 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Images of the M87* Black Hole Using GANs
Dec 02, 2023



In this paper, we introduce a novel data augmentation methodology based on Conditional Progressive Generative Adversarial Networks (CPGAN) to generate diverse black hole (BH) images, accounting for variations in spin and electron temperature prescriptions. These generated images are valuable resources for training deep learning algorithms to accurately estimate black hole parameters from observational data. Our model can generate BH images for any spin value within the range of [-1, 1], given an electron temperature distribution. To validate the effectiveness of our approach, we employ a convolutional neural network to predict the BH spin using both the GRMHD images and the images generated by our proposed model. Our results demonstrate a significant performance improvement when training is conducted with the augmented dataset while testing is performed using GRMHD simulated data, as indicated by the high R2 score. Consequently, we propose that GANs can be employed as cost effective models for black hole image generation and reliably augment training datasets for other parameterization algorithms.
One-Shot Transfer Learning for Nonlinear ODEs
Nov 25, 2023We introduce a generalizable approach that combines perturbation method and one-shot transfer learning to solve nonlinear ODEs with a single polynomial term, using Physics-Informed Neural Networks (PINNs). Our method transforms non-linear ODEs into linear ODE systems, trains a PINN across varied conditions, and offers a closed-form solution for new instances within the same non-linear ODE class. We demonstrate the effectiveness of this approach on the Duffing equation and suggest its applicability to similarly structured PDEs and ODE systems.
Error-Aware B-PINNs: Improving Uncertainty Quantification in Bayesian Physics-Informed Neural Networks
Dec 14, 2022



Physics-Informed Neural Networks (PINNs) are gaining popularity as a method for solving differential equations. While being more feasible in some contexts than the classical numerical techniques, PINNs still lack credibility. A remedy for that can be found in Uncertainty Quantification (UQ) which is just beginning to emerge in the context of PINNs. Assessing how well the trained PINN complies with imposed differential equation is the key to tackling uncertainty, yet there is lack of comprehensive methodology for this task. We propose a framework for UQ in Bayesian PINNs (B-PINNs) that incorporates the discrepancy between the B-PINN solution and the unknown true solution. We exploit recent results on error bounds for PINNs on linear dynamical systems and demonstrate the predictive uncertainty on a class of linear ODEs.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022

The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.
Transfer Learning with Physics-Informed Neural Networks for Efficient Simulation of Branched Flows
Nov 01, 2022



Physics-Informed Neural Networks (PINNs) offer a promising approach to solving differential equations and, more generally, to applying deep learning to problems in the physical sciences. We adopt a recently developed transfer learning approach for PINNs and introduce a multi-head model to efficiently obtain accurate solutions to nonlinear systems of ordinary differential equations with random potentials. In particular, we apply the method to simulate stochastic branched flows, a universal phenomenon in random wave dynamics. Finally, we compare the results achieved by feed forward and GAN-based PINNs on two physically relevant transfer learning tasks and show that our methods provide significant computational speedups in comparison to standard PINNs trained from scratch.
DEQGAN: Learning the Loss Function for PINNs with Generative Adversarial Networks
Sep 15, 2022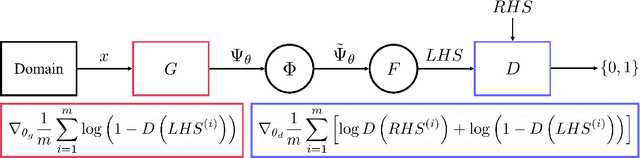
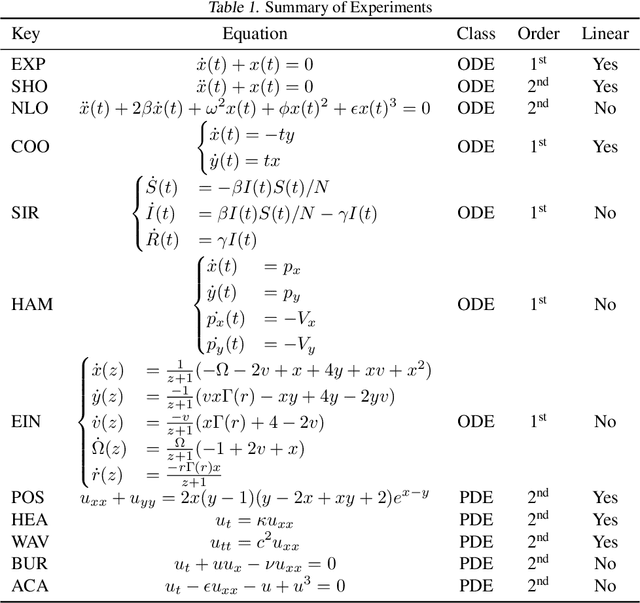
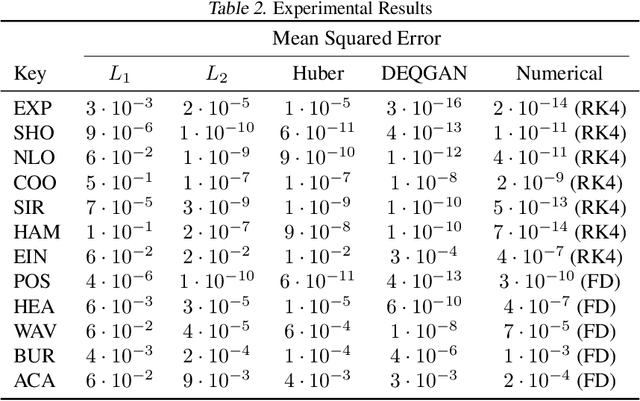
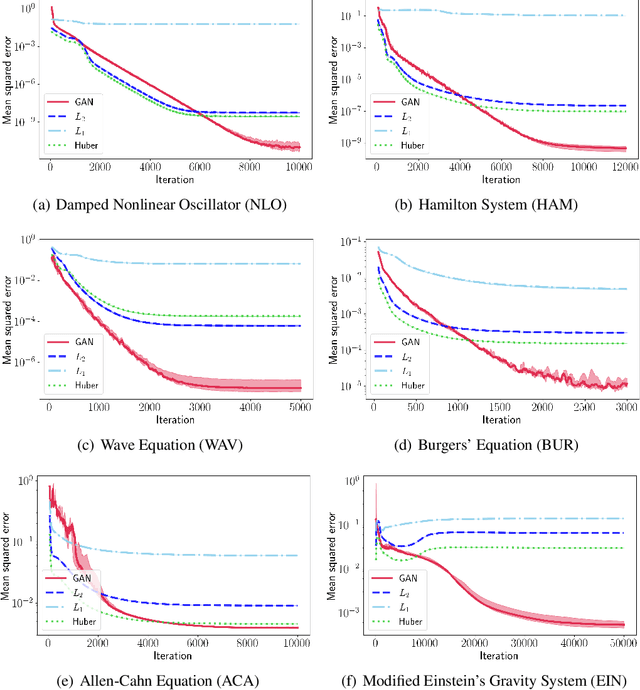
Solutions to differential equations are of significant scientific and engineering relevance. Physics-Informed Neural Networks (PINNs) have emerged as a promising method for solving differential equations, but they lack a theoretical justification for the use of any particular loss function. This work presents Differential Equation GAN (DEQGAN), a novel method for solving differential equations using generative adversarial networks to "learn the loss function" for optimizing the neural network. Presenting results on a suite of twelve ordinary and partial differential equations, including the nonlinear Burgers', Allen-Cahn, Hamilton, and modified Einstein's gravity equations, we show that DEQGAN can obtain multiple orders of magnitude lower mean squared errors than PINNs that use $L_2$, $L_1$, and Huber loss functions. We also show that DEQGAN achieves solution accuracies that are competitive with popular numerical methods. Finally, we present two methods to improve the robustness of DEQGAN to different hyperparameter settings.
RcTorch: a PyTorch Reservoir Computing Package with Automated Hyper-Parameter Optimization
Jul 12, 2022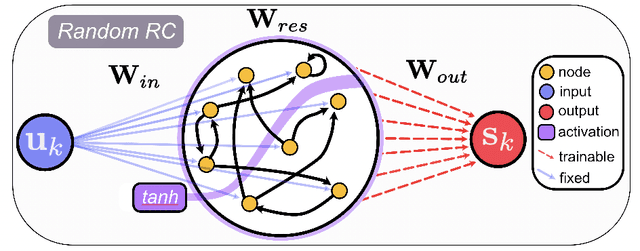
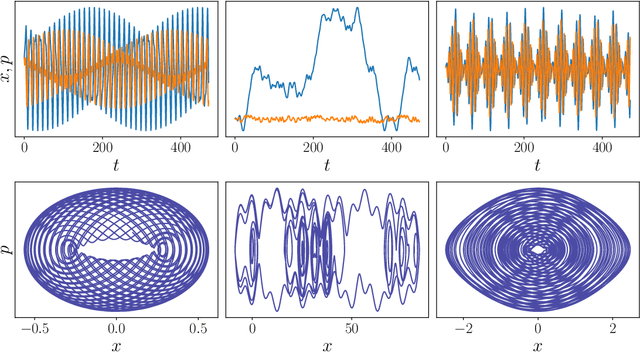
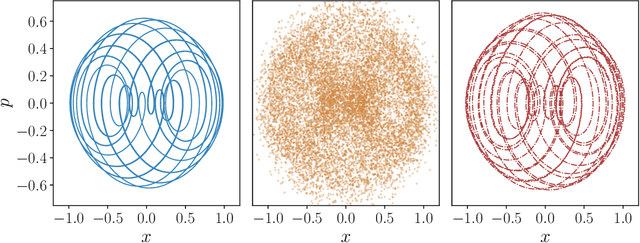
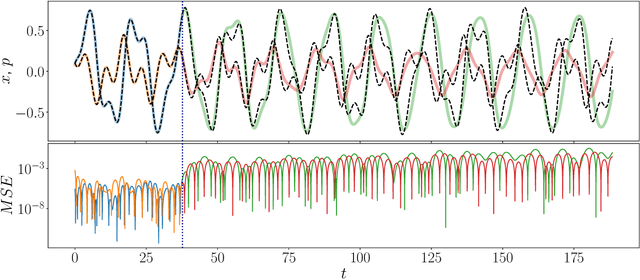
Reservoir computers (RCs) are among the fastest to train of all neural networks, especially when they are compared to other recurrent neural networks. RC has this advantage while still handling sequential data exceptionally well. However, RC adoption has lagged other neural network models because of the model's sensitivity to its hyper-parameters (HPs). A modern unified software package that automatically tunes these parameters is missing from the literature. Manually tuning these numbers is very difficult, and the cost of traditional grid search methods grows exponentially with the number of HPs considered, discouraging the use of the RC and limiting the complexity of the RC models which can be devised. We address these problems by introducing RcTorch, a PyTorch based RC neural network package with automated HP tuning. Herein, we demonstrate the utility of RcTorch by using it to predict the complex dynamics of a driven pendulum being acted upon by varying forces. This work includes coding examples. Example Python Jupyter notebooks can be found on our GitHub repository https://github.com/blindedjoy/RcTorch and documentation can be found at https://rctorch.readthedocs.io/.
Evaluating Error Bound for Physics-Informed Neural Networks on Linear Dynamical Systems
Jul 03, 2022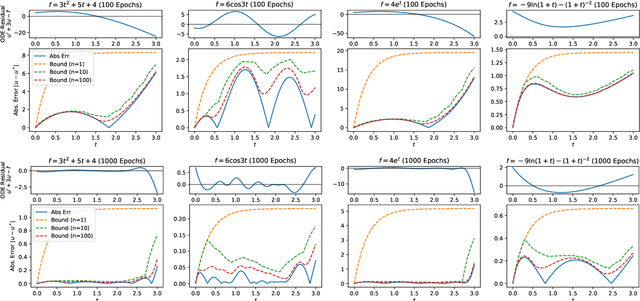
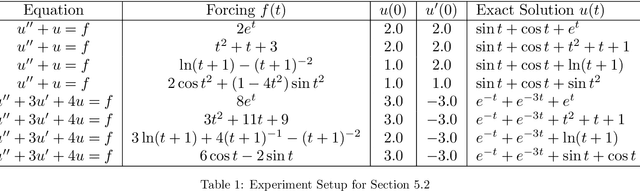
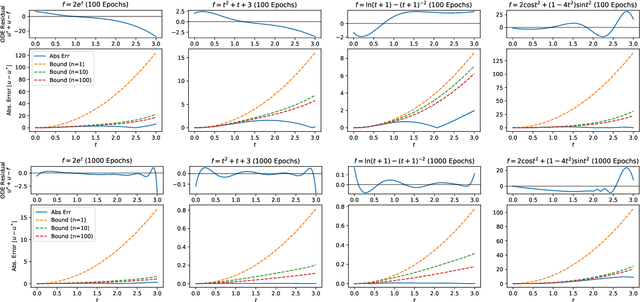

There have been extensive studies on solving differential equations using physics-informed neural networks. While this method has proven advantageous in many cases, a major criticism lies in its lack of analytical error bounds. Therefore, it is less credible than its traditional counterparts, such as the finite difference method. This paper shows that one can mathematically derive explicit error bounds for physics-informed neural networks trained on a class of linear systems of differential equations. More importantly, evaluating such error bounds only requires evaluating the differential equation residual infinity norm over the domain of interest. Our work shows a link between network residuals, which is known and used as loss function, and the absolute error of solution, which is generally unknown. Our approach is semi-phenomonological and independent of knowledge of the actual solution or the complexity or architecture of the network. Using the method of manufactured solution on linear ODEs and system of linear ODEs, we empirically verify the error evaluation algorithm and demonstrate that the actual error strictly lies within our derived bound.
Improving Astronomical Time-series Classification via Data Augmentation with Generative Adversarial Networks
May 13, 2022
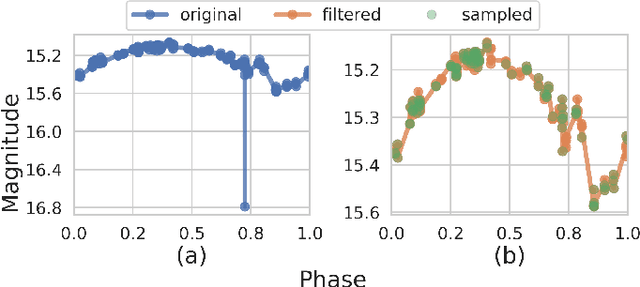
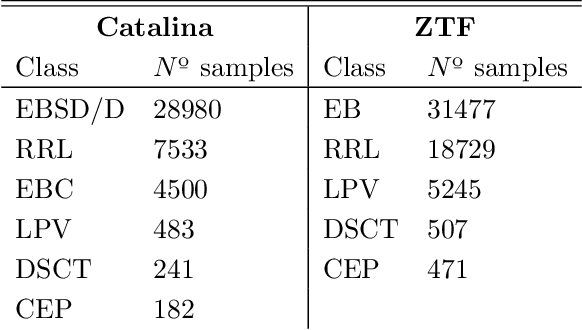
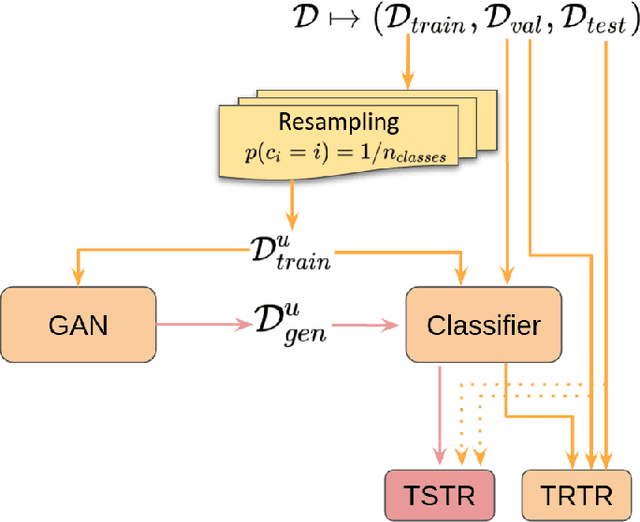
Due to the latest advances in technology, telescopes with significant sky coverage will produce millions of astronomical alerts per night that must be classified both rapidly and automatically. Currently, classification consists of supervised machine learning algorithms whose performance is limited by the number of existing annotations of astronomical objects and their highly imbalanced class distributions. In this work, we propose a data augmentation methodology based on Generative Adversarial Networks (GANs) to generate a variety of synthetic light curves from variable stars. Our novel contributions, consisting of a resampling technique and an evaluation metric, can assess the quality of generative models in unbalanced datasets and identify GAN-overfitting cases that the Fr\'echet Inception Distance does not reveal. We applied our proposed model to two datasets taken from the Catalina and Zwicky Transient Facility surveys. The classification accuracy of variable stars is improved significantly when training with synthetic data and testing with real data with respect to the case of using only real data.
Con$^{2}$DA: Simplifying Semi-supervised Domain Adaptation by Learning Consistent and Contrastive Feature Representations
Apr 04, 2022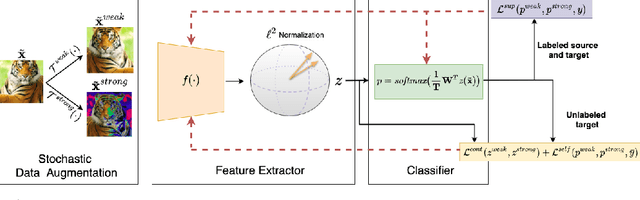
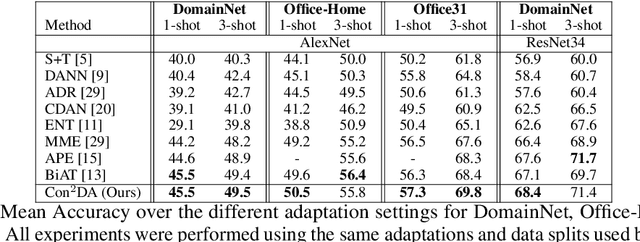
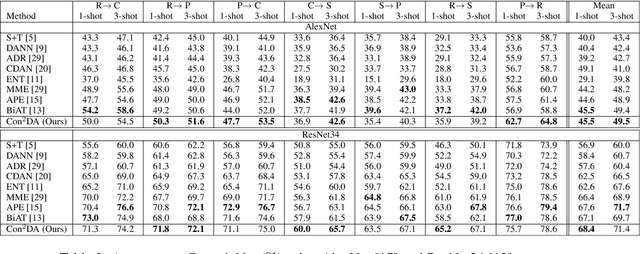
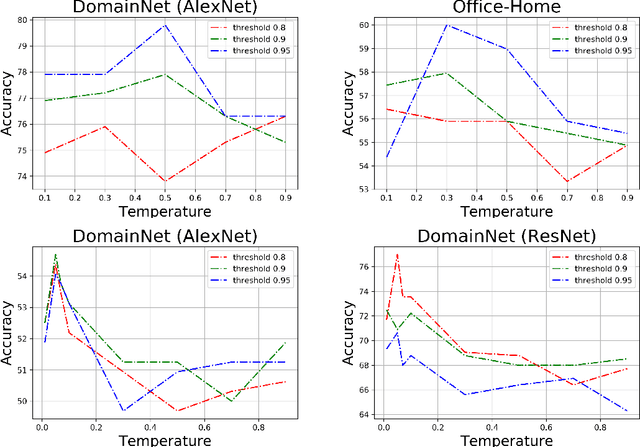
In this work, we present Con$^{2}$DA, a simple framework that extends recent advances in semi-supervised learning to the semi-supervised domain adaptation (SSDA) problem. Our framework generates pairs of associated samples by performing stochastic data transformations to a given input. Associated data pairs are mapped to a feature representation space using a feature extractor. We use different loss functions to enforce consistency between the feature representations of associated data pairs of samples. We show that these learned representations are useful to deal with differences in data distributions in the domain adaptation problem. We performed experiments to study the main components of our model and we show that (i) learning of the consistent and contrastive feature representations is crucial to extract good discriminative features across different domains, and ii) our model benefits from the use of strong augmentation policies. With these findings, our method achieves state-of-the-art performances in three benchmark datasets for SSDA.
* 11 pages, 3 figures, 4 tables