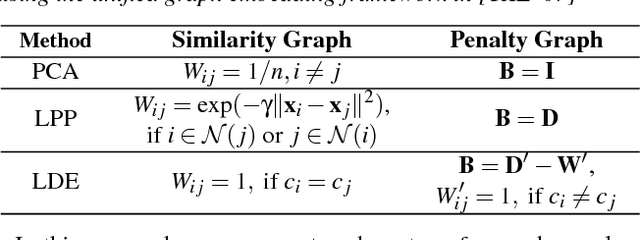
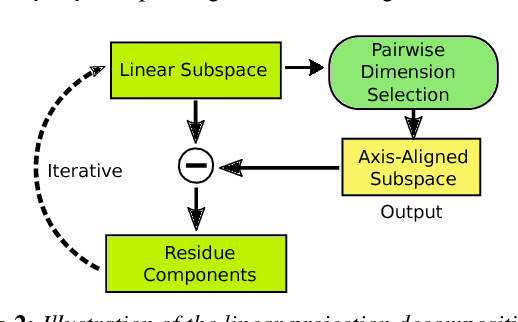
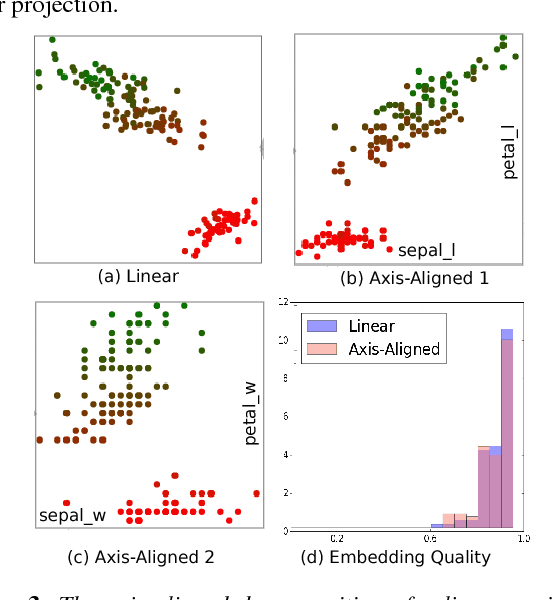
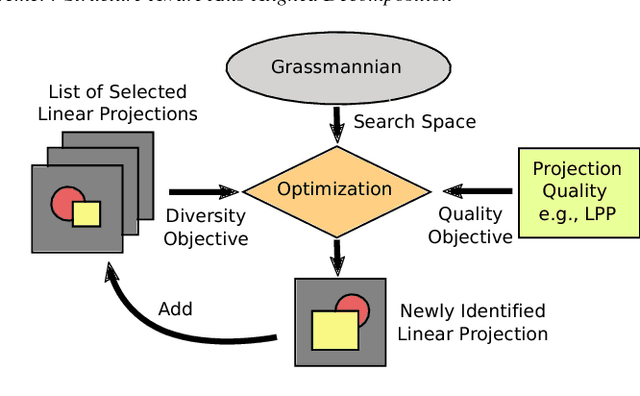
Two-dimensional embeddings remain the dominant approach to visualize high dimensional data. The choice of embeddings ranges from highly non-linear ones, which can capture complex relationships but are difficult to interpret quantitatively, to axis-aligned projections, which are easy to interpret but are limited to bivariate relationships. Linear project can be considered as a compromise between complexity and interpretability, as they allow explicit axes labels, yet provide significantly more degrees of freedom compared to axis-aligned projections. Nevertheless, interpreting the axes directions, which are linear combinations often with many non-trivial components, remains difficult. To address this problem we introduce a structure aware decomposition of (multiple) linear projections into sparse sets of axis aligned projections, which jointly capture all information of the original linear ones. In particular, we use tools from Dempster-Shafer theory to formally define how relevant a given axis aligned project is to explain the neighborhood relations displayed in some linear projection. Furthermore, we introduce a new approach to discover a diverse set of high quality linear projections and show that in practice the information of $k$ linear projections is often jointly encoded in $\sim k$ axis aligned plots. We have integrated these ideas into an interactive visualization system that allows users to jointly browse both linear projections and their axis aligned representatives. Using a number of case studies we show how the resulting plots lead to more intuitive visualizations and new insight.
A Spectral Approach for the Design of Experiments: Design, Analysis and Algorithms
Dec 16, 2017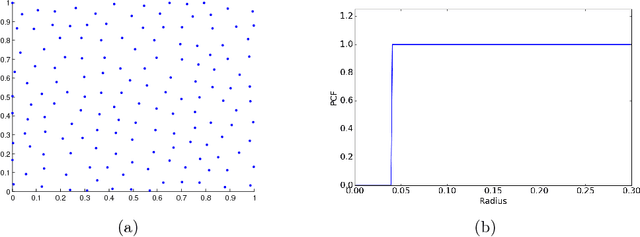

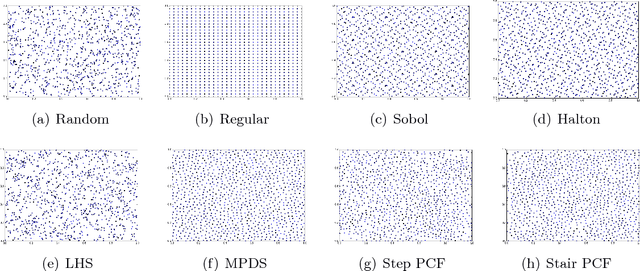
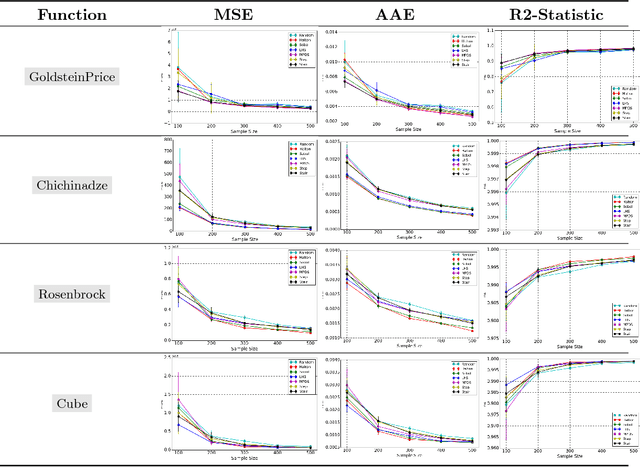
This paper proposes a new approach to construct high quality space-filling sample designs. First, we propose a novel technique to quantify the space-filling property and optimally trade-off uniformity and randomness in sample designs in arbitrary dimensions. Second, we connect the proposed metric (defined in the spatial domain) to the objective measure of the design performance (defined in the spectral domain). This connection serves as an analytic framework for evaluating the qualitative properties of space-filling designs in general. Using the theoretical insights provided by this spatial-spectral analysis, we derive the notion of optimal space-filling designs, which we refer to as space-filling spectral designs. Third, we propose an efficient estimator to evaluate the space-filling properties of sample designs in arbitrary dimensions and use it to develop an optimization framework to generate high quality space-filling designs. Finally, we carry out a detailed performance comparison on two different applications in 2 to 6 dimensions: a) image reconstruction and b) surrogate modeling on several benchmark optimization functions and an inertial confinement fusion (ICF) simulation code. We demonstrate that the propose spectral designs significantly outperform existing approaches especially in high dimensions.